今天一大早就被網(wǎng)友們安利了一個(gè)熱門 AI 項(xiàng)目。
聽說(shuō),它可以帶你周游世界,還能讓 AngelaBaby 多拍幾部電視劇。
這是啥情況??
仔細(xì)一了解,原來(lái)是一款 AI 視頻摳圖神器,一大早就沖上了 GitHub 熱榜。
官方介紹說(shuō),這個(gè) AI 神器可以讓視頻處理變得非常簡(jiǎn)單且專業(yè),不用「綠幕」,也能達(dá)到逼真、毫無(wú)違和感的合成效果。
果然,打工人的 “周游世界”只有 AI 能實(shí)現(xiàn)了 [淚目]。
其實(shí),視頻摳圖 AI 已經(jīng)出現(xiàn)過(guò)不少,但這一款確實(shí)讓人覺得很驚艷。先來(lái)看下它演示 Demo。
你能看出公路背景和大海背景的視頻,哪一個(gè)是 AI 合成的嗎?

連撩起的頭發(fā)都看不出一點(diǎn)破綻。
而且就算瘋狂跳舞也沒有影響合成效果。

再來(lái)看下它背后的摳圖細(xì)節(jié),不僅精確到了頭發(fā),甚至還包括浮起的碎發(fā) ......

動(dòng)態(tài)效果也是如此,瘋狂甩頭也能實(shí)時(shí)捕捉細(xì)節(jié)。

這項(xiàng)超強(qiáng) AI 摳圖神器來(lái)自香港城市大學(xué)和商湯科技聯(lián)合研究團(tuán)隊(duì),論文一作還是一位在讀博士生張漢科。
接下來(lái),我們來(lái)看下它背后的技術(shù)原理。
目標(biāo)分解網(wǎng)絡(luò) MODNet
關(guān)鍵在于,這個(gè) AI 采用了一種輕量級(jí)的目標(biāo)分解網(wǎng)絡(luò) MODNet( Matting Objective Decomposition Network),它可以從不同背景的單個(gè)輸入圖像中平滑地處理動(dòng)態(tài)人像。
簡(jiǎn)單的說(shuō),其功能就是視頻人像摳圖。
我們知道,一些影視作品尤其是古裝劇,必須要對(duì)人物的背景進(jìn)行后期處理。為了達(dá)到逼真的合成效果,拍攝時(shí)一般都會(huì)采用「綠幕」做背景。因?yàn)榫G色屏幕可以使高質(zhì)量的 Alpha 蒙版實(shí)時(shí)提取圖像或視頻中的人物。
另外,如果沒有綠屏的話,通常采用的技術(shù)手段是光照處理法,即使預(yù)定義的 Trimap 作為自然光照算法輸入。這種方法會(huì)粗略地生成三位圖:確定的(不透明)前景,確定的(透明)背景以及介于兩者之間的未知(不透明)區(qū)域。
如果使用人工注釋三位圖不僅昂貴,而且深度相機(jī)可能會(huì)導(dǎo)致精度下降。因此,針對(duì)以上不足,研究人員提出了目標(biāo)分解網(wǎng)絡(luò) MODNet。
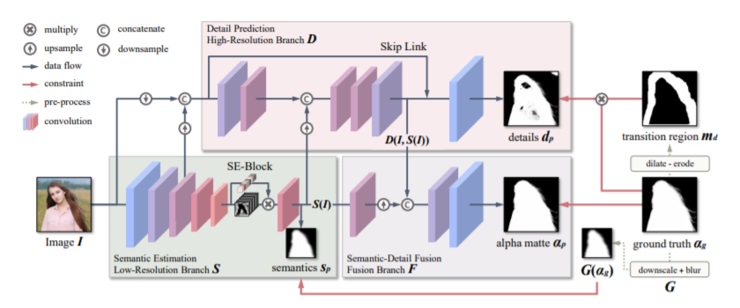
如圖所示,MODNet 由三個(gè)相互依賴的分支 S、D 和 F 構(gòu)成。它們分別通過(guò)一個(gè)低分辨率分支來(lái)預(yù)測(cè)人類語(yǔ)義(SP)、一個(gè)高分辨率分支來(lái)聚焦縱向的邊界細(xì)節(jié)(DP),最后一個(gè)融合分支來(lái)預(yù)測(cè) Alpha Matte (αp)。
具體如下:
-
語(yǔ)義估計(jì)(Semantic Estimation):采用 MobileNetV2[35]架構(gòu),通過(guò)編碼器(即 MODNet 的低分辨率分支)來(lái)提取高層語(yǔ)義。
-
細(xì)節(jié)預(yù)測(cè)(Detail Prediction):處理前景肖像周圍的過(guò)渡區(qū)域,以 I,S(I)和 S 的低層特征作為輸入。同時(shí)對(duì)它的卷積層數(shù)、信道數(shù)、輸入分辨率三個(gè)方面進(jìn)行了優(yōu)化。
-
語(yǔ)義細(xì)節(jié)融合(Semantic-Detail Fusion):一個(gè)融合了語(yǔ)義和細(xì)節(jié)的 CNN 模塊,它向上采樣 S(I)以使其形狀與 D(I,S(I))相之相匹配,再將 S(I)和 D(I,S(I))連接起來(lái)預(yù)測(cè)最終αp。
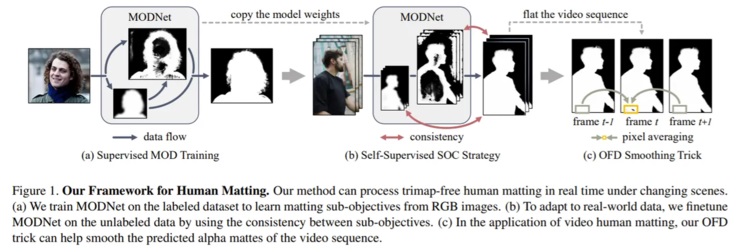
另外,基于以上底層框架,該研究還提出了一種自監(jiān)督策略 SOC(Sub-Objectives Consistency)和幀延遲處理方法 OFD(One-Frame Delay )。
其中,SOC 策略可以保證 MODNet 架構(gòu)在處理未標(biāo)注數(shù)據(jù)時(shí),讓輸出的子目標(biāo)之間具有一致性;OFD 方法在執(zhí)行人像摳像視頻任務(wù)時(shí),可以在平滑視頻序列中預(yù)測(cè) Alpha 遮罩。如下圖:
實(shí)驗(yàn)評(píng)估
在開展實(shí)驗(yàn)評(píng)估之前,研究人員創(chuàng)建了一個(gè)攝影人像基準(zhǔn)數(shù)據(jù)集 PPM-100(Photographic Portrait Matting)。
它包含了 100 幅不同背景的已精細(xì)注釋的肖像圖像。為了保證樣本的多樣性,PPM-100 還被定義了幾個(gè)分類規(guī)則來(lái)平衡樣本類型,比如是否包括整個(gè)人體;圖像背景是否模糊;是否持有其他物體。如圖:

