寫入數據量增加時,如何實現分庫分表?
在高并發場景下,為提升數據庫性能和安全性,常采用讀寫分離的優化方案。這種方法利用主從復制技術,將數據復制為多份,從而提升對大量并發讀請求的處理能力,增強數據庫的查詢性能。同時,通過在多個節點中存儲完整數據,進一步保障數據的安全性。當某個數據庫節點(主庫或從庫)發生故障時,系統仍能依賴其他節點的完整數據來保證數據的可用性,不會造成數據丟失。
在電商系統中引入讀寫分離后,架構示例如下:
- 主庫:負責所有寫操作(如新增、更新、刪除等),并將數據同步至多個從庫。
- 從庫:專用于處理讀操作,從而分擔主庫的查詢壓力。
- 負載均衡:在處理讀請求時,系統將流量分配至不同的從庫節點,以提高查詢性能。
- 故障恢復:若某個節點宕機,系統仍能利用其他節點的數據來提供正常服務。
 圖片
圖片
在電商系統的訂單量突破五千萬后,盡管流量的提升是好消息,但也帶來了前所未有的數據庫壓力。現有的單表存儲方式難以承載如此龐大的數據量,查詢和寫入性能都在下降,且磁盤空間告警頻發。為保證系統正常運轉,我分析了當前面臨的主要問題,并尋求相應的解決方案。
1. 查詢性能問題
系統正在持續擴展,用戶和訂單數據迅速增長,導致數據庫單表數據量突破千萬甚至億級別。這時,即便使用了索引,隨著數據量的增加,索引占用的空間也逐漸增大。當數據庫無法緩存全量索引信息時,查詢便需要頻繁從磁盤讀取索引數據,從而降低查詢性能。
解決方案:優化查詢性能的關鍵在于減少索引的壓力。一種方法是對數據進行分片,將數據按一定規則分散到多個表或庫中,縮小單個表的索引范圍。此外,也可考慮將查詢請求引導至專門的從庫,進一步分攤主庫壓力。
2. 數據量增長引發的存儲問題
隨著訂單數據的持續增加,數據庫的磁盤空間消耗加劇,備份和恢復時間變長,給系統帶來了存儲和恢復的雙重壓力。
解決方案:為了讓數據庫支持大規模數據量,可以采用分庫分表策略,將數據分散存儲到不同的物理庫中,緩解單機磁盤存儲的瓶頸。這不僅減少了備份時間,也縮短了數據恢復時間,從而保障系統的高可用性。
3. 模塊故障隔離問題
當前系統中,不同模塊的數據(如用戶數據和用戶關系數據)都存儲在同一個主庫中。一旦主庫發生故障,所有模塊的服務都會受到影響。
解決方案:為實現模塊的故障隔離,可以對不同模塊的數據進行邏輯分庫,將各模塊的數據分散到不同的數據庫實例中。這樣,即便某個模塊的數據庫出現問題,其他模塊依然能夠正常運行,增強了系統的魯棒性。
4. 高并發寫入帶來的性能瓶頸
基于測試數據,當前在 4 核 8G 的云服務器上,MySQL 5.7 的寫入性能(約 500 TPS)遠低于查詢性能(約 10000 QPS)。隨著系統寫入請求量的增加,寫入壓力日益加重,單一數據庫實例難以支撐更高的并發寫入。
解決方案:為解決高并發寫入問題,分庫分表是一種有效手段。通過將數據水平切分到多個數據庫實例或表中,分攤數據庫的寫入壓力,提升整體并發寫入能力,突破單機存儲和性能瓶頸。
總結來看,上述問題主要歸結為數據庫的寫入壓力和可用性問題。采用數據分片策略,進行合理的“分庫分表”設計,可以有效緩解這些問題,提升系統的整體性能和可用性。
分庫分表是一個很常見的技術方案,你應該有所了解。那你會說了:“既然這個技術很普遍,而我又有所了解,那你為什么還要提及這個話題呢?”因為以我過往的經驗來看,不少人會在“分庫分表”這里踩坑,主要體現在:1. 對如何使用正確的分庫分表方式一知半解,沒有明白使用場景和方法。比如,一些同學會在查詢時不使用分區鍵;2. 分庫分表引入了一些問題后,沒有找到合適的解決方案。比如,會在查詢時使用大量連表查詢等等。
如何對數據庫做垂直拆分
