













炸!使用 MyBatis 查詢千萬數據量?
本文轉載自微信公眾號「源碼興趣圈」,作者馬稱 。轉載本文請聯系源碼興趣圈公眾號。
由于現在 ORM 框架的成熟運用,很多小伙伴對于 JDBC 的概念有些薄弱,ORM 框架底層其實是通過 JDBC 操作的 DB
JDBC(JavaDataBase Connectivity)是 Java 數據庫連接, 說的直白點就是使用 Java 語言操作數據庫
由 SUN 公司提供出一套訪問數據庫的規范 API, 并提供相對應的連接數據庫協議標準, 然后 各廠商根據規范提供一套訪問自家數據庫的 API 接口
文章大數據量操作核心圍繞 JDBC 展開,目錄結構如下:
- MySQL JDBC 大數據量操作
- 常規查詢
- 流式查詢
- 游標查詢
- JDBC RowData
- JDBC 通信原理
- 流式游標內存分析
- 單次調用內存使用
- 并發調用內存使用
- MyBatis 如何使用流式查詢
- 結言
MySql JDBC 大數據量操作
整篇文章以大數據量操作為議題,通過開發過程中的需求引出相關知識點
- 遷移數據
- 導出數據
- 批量處理數據
一般而言筆者認為在 Java Web 程序里,能夠被稱為大數據量的,幾十萬到千萬不等,再高的話 Java(WEB 應用)處理就不怎么合適了
舉個例子,現在業務系統需要從 MySQL 數據庫里讀取 500w 數據行進行處理,應該怎么做
- 常規查詢,一次性讀取 500w 數據到 JVM 內存中,或者分頁讀取
- 流式查詢,建立長連接,利用服務端游標,每次讀取一條加載到 JVM 內存
- 游標查詢,和流式一樣,通過 fetchSize 參數,控制一次讀取多少條數據
常規查詢
默認情況下,完整的檢索結果集會將其存儲在內存中。在大多數情況下,這是最有效的操作方式,并且由于 MySQL 網絡協議的設計,因此更易于實現
假設單表 500w 數據量,沒有人會一次性加載到內存中,一般會采用分頁的方式
- @SneakyThrows
- @Override
- public void pageQuery() {
- @Cleanup Connection conn = dataSource.getConnection();
- @Cleanup Statement stmt = conn.createStatement();
- long start = System.currentTimeMillis();
- long offset = 0;
- int size = 100;
- while (true) {
- String sql = String.format("SELECT COLUMN_A, COLUMN_B, COLUMN_C FROM YOU_TABLE LIMIT %s, %s", offset, size);
