如何在萬億級別規模的數據量上使用 Spark?
一、前言
Spark 作為大數據計算引擎,憑借其快速、穩定、簡易等特點,快速的占領了大數據計算的領域。本文主要為作者在搭建使用計算平臺的過程中,對于 Spark 的理解,希望能給讀者一些學習的思路。文章內容為介紹 Spark 在 DataMagic 平臺扮演的角色、如何快速掌握 Spark 以及 DataMagic 平臺是如何使用好 Spark 的。
二、Spark 在 DataMagic 平臺中的角色
整套架構的主要功能為日志接入、查詢 (實時和離線)、計算。離線計算平臺主要負責計算這一部分,系統的存儲用的是 COS(公司內部存儲),而非 HDFS。
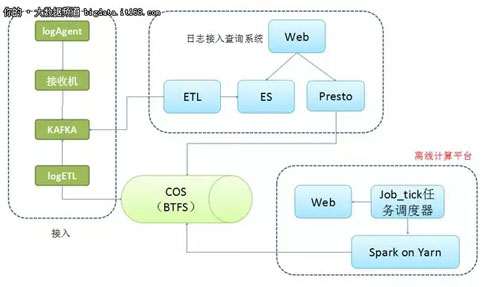
圖 2-1
下面將主要介紹 Spark on Yarn 這一架構,抽取出來即圖 2-2 所示,可以看到 Spark on yarn 的運行流程。
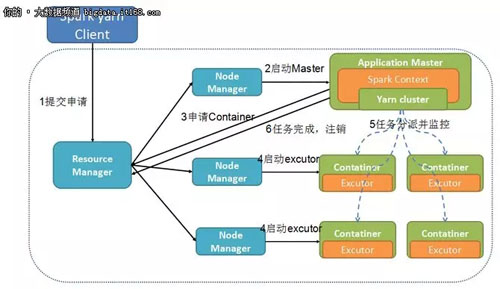
圖 2-2
三、如何快速掌握 Spark
對于理解 Spark,我覺得掌握下面 4 個步驟就可以了。
1. 理解 Spark 術語
對于入門,學習 Spark 可以通過其架構圖,快速了解其關鍵術語,掌握了關鍵術語,對 Spark 基本上就有認識了,分別是結構術語 Shuffle、Patitions、MapReduce、Driver、Application Master、Container、Resource Manager、Node Manager 等。API 編程術語關鍵 RDD、DataFrame,結構術語用于了解其運行原理,API 術語用于使用過程中編寫代碼,掌握了這些術語以及背后的知識,你就也知道 Spark 的運行原理和如何編程了。
2. 掌握關鍵配置
Spark 在運行的時候,很多運行信息是通過配置文件讀取的,一般在 spark-defaults.conf,要把 Spark 使用好,需要掌握一些關鍵配置,例如跟運行內存相關的,spark.yarn.executor.memoryOverhead、spark.executor.memory,跟超時相關的 spark.network.timeout 等等,Spark 很多信息都可以通過配置進行更改,因此對于配置需要有一定的掌握。但是使用配置時,也要根據不同的場景,這個舉個例子,例如 spark.speculation 配置,這個配置主要目的是推測執行,當 worker1 執行慢的情況下,Spark 會啟動一個 worker2,跟 worker1 執行相同的任務,誰先執行完就用誰的結果,從而加快計算速度,這個特性在一般計算任務來說是非常好的,但是如果是執行一個出庫到 Mysql 的任務時,同時有兩個一樣的 worker,則會導致 Mysql 的數據重復。因此我們在使用配置時,一定要理解清楚,直接 google spark conf 就會列出很多配置了。
3. 使用好 Spark 的并行
我們之所以使用 Spark 進行計算,原因就是因為它計算快,但是它快的原因很大在于它的并行度,掌握 Spark 是如何提供并行服務的,從而是我們更好的提高并行度。
對于提高并行度,對于 RDD,需要從幾個方面入手,1、配置 num-executor。2、配置 executor-cores。3、配置 spark.default.parallelism。三者之間的關系一般為 spark.default.parallelism=num-executors*executor-cores 的 2~3 倍較為合適。對于 Spark-sql,則設置 spark.sql.shuffle.partitions、num-executor 和 executor-cores。
4. 學會如何修改 Spark 代碼
新手而言,特別是需要對 Spark 進行優化或者修改時,感到很迷茫,其實我們可以首先聚焦于局部,而 Spark 確實也是模塊化的,不需要覺得 Spark 復雜并且難以理解,我將從修改 Spark 代碼的某一角度來進行分析。
首先,Spark 的目錄結構如圖 3-1 所示,可以通過文件夾,快速知道 sql、graphx 等代碼所在位置,而 Spark 的運行環境主要由 jar 包支撐,如圖 3-2 所示,這里截取部分 jar 包,實際上遠比這多,所有的 jar 包都可以通過 Spark 的源代碼進行編譯,當需要修改某個功能時,僅需要找到相應 jar 包的代碼,修改之后,編譯該 jar 包,然后進行替換就行了。

圖 3-1
圖 3-2
而對于編譯源代碼這塊,其實也非常簡單,安裝好 maven、scala 等相關依賴,下載源代碼進行編譯即可,掌握修改源碼技巧對于使用好開源項目十分重要。
四、DataMagic 平臺中的 Spark
Spark 在 DataMagic 中使用,也是在邊使用邊探索的過程,在這過程中,列舉了其比較重要的特點。
1. 快速部署
在計算中,計算任務的數量以及數據的量級每天都會發生變化,因此對于 Spark 平臺,需要有快速部署的特性,在實體機上,有一鍵部署腳本,只要運行一個腳本,則可以馬上上線一個擁有 128G 內存、48cores 的實體機,但是實體機通常需要申請報備才能獲得,因此還會有 docker 來支持計算資源。