分庫分表是一種常見的數據分片方式,其核心思想是通過一定策略將數據盡可能均勻地分布在多個數據庫節點或表中。這種方式不同于主從復制,后者將數據全量復制到多個節點,而分庫分表則是讓每個節點只保存部分數據,從而有效減少了單個數據庫節點和表中的數據量。這不僅解決了存儲瓶頸問題,還大幅提升了數據查詢性能。
此外,數據被分散到多個節點后,寫入請求也不再集中在單一主庫,而是分散到多個數據分片節點上,增強了并發寫入的能力。比如,在我曾負責的一個直播項目中,我們需要存儲用戶和系統在直播間的消息。熱門直播間的留言量常常上萬,長期積累下來,數據量達到了數億級別,查詢性能和存儲空間都難以承受。為此,我們不得不重構系統,通過分庫分表來分攤寫入和存儲壓力。項目中我們啟動了多個數據庫并完成了單庫數據的遷移和分片校驗,這項工作雖然耗時費力,但最終成功地提升了系統的穩定性和效率。
數據庫分庫分表的方式主要有兩種:垂直拆分和水平拆分。掌握拆分方式的應用場景是關鍵,而理解其原理是掌握數據分片的核心。在學習時,最好結合自身的業務需求,思考如何更有效地進行拆分。
垂直拆分
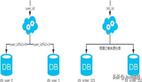
垂直拆分,顧名思義,是將數據庫“豎著”拆分,即按照業務類型將表分配到不同的數據庫中。其核心理念是專庫專用,將耦合度較高的表放在同一個庫中。可以把垂直拆分類比為整理衣物:把羽絨服、毛衣、T恤分別放入不同的格子中。這種方式能夠有效解決數據層面的故障隔離問題。例如,當某一模塊的數據庫發生故障時,影響的僅是該模塊的功能,而不會波及其他模塊的功能。
我還是以微博系統為例來給你說明一下。
在微博系統中有和用戶相關的表,有和內容相關的表,有和關系相關的表,這些表都存儲在主庫中。在拆分后,我們期望用戶相關的表分拆到用戶庫中,內容相關的表分拆到內容庫中,關系相關的表分拆到關系庫中。
 圖片
圖片
對數據庫進行垂直拆分是一種較為常規的處理方式,且在實際業務中較為常見。垂直拆分后,雖然能暫時緩解數據庫在存儲容量上的瓶頸,但這并不意味著問題完全解決。垂直拆分只能在一定程度上減少存儲壓力,但它并不能應對單個業務模塊數據量劇增的情況。
當某一業務庫數據量暴增時,比如在微博系統中,用戶關系數據已達到千億級別,單個數據庫或數據表遠遠無法滿足存儲和查詢需求。這時,僅僅依賴垂直拆分是不夠的,你還需要進一步將數據拆分到多個數據庫和數據表中。這種方法就是水平拆分,用來應對單表或單庫內數據量過大的問題。
水平拆分可以有效地將數據分布在多個數據庫和表中,從而進一步提升系統的擴展性和查詢性能。
如何對數據庫做水平拆分
拆分的規則有下面這兩種:
一種常見的水平拆分方法是基于某個字段的哈希值進行分片,這種方法尤其適用于實體表,如用戶表、內容表等。通常,我們會選擇這些表的 ID 字段作為拆分依據。
例如,假設需要將用戶表拆分為 16 個庫,每個庫下有 64 張表。具體步驟如下:
- 計算哈希值:先對用戶 ID 進行哈希處理,將 ID 值盡量打散以便均勻分布。
- 確定分庫索引:將哈希值對 16 取余,得到分庫的索引值。
- 確定分表索引:再將哈希值對 64 取余,得出分表的索引值。
通過這種方式,數據被均勻地分配到多個庫和表中,從而減輕了單一庫和表的存儲與查詢壓力

另一種常用的水平拆分方式是基于某個字段的區間進行拆分,通常選擇時間字段來劃分。例如,在內容表中有“創建時間”字段,我們常常需要根據時間查看某人發布的內容,可能是昨天的內容,也可能是一個月前的內容。
在這種場景下,可以按照創建時間的區間進行分庫分表。例如,將一個月的數據放在一張表中,這樣在查詢時,可以先根據創建時間快速定位數據所在的表,然后再根據其他查詢條件獲取數據。這種方式特別適合列表型數據的存儲,比如用戶在一段時間內的訂單或發布的內容。
不過,這種區間劃分方法也有可能導致熱點問題。因為用戶通常會更關注近期的內容或訂單,因此查詢最新數據的請求會更多,從而對系統性能造成一定壓力。