- @Cleanup ResultSet rs = stmt.executeQuery(sql);
- long count = loopResultSet(rs);
- if (count == 0) break;
- offset += size;
- }
- log.info(" 🚀🚀🚀 分頁查詢耗時 :: {} ", System.currentTimeMillis() - start);
- }
上述方式比較簡單,但是在不考慮 LIMIT 深分頁優化情況下,線上數據庫服務器就涼了,亦或者你能等個幾天時間檢索數據
流式查詢
如果你正在使用具有大量數據行的 ResultSet,并且無法在 JVM 中為其分配所需的內存堆空間,則可以告訴驅動程序從結果流中返回一行

流式查詢有一點需要注意:必須先讀取(或關閉)結果集中的所有行,然后才能對連接發出任何其他查詢,否則將引發異常
使用流式查詢,則要保持對產生結果集的語句所引用的表的并發訪問,因為其 查詢會獨占連接,所以必須盡快處理
- @SneakyThrows
- public void streamQuery() {
- @Cleanup Connection conn = dataSource.getConnection();
- @Cleanup Statement stmt = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
- stmt.setFetchSize(Integer.MIN_VALUE);
- long start = System.currentTimeMillis();
- @Cleanup ResultSet rs = stmt.executeQuery("SELECT COLUMN_A, COLUMN_B, COLUMN_C FROM YOU_TABLE");
- loopResultSet(rs);
- log.info(" 🚀🚀🚀 流式查詢耗時 :: {} ", (System.currentTimeMillis() - start) / 1000);
- }
流式查詢庫表數據量 500w 單次調用時間消耗:≈ 6s
游標查詢
SpringBoot 2.x 版本默認連接池為 HikariPool,連接對象是 HikariProxyConnection,所以下述設置游標方式就不可行了
- ((JDBC4Connection) conn).setUseCursorFetch(true);
需要在數據庫連接信息里拼接 &useCursorFetch=true。其次設置 Statement 每次讀取數據數量,比如一次讀取 1000
- @SneakyThrows
