訓練時間和參數量百倍降低,直接使用標簽進行預測,性能超GNN
將傳統標簽傳播方法與簡單模型相結合即在某些數據集上超過了當前最優 GNN 的性能,這是康奈爾大學與 Facebook 聯合提出的一項研究。這種新方法不僅能媲美當前 SOTA GNN 的性能,而且參數量也少得多,運行時更是快了幾個數量級。
圖神經網絡(GNN)是圖學習方面的主要技術。但是我們對 GNN 成功的奧秘以及它們對于優秀性能是否必然知之甚少。近日,來自康奈爾大學和 Facebook 的一項研究提出了一種新方法,在很多標準直推式節點分類(transductive node classification)基準上,該方法超過或媲美當前最優 GNN 的性能。
這一方法將忽略圖結構的淺層模型與兩項簡單的后處理步驟相結合,后處理步利用標簽結構中的關聯性:(i) 「誤差關聯」:在訓練數據中傳播殘差以糾正測試數據中的誤差;(ii) 「預測關聯」:平滑測試數據上的預測結果。研究人員將這一步驟稱作 Correct and Smooth (C&S),后處理步驟通過對早期基于圖的半監督學習方法中的標準標簽傳播(LP)技術進行簡單修正來實現。
該方法在多個基準上超過或接近當前最優 GNN 的性能,而其參數量比后者小得多,運行時也快了幾個數量級。例如,該方法在 OGB-Products 的性能超過 SOTA GNN,而其參數量是后者的 1/137,訓練時間是后者的 1/100。該方法的性能表明,直接將標簽信息納入學習算法可以輕松實現顯著的性能提升。這一方法還可以融入到大型 GNN 模型中。