2. 巧用配置優化計算
Spark 大多數屬性都是通過配置來實現的,因此可以通過配置動態修改 Spark 的運行行為,這里舉個例子,例如通過配置自動調整 exector 的數量。
2.1 在 nodeManager 的 yarn-site.xml 添加配置
yarn.nodemanager.aux-services
mapreduce_shuffle,spark_shuffle
yarn.nodemanager.aux-services.spark_shuffle.class
org.apache.spark.network.yarn.YarnShuffleService
2.2 將 spark-2.2.0-yarn-shuffle.jar 文件拷貝到 hadoop-yarn/lib 目錄下 (即 yarn 的庫目錄)
2.3 在 Spark 的 spark-default.xml 添加配置
spark.dynamicAllocation.minExecutors 1 #最小 Executor 數
spark.dynamicAllocation.maxExecutors 100 #*** Executor 數
通過這種配置,可以達到自動調整 exector 的目的。
3. 合理分配資源
作為一個平臺,其計算任務肯定不是固定的,有的數據量多,有的數據量少,因此需要合理分配資源,例如有些千萬、億級別的數據,分配 20 核計算資源就足夠了。但是有些數據量級達到百億的,就需要分配更多的計算資源了。參考第三章節的第 3 點。
4. 貼合業務需求
計算的目的其實就是為了服務業務,業務的需求也理應是平臺的追求,當業務產生合理需求時,平臺方也應該盡量去滿足。如為了支持業務高并發、高實時性查詢的需求下,Spark 在數據出庫方式上,支持了 Cmongo 的出庫方式。
sc = SparkContext(conf=conf) sqlContext = SQLContext(sc) database = d = dict((l.split('=') for l in dbparameter.split())) parquetFile = sqlContext.read.parquet(file_name) parquetFile.registerTempTable(tempTable) result = sqlContext.sql(sparksql) url = "mongodb://"+database['user']+":"+database['password']+"@"+database['host']+":"+database['port'] result.write.format("com.mongodb.spark.sql").mode('overwrite').options(uri=url,database=database['dbname'],collection=pg_table_name).save()
5. 適用場景
Spark 作為通用的計算平臺,在普通的應用的場景下,一般而言是不需要額外修改的,但是 DataMagic 平臺上,我們需要 “在前行中改變”。這里舉個簡單的場景,在日志分析中,日志的量級達到千億 / 日的級別,當底層日志的某些字段出現 utf-8 編碼都解析不了的時候,在 Spark 任務中進行計算會發生異常,然后失敗,然而如果在數據落地之前對亂碼數據進行過濾,則有可能會影響數據采集的效率,因此最終決定在 Spark 計算過程中解決中這個問題,因此在 Spark 計算時,對數據進行轉換的代碼處加上異常判斷來解決該問題。
6.Job 問題定位
Spark 在計算任務失敗時候,需要去定位失敗原因,當 Job 失敗是,可以通過 yarn logs -applicationId application 來合并任務 log,打開 log,定位到 Traceback,一般可以找到失敗原因。一般而言,失敗可以分成幾類。
a. 代碼問題,寫的 Sql 有語法問題,或者 Spark 代碼有問題。
b. Spark 問題,舊 Spark 版本處理 NULL 值等。
c. 任務長時間 Running 狀態,則可能是數據傾斜問題。
d. 任務內存越界問題。
7. 集群管理
Spark 集群在日常使用中,也是需要運營維護的,從而運營維護,發現其存在的問題,不斷的對集群進行優化,這里從以下幾個方面進行介紹,通過運營手段來保障集群的健壯性和穩定性,保證任務順利執行。
a. 定時查看是否有 lost node 和 unhealthy node,可以通過腳本來定時設置告警,若存在,則需要進行定位處理。
b. 定時掃描 hdfs 的運行 log 是否滿了,需要定時刪除過期 log。
c. 定時掃描集群資源是否滿足計算任務使用,能夠提前部署資源。
五、總結
本文主要是通過作者在搭建使用計算平臺的過程中,寫出對于 Spark 的理解,并且介紹了 Spark 在當前的 DataMagic 是如何使用的,當前平臺已經用于架平離線分析,每天計算分析的數據量已經達到千億~ 萬億級別。