- public void cursorQuery() {
- @Cleanup Connection conn = dataSource.getConnection();
- @Cleanup Statement stmt = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
- stmt.setFetchSize(1000);
- long start = System.currentTimeMillis();
- @Cleanup ResultSet rs = stmt.executeQuery("SELECT COLUMN_A, COLUMN_B, COLUMN_C FROM YOU_TABLE");
- loopResultSet(rs);
- log.info(" 🚀🚀🚀 游標查詢耗時 :: {} ", (System.currentTimeMillis() - start) / 1000);
- }
游標查詢庫表數據量 500w 單次調用時間消耗:≈ 18s
JDBC RowData
上面都使用到了方法 loopResultSet,方法內部只是進行了 while 循環,常規、流式、游標查詢的核心點在于 next 方法
- @SneakyThrows
- private Long loopResultSet(ResultSet rs) {
- while (rs.next()) {
- // 業務操作
- }
- return xx;
- }
ResultSet.next() 的邏輯是實現類 ResultSetImpl 每次都從 RowData 獲取下一行的數據。RowData 是一個接口,實現關系圖如下
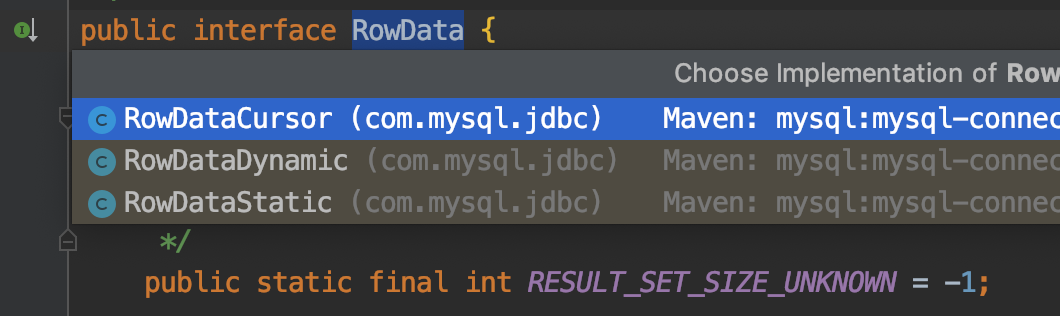
默認情況下 ResultSet 會使用 RowDataStatic 實例,在生成 RowDataStatic 對象時就會把 ResultSet 中所有記錄讀到內存里,之后通過 next() 再一條條從內存中讀
RowDataCursor 的調用為批處理,然后進行內部緩存,流程如下:
- 首先會查看自己內部緩沖區是否有數據沒有返回,如果有則返回下一行
- 如果都讀取完畢,向 MySQL Server 觸發一個新的請求讀取 fetchSize 數量結果
- 并將返回結果緩沖到內部緩沖區,然后返回第一行數據
當采用流式處理時,ResultSet 使用的是 RowDataDynamic 對象,而這個對象 next() 每次調用都會發起 IO 讀取單行數據
總結來說就是,默認的 RowDataStatic 讀取全部數據到客戶端內存中,也就是我們的 JVM;RowDataCursor 一次讀取 fetchSize 行,消費完成再發起請求調用;RowDataDynamic 每次 IO 調用讀取一條數據