圖神經網絡的缺陷
繼神經網絡在計算機視覺和自然語言處理領域的巨大成功之后,圖神經網絡被用來進行關系數據的預測。這些模型取得了很大進展,如 Open Graph Benchmark。新型 GNN 架構的許多設計思想是從語言模型(如注意力)或視覺模型(如深度卷積神經網絡)中的新架構改編而來。但是,隨著這些模型越來越復雜,理解其性能收益成為重要挑戰,并且將這些模型擴展到大型數據集的難度有所增加。
新方法:標簽信息 + 簡單模型
而這篇論文研究了結合更簡單的模型能夠達到怎樣的性能,并重點了解在圖學習特別是在直推式節點分類中,有哪些提高性能的機會。
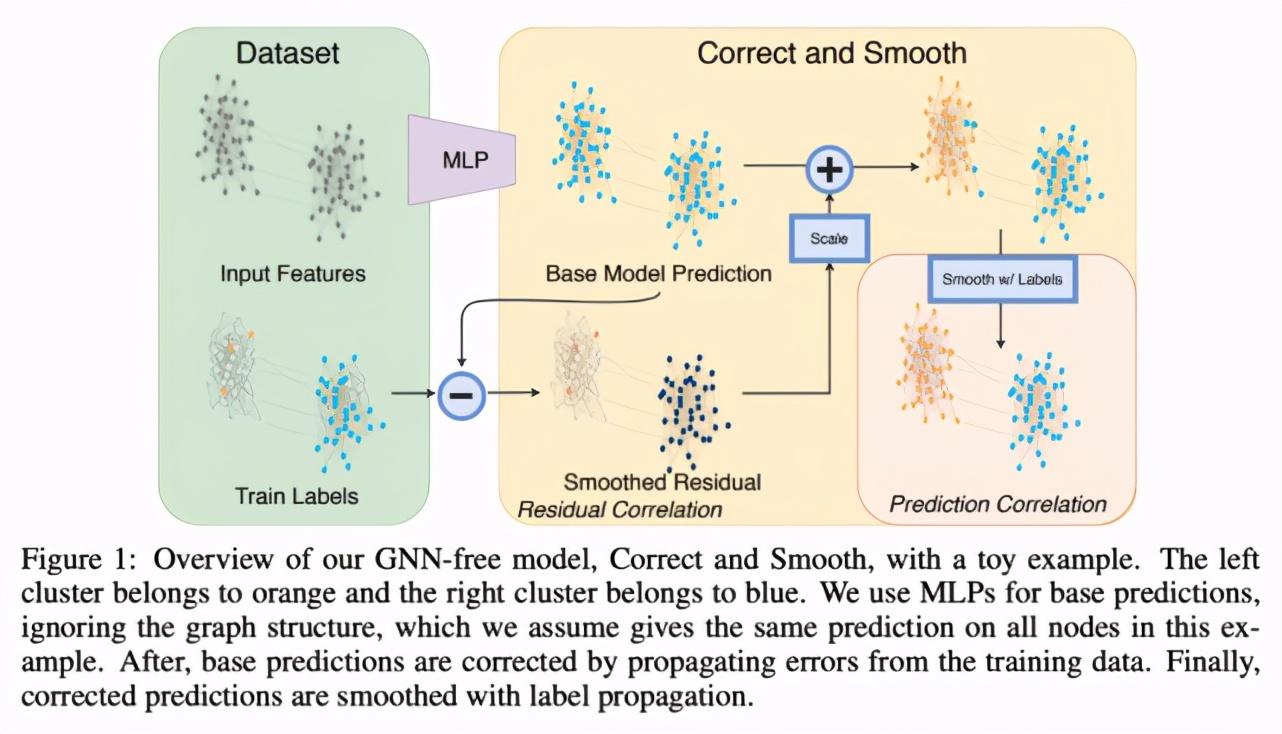
研究者提出了一個簡單的 pipeline(參見圖 1),它包含 3 個主要部分:
- 基礎預測(base prediction),使用忽略圖結構(如 MLP 或線性模型)的節點特征完成;
- 校正步驟,這一步將訓練數據的不確定性傳播到整個圖上,以校正基礎預測;
- 平滑圖預測結果。
步驟 2 和 3 只是后處理步驟,它們使用經典方法進行基于圖的半監督學習,即標簽傳播。
通過對這些經典 idea 進行改進和新的部署,該研究在多個節點分類任務上實現了 SOTA 性能,超過大型 GNN 模型。在該框架中,圖結構不用于學習參數,而是用作后處理機制。這種簡單性使模型參數和訓練時間減少了幾個數量級,并且可以輕松擴展到大型圖中。此外,該方法還可以與 SOTA GNN 結合,實現一定程度的性能提升。
