再無立錐之地!為什么說共享數據庫已成過去式?
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)
共享數據庫范式是一種常見的開發工作流程,即團隊中的所有開發人員都共享某一個數據庫的訪問權限,都使用該數據庫來支持應用程序開發。
這一工作流程很簡單,無需為每個工程師配置基礎架構,使安裝成本降至最低,因而人們愿意選擇它。但由于工程師做出改變的同時不得不承擔著影響其他人工作的風險,它也會給工程師造成痛苦和瓶頸。
Spawn使我們能夠輕松進行數據庫配置,并使每個工程師都擁有自己專用的數據庫環境,而無需配置任何額外的基礎架構。
共享數據庫
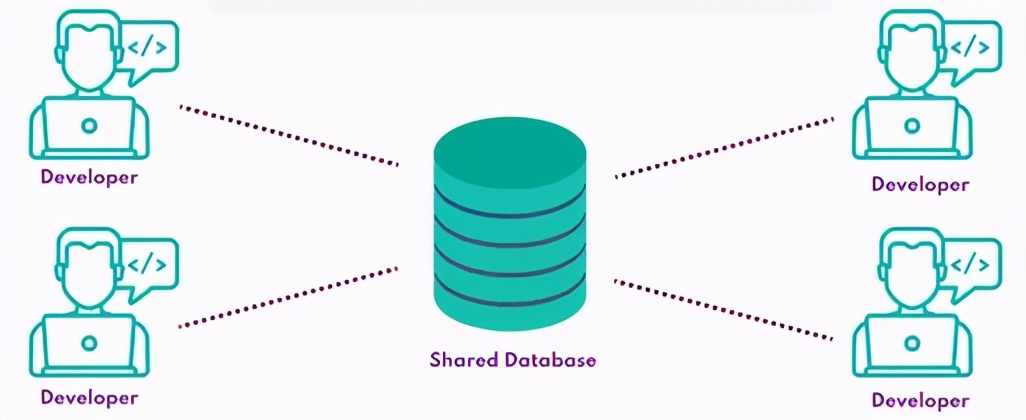
共享數據庫通常包含一個生產數據庫的副本(適當地被屏蔽以刪除敏感數據,并且可能被子集化以縮小其規模),該副本由團隊中的所有開發人員共享。共享數據庫的好處是管理的基礎架構更少,開發人員只需將連接字符串插入共享數據庫即可快速啟動并運行。
盡管這種設置對一個很小的團隊或很少進行數據庫更改的團隊頗有作用,但它很快會遇到一些問題:
- 互踩:開發人員可能會嘗試對共享數據庫進行矛盾互斥的更改,存在抹去彼此工作的風險。
- 不能安全地遷移應用:更改一項功能的數據庫架構可能會破壞其他代碼。
- 未知狀態:如果數據庫的狀態不受單個開發人員的控制,從一瞬間更改到下一瞬間,錯誤再現和應用程序測試將變得更加困難。
共享數據庫模式日益落后,因為容器化使得數據庫供應比以往任何時候都更容易,消除了基礎設施供應的開銷。
每個開發人員一個數據庫
在這種模型下,團隊中的每個開發人員都有自己的(隱藏的)生產數據庫副本,可以根據該副本進行工作。這使開發人員可以單獨更改其數據庫副本,從而解決了由于爭用共享數據庫而引起的問題。
這在過去比較困難,因為我們必須為每個開發人員提供類似于生產的應用程序數據庫的副本。但是,通過使用Spawn,我們可以從命令行配置臨時數據庫實例,而無需設置或托管任何其他基礎架構:
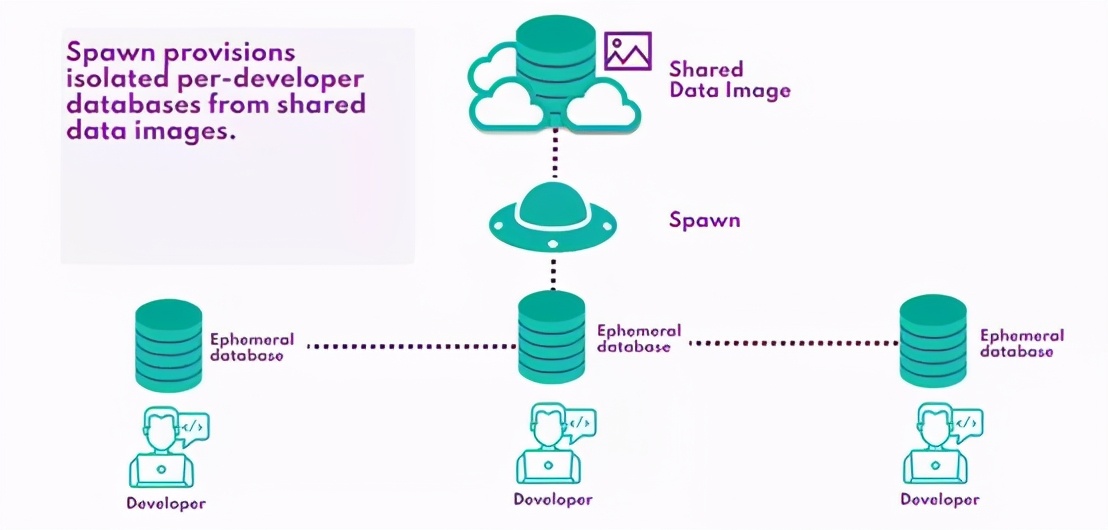
使用Spawn,我們可以每天從生產環境中創建一個數據映像(作為計劃構建管道的一部分),并使此映像對開發人員和CI系統都可用——所有這些都使用Spawn CLI。可以從備份文件或腳本創建映像。
然后,每個開發人員都可以基于此映像配置自己的數據庫,而不必像運行spawnctl create data-container
Spawn在幕后Kubernetes集群中創建并托管一個容器化的數據庫實例,將開發團隊從管理自己的數據庫基礎設施的負擔中解脫出來,并獲得專用數據庫進行開發的所有好處:
- 快速提供任意規模的數據庫:Spawn使用塊級文件系統快照來恢復和寫入數據庫。這意味著即使是最大的映像也可以在幾秒鐘內配置完畢,并且保持高速寫入。
- 快照和還原:可以使用Spawn CLI spawnctl save命令隨時對數據庫進行快照。使用spawnctlreset可恢復到以前的任何狀態。無需擔心數據庫更改,因為它總是很容易還原。
- 無需基礎設施:Spawn負責數據庫的供應和托管,允許開發人員專注于代碼。
- 同一映像的多個副本:一個映像可用于根據需要提供盡可能多的數據庫——所有這些數據庫都有自己的連接字符串,相互獨立和分離。
- 多數據庫支持:Spawn支持SQL Server、Postgres、MySQL、Redis和Mongo。
還等什么呢?是時候上手Spawn啦!