JDBC 通信原理
普通查詢
在 JDBC 與 MySQL 服務端的交互是通過 Socket 完成的,對應到網絡編程,可以把 MySQL 當作一個 SocketServer,因此一個完整的請求鏈路應該是:
JDBC 客戶端 -> 客戶端 Socket -> MySQL -> 檢索數據返回 -> MySQL 內核 Socket 緩沖區 -> 網絡 -> 客戶端 Socket Buffer -> JDBC 客戶端
普通查詢的方式在查詢大數據量時,所在 JVM 可能會涼涼,原因如下:
- MySQL Server 會將檢索出的 SQL 結果集通過輸出流寫入到內核對應的 Socket Buffer
- 內核緩沖區通過 JDBC 發起的 TCP 鏈路進行回傳數據,此時數據會先進入 JDBC 客戶端所在內核緩沖區
- JDBC 發起 SQL 操作后,程序會被阻塞在輸入流的 read 操作上,當緩沖區有數據時,程序會被喚醒進而將緩沖區數據讀取到 JVM 內存中
- MySQL Server 會不斷發送數據,JDBC 不斷讀取緩沖區數據到 Java 內存中,雖然此時數據已到 JDBC 所在程序本地,但是 JDBC 還沒有對 execute 方法調用處進行響應,因為需要等到對應數據讀取完畢才會返回
- 弊端就顯而易見了,如果查詢數據量過大,會不斷經歷 GC,然后就是內存溢出
游標查詢
通過上文得知,游標可以解決普通查詢大數據量的內存溢出問題,但是
小伙伴有沒有思考過這么一個問題,MySQL 不知道客戶端程序何時消費完成,此時另一連接對該表造成 DML 寫入操作應該如何處理?
其實,在我們使用游標查詢時,MySQL 需要建立一個臨時空間來存放需要被讀取的數據,所以不會和 DML 寫入操作產生沖突
但是游標查詢會引發以下現象:
- IOPS 飆升,因為需要返回的數據需要寫入到臨時空間中,存在大量的 IO 讀取和寫入,此流程可能會引起其它業務的寫入抖動
- 磁盤空間飆升,因為寫入臨時空間的數據是在原表之外的,如果表數據過大,極端情況下可能會導致數據庫磁盤寫滿,這時網絡輸出時沒有變化的。而寫入臨時空間的數據會在 讀取完成或客戶端發起 ResultSet#close 操作時由 MySQL 回收
- 客戶端 JDBC 發起 SQL 查詢,可能會有長時間等待 SQL 響應,這段時間為服務端準備數據階段。但是 普通查詢等待時間與游標查詢等待時間原理上是不一致的,前者是一致在讀取網絡緩沖區的數據,沒有響應到業務層面;后者是 MySQL 在準備臨時數據空間,沒有響應到 JDBC
- 數據準備完成后,進行到傳輸數據階段,網絡響應開始飆升,IOPS 由"讀寫"轉變為"讀取"