該方法性能提升的主要來源是直接使用標簽進行預測。這并不是一個新想法,但很少用于 GNN。該研究發現,即使是簡單的標簽傳播(忽略特征)也能在許多基準測試中取得出色的效果。這為結合以下兩種預測能力來源提供了動力:一個來源于節點特征(忽略圖結構),另一個來源于在預測中直接使用已知標簽。
具體而言,該方法首先使用一個基于節點特征的基礎預測器,它不依賴于任何圖學習。然后,執行兩種類型的標簽傳播 (LP):一種通過建模相關誤差來校正基礎預測;一種用來平滑最終預測。研究人員將這兩種方法的結合稱作 Correct and Smooth(C&S,參見圖 1)。LP 只是后處理步驟,該 pipeline 并非端到端訓練。此外,圖只在后處理步驟中使用,在前處理步驟中用于增強特征,但不用于基礎預測。這使得該方法相比標準 GNN 模型訓練更快速,且具備可擴展性。
該研究還利用兩種 LP 和節點特征的優勢,將這些互補信號結合起來可以獲得優秀的預測結果。
實驗
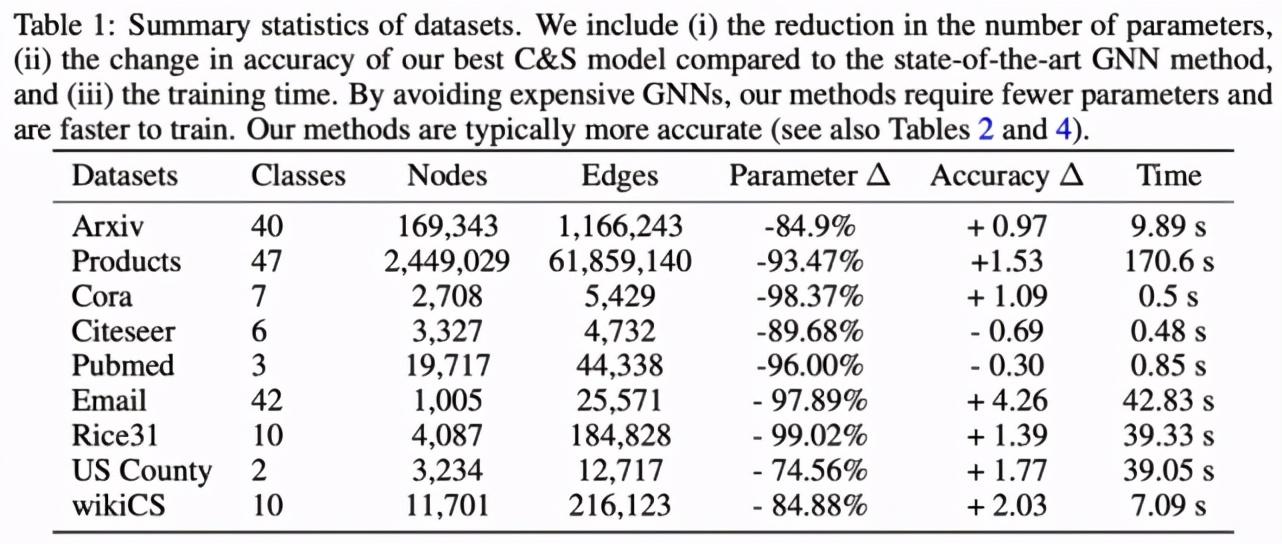
為了驗證該方法的有效性,研究者使用了 Arxiv、Products、Cora、Citeseer、Pubmed、Email、Rice31、US County 和 wikiCS 九個數據集。
節點分類的初步結果
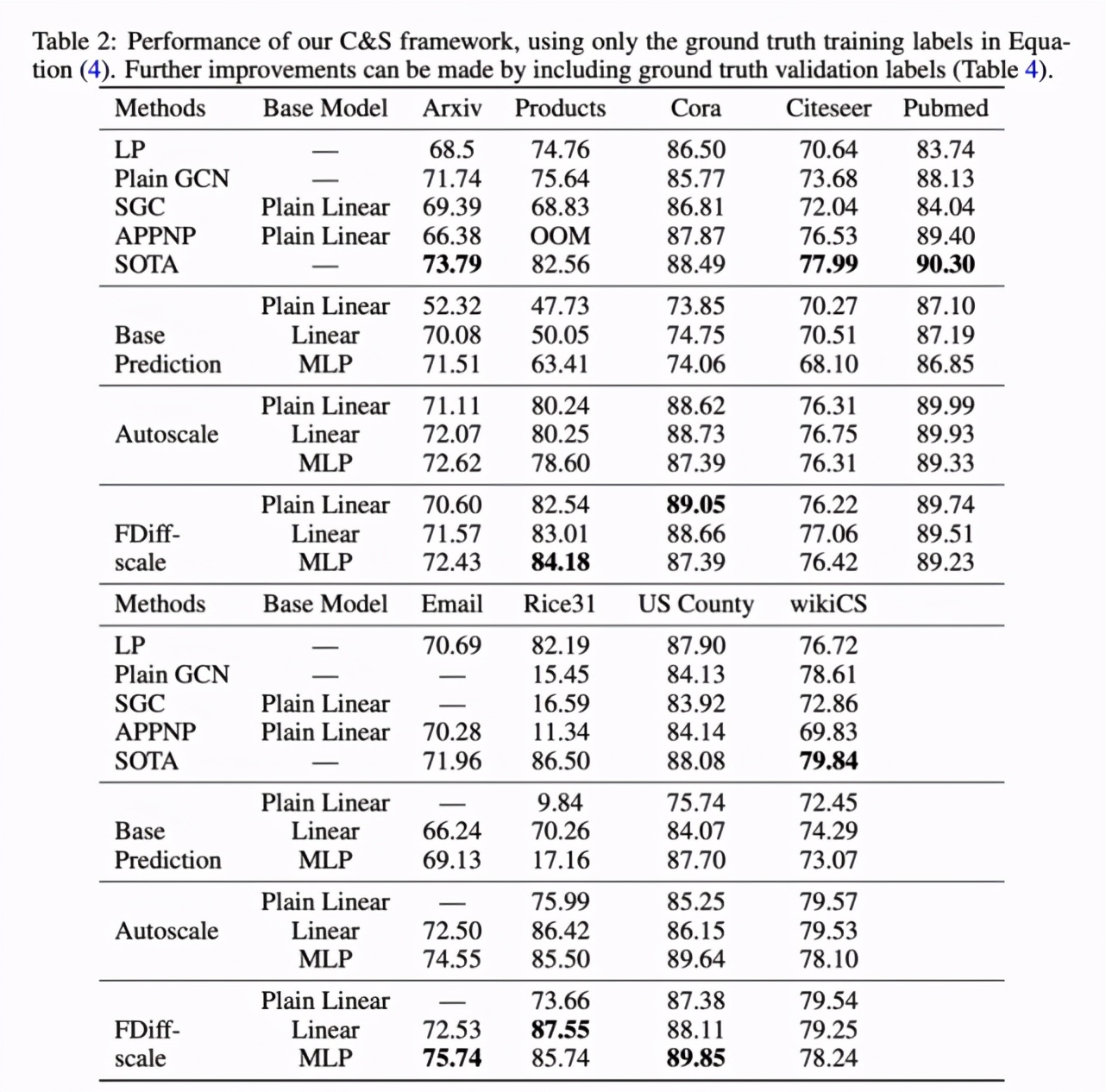