此外,這種方式還要求提前創建好數據表。否則,如果到了2020年元旦,數據庫管理員(DBA)忘記建立新的表,就會導致2020年數據無表可寫,進而引發故障。因此,做好表的提前規劃和維護非常重要。
 圖片
圖片
數據庫在分庫分表之后,數據的訪問方式也有了極大的改變,原先只需要根據查詢條件到從庫中查詢數據即可,現在則需要先確認數據在哪一個庫表中,再到那個庫表中查詢數據。這種復雜度也可以通過數據庫中間件來解決,我們在08 講中已經有所講解,這里就不再贅述了,不過,我想再次強調的是,你需要對所使用數據庫中間件的原理有足夠的了解,和足夠強的運維上的把控能力。不過,你要知道的是,分庫分表雖然能夠解決數據庫擴展性的問題,但是它也給我們的使用帶來了一些問題。
解決分庫分表引入的問題
分庫分表帶來的一個主要問題是分庫分表鍵(也稱為分區鍵)的引入,即對數據庫進行分庫分表時所依據的字段。無論是通過哈希分片還是區間分片,首先都需要選擇一個字段作為分區鍵。然而,這也帶來了一個限制:之后的所有查詢都必須包含該分區鍵才能找到數據所在的庫和表。否則,查詢將不得不遍歷所有庫和表。
例如,如果我們將數據拆分成 16 個庫,每個庫包含 64 張表,那么一次查詢可能會擴展為 16 × 64 = 1024 次查詢,導致查詢性能急劇下降。
當然,對于這個問題,也有一些解決方法。比如,在用戶庫中可以使用 ID 作為分區鍵,但如果之后需要按昵稱查詢用戶,理論上可以再按昵稱做一次拆分。然而,這會大幅增加存儲成本。如果以后還需要按注冊時間查詢,是否要繼續進行新的拆分呢?這種方法顯然不具備長遠性,因此需要更加靈活的解決思路。
因此,較為合適的解決方案是建立一個昵稱和 ID 的映射表。在查詢時,可以先通過昵稱查找到對應的 ID,再利用 ID 獲取完整的數據。這個映射表同樣可以采用分庫分表策略,雖然需要一定的存儲空間,但由于表中僅包含昵稱和 ID 兩個字段,所需空間相比重新拆分主表要少得多。
分庫分表引入的另一個問題是某些數據庫特性的實現可能變得更加復雜。例如,多表的 JOIN 操作在單庫情況下可以通過一條 SQL 語句完成,但拆分到多個數據庫后,無法跨庫執行 JOIN。不過好在我們對 JOIN 的需求并不高,即使有,也通常是將兩個表的數據提取到業務代碼中,再進行數據篩選,盡管實現稍顯復雜,但仍然可行。
另外,在未進行分庫分表之前,獲取數據總數只需在 SQL 中執行 count() 即可;而數據分散到多個庫表中后,就需要其他方案來實現。例如,可以將計數數據單獨存儲在一張表中,或將其記錄到 Redis 中。
盡管分庫分表會帶來一定的操作復雜性,但相比它對系統擴展性和性能的提升,依然值得實施。經過分庫分表的系統,能夠突破單機的容量和請求量瓶頸。正如我們電商系統中的訂單表,正是通過分庫分表,才解決了因數據量激增導致的性能衰減和存儲容量瓶頸。
所以,從我的經驗出發,對于分庫分表的原則主要有以下幾點:
在考慮分庫分表時,首先要遵循一個原則:如果系統在性能上還沒有遇到瓶頸,那么盡量不要實施分庫分表。
如果確實需要分庫分表,那么應盡量一次到位,比如選擇 16 個庫、每個庫包含 64 張表,這樣的方案基本可以滿足未來幾年內的業務需求,避免頻繁調整帶來的復雜性。
另外,許多 NoSQL 數據庫(如 HBase、MongoDB)提供了自動分片(auto-sharding)功能。如果團隊對這些組件有較強的熟悉度和運維能力,可以考慮使用這些 NoSQL 數據庫來替代傳統關系型數據庫,從而更高效地管理大規模數據。
在我看來,許多人并沒有真正理解拆分的必要性及其潛在影響,只是盲目跟隨大廠的拆分方法,導致問題頻出。因此,在使用某個方案解決問題時,務必要弄清原理,了解方案可能帶來的問題,并提前考慮應對之道。做到知其然并知其所以然,才能在解決問題的同時避免踩坑。