采用游標查詢的方式 通信效率比較低,因為客戶端消費完 fetchSize 行數據,就需要發起請求到服務端請求,在數據庫前期準備階段 IOPS 會非常高,占用大量的磁盤空間以及性能
流式查詢
當客戶端與 MySQL Server 端建立起連接并且交互查詢時,MySQL Server 會通過輸出流將 SQL 結果集返回輸出,也就是 向本地的內核對應的 Socket Buffer 中寫入數據,然后將內核中的數據通過 TCP 鏈路回傳數據到 JDBC 對應的服務器內核緩沖區
- JDBC 通過輸入流 read 方法去讀取內核緩沖區數據,因為開啟了流式讀取,每次業務程序接收到的數據只有一條
- MySQL 服務端會向 JDBC 代表的客戶端內核源源不斷的輸送數據,直到客戶端請求 Socket 緩沖區滿,這時的 MySQL 服務端會阻塞
- 對于 JDBC 客戶端而言,數據每次讀取都是從本機器的內核緩沖區,所以性能會更快一些,一般情況不必擔心本機內核無數據消費(除非 MySQL 服務端傳遞來的數據,在客戶端不做任何業務邏輯,拿到數據直接放棄,會發生客戶端消費比服務端超前的情況)
看起來,流式要比游標的方式更好一些,但是事情往往不像表面上那么簡單
- 相對于游標查詢,流式對數據庫的影響時間要更長一些
- 另外流式查詢依賴網絡,導致網絡擁塞可能性較大
流式游標內存分析
表數據量:500w
內存查看工具:JDK 自帶 Jvisualvm
設置 JVM 參數:-Xmx512m -Xms512m
單次調用內存使用
流式查詢內存性能報告如下
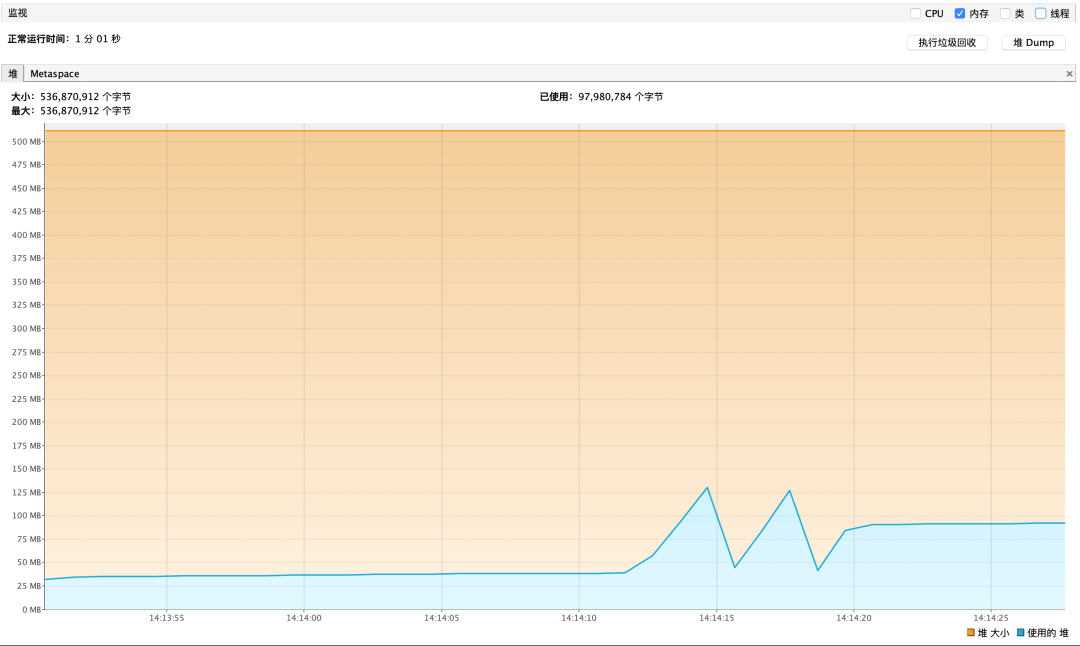
圖1 數據僅供參考
游標查詢內存性能報告如下
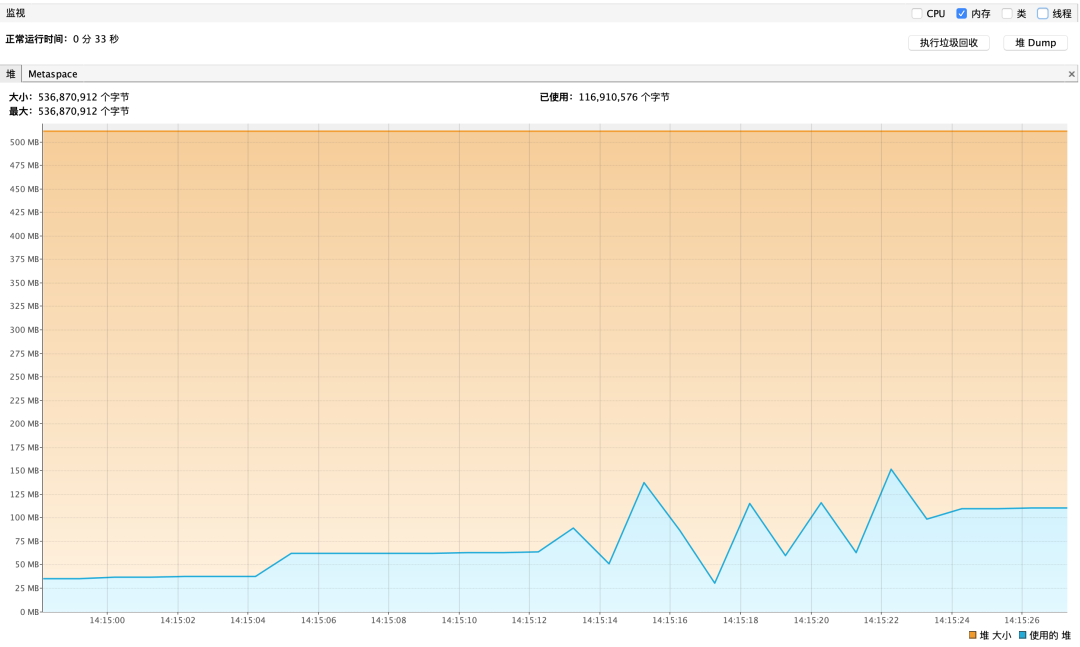
圖2 數據僅供參考
根據內存占用情況來看,游標查詢和流式查詢都 能夠很好的防止 OOM
并發調用內存使用
并發調用:Jmete 1 秒 10 個線程并發調用
流式查詢內存性能報告如下
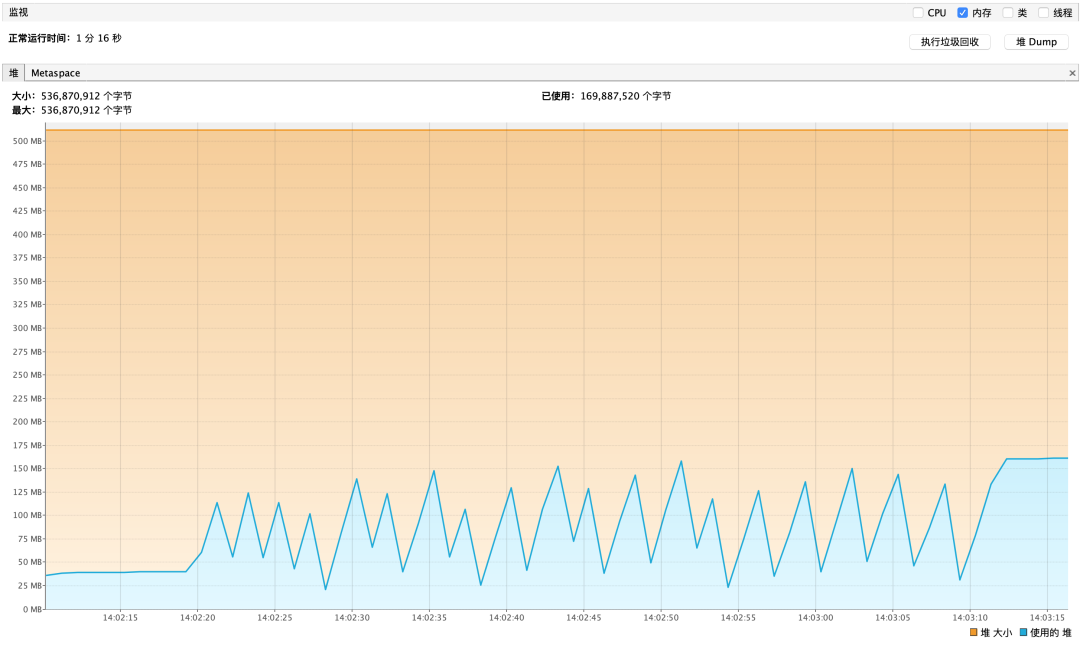
圖3 數據僅供參考
并發調用對于內存占用情況也很 OK,不存在疊加式增加
流式查詢并發調用時間平均消耗:≈ 55s
游標查詢內存性能報告如下
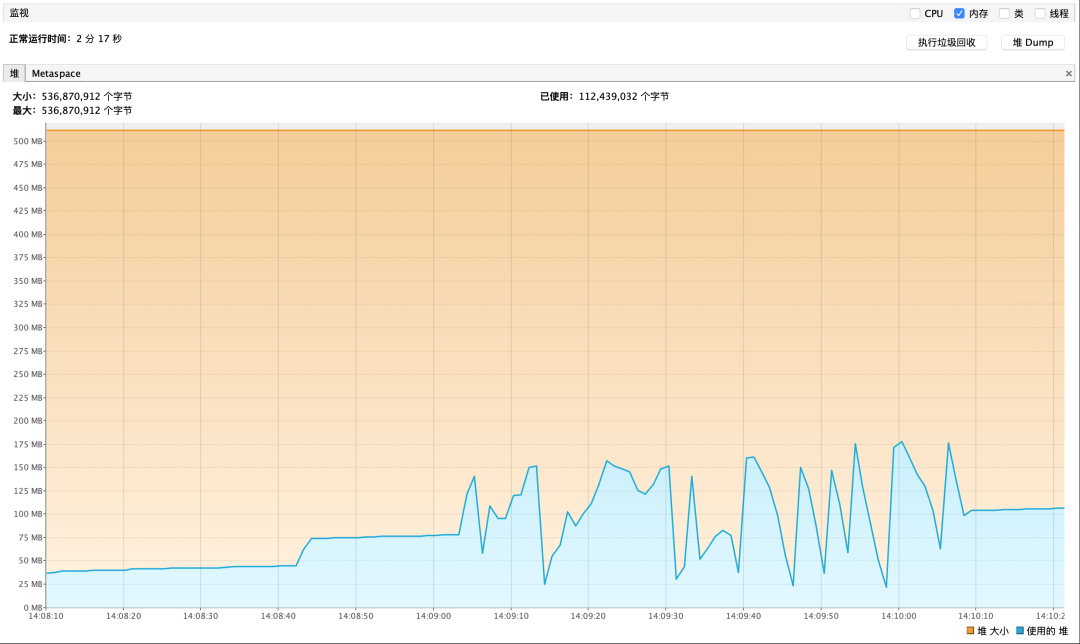
圖4 數據僅供參考
游標查詢并發調用時間平均消耗:≈ 83s
因為設備限制,以及部分情況只會在極端下產生,所以沒有進行生產、測試多環境驗證,小伙伴感興趣可以自行測試
MyBatis 如何使用流式查詢
上文都是在描述如何使用 JDBC 原生 API 進行查詢,ORM 框架 Mybatis 也針對流式查詢進行了封裝
ResultHandler 接口只包含 handleResult 方法,可以獲取到已轉換后的 Java 實體類