PPM-100 中的樣圖具有豐富的背景和人物姿勢(shì)。因此可以被看做一個(gè)較為全面的基準(zhǔn)。
那么我們來(lái)看下實(shí)驗(yàn)結(jié)果:
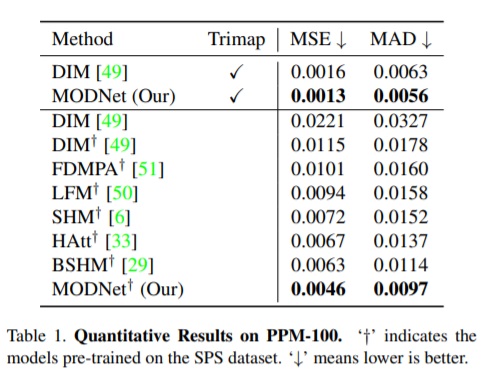
圖中顯示,MODNet 在 MSE(均方誤差)和 MAD(平均值)上都優(yōu)于其他無(wú) Trimap 的方法。雖然它的性能不如采用 Trimap 的 DIM,但如果將 MODNet 修改為基于 Trimap 的方法—即以 Trimap 作為輸入,它的性能會(huì)優(yōu)于基于 Trimap 的 DIM,這也再次表明顯示 MODNet 的結(jié)構(gòu)體系具有優(yōu)越性。
此外,研究人員還進(jìn)一步證明了 MODNet 在模型大小和執(zhí)行效率方面的優(yōu)勢(shì)。
其中,模型大小通過(guò)參數(shù)總數(shù)來(lái)衡量,執(zhí)行效率通過(guò) NVIDIA GTX1080 Ti GPU 上超過(guò) PPM-100 的平均參考時(shí)間來(lái)反映(輸入圖像被裁剪為 512×512)。結(jié)果如圖:
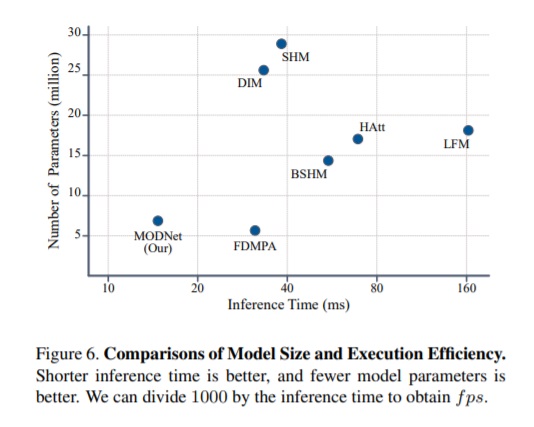
上圖顯示,MODNet 的推理時(shí)間為 15.8ms(63fps),是 FDMPA(31fps)的兩倍。雖然 MODNet 的參數(shù)量比 FDMPA 稍多,但性能明顯更好。
需要注意的是,較少的參數(shù)并不意味著更快的推理速度,因?yàn)槟P涂赡苡休^大的特征映射或耗時(shí)機(jī)制,比如,注意力機(jī)制(Attention Mechanisms)。
總之,MODNet 提出了一個(gè)簡(jiǎn)單、快速且有效實(shí)時(shí)人像摳圖處理方法。該方法僅以 RGB 圖像為輸入,實(shí)現(xiàn)了場(chǎng)景變化下 Alpha 蒙版預(yù)測(cè)。此外,由于所提出的 SOC 和 OFD,MODNet 在實(shí)際應(yīng)用中受到的域轉(zhuǎn)移問(wèn)題影響也較小。