- @Slf4j
- @Service
- public class MyBatisStreamService {
- @Resource
- private MyBatisStreamMapper myBatisStreamMapper;
- public void mybatisStreamQuery() {
- long start = System.currentTimeMillis();
- myBatisStreamMapper.mybatisStreamQuery(new ResultHandler<YOU_TABLE_DO>() {
- @Override
- public void handleResult(ResultContext<? extends YOU_TABLE_DO> resultContext) { }
- });
- log.info(" 🚀🚀🚀 MyBatis查詢耗時 :: {} ", System.currentTimeMillis() - start);
- }
- }
除了下述注解式的應用方式,也可以使用 .xml 文件的形式
- @Mapper
- public interface MyBatisStreamMapper {
- @Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = Integer.MIN_VALUE)
- @ResultType(YOU_TABLE_DO.class)
- @Select("SELECT COLUMN_A, COLUMN_B, COLUMN_C FROM YOU_TABLE")
- void mybatisStreamQuery(ResultHandler<YOU_TABLE_DO> handler);
- }
Mybatis 流式查詢調用時間消耗:≈ 18s
- JDBC 流式與 MyBatis 封裝的流式讀取對比
- MyBatis 相對于原生的流式還是慢上了不少,但是考慮到底層的封裝的特性,這點性能還是可以接受的
- 從內存占比而言,兩者波動相差無幾
MyBatis 相對于原生 JDBC 更為的方便,因為封裝了回調函數以及序列化對象等特性
兩者具體的使用,可以針對項目實際情況而定,沒有最好的,只有最適合的
結言
流式查詢、游標查詢可以避免 OOM,數據量大可以考慮此方案。但是這兩種方式會占用數據庫連接,使用中不會釋放,所以線上針對大數據量業務用到游標和流式操作,一定要進行并發控制
另外針對 JDBC 原生流式查詢,Mybatis 中也進行了封裝,雖然會慢一些,但是 功能以及代碼的整潔程度會好上不少
作者馬稱,坐標帝都 Java 后端研發,專注高并發、分布式、框架底層源碼等知識分享


