下表 2 給出了相關實驗結果,研究者得出了以下幾點重要發現。首先,利用本文提出的 C&S 模型,LP 后處理步驟會帶來巨大增益(如在 Products 數據集上,MLP 的基礎預測準確率由 63% 提升至 84%);其次,具有 C&S 框架的 Plain Linear 模型的性能在很多情況下優于 plain GCN,并且無可學習參數的方法 LP 的性能通常也媲美于 GCN。這些結果表明,通過簡單使用特征在圖中直接合并關聯往往是更好的做法;最后,C&S 模型變體在 Products、Cora、Email、Rice31 和 US County 等 5 個數據集上的性能通常顯著優于 SOTA。在其他數據集上,表現最佳的 C&S 模型與 SOTA 性能之間沒有太大的差距。
使用更多標簽進一步提升性能
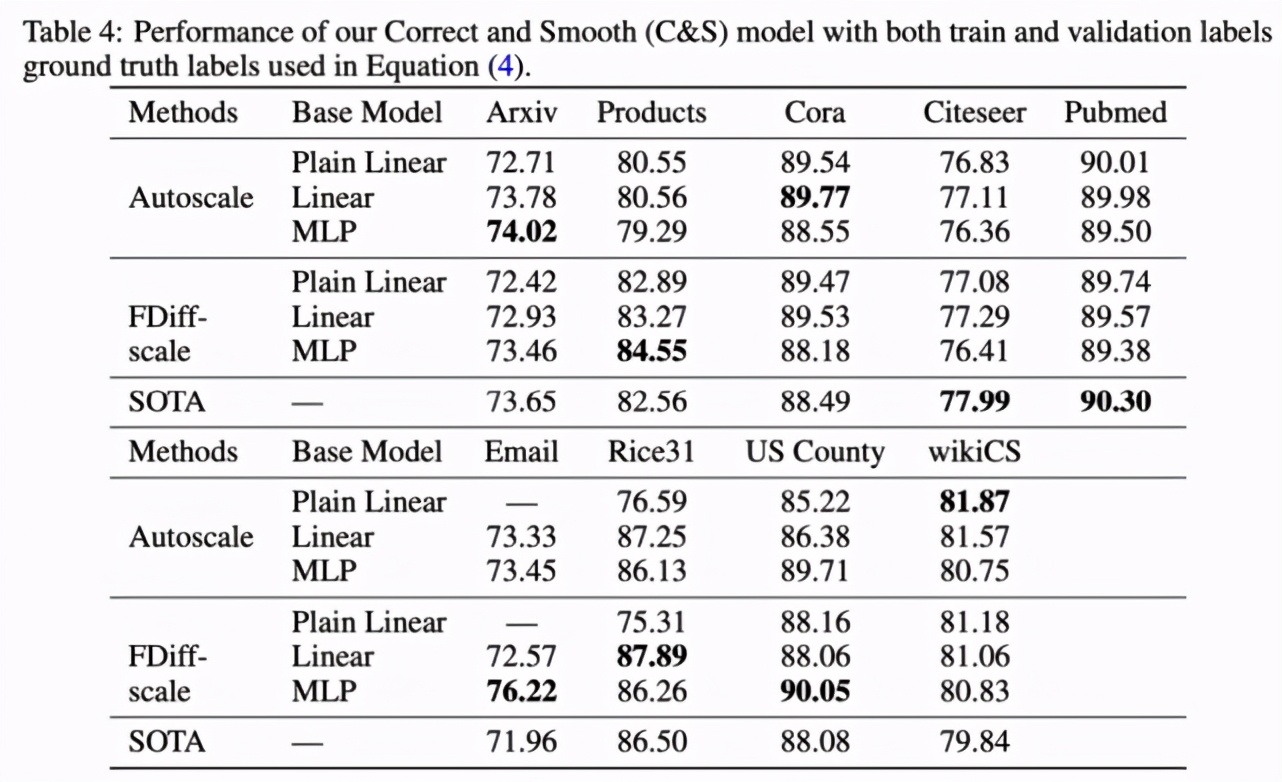
下表 4 展示了相關結果,強調了兩點重要發現。其一,對于想要在很多數據集上實現良好性能的直推式節點分類實驗而言,實際上并不需要規模大且訓練成本高的 GNN 模型;其二,結合傳統的標簽傳播方法和簡單的基礎預測器能夠在這些任務上優于圖神經網絡。
更快的訓練速度,性能超過現有 GNN
與 GNN 或其他 SOTA 解決方案相比,本文中的 C&S 模型需要的參數量往往要少得多。如下圖 2 所示,研究者繪制了 OGB-Products 數據集上參數與性能(準確率)的變化曲線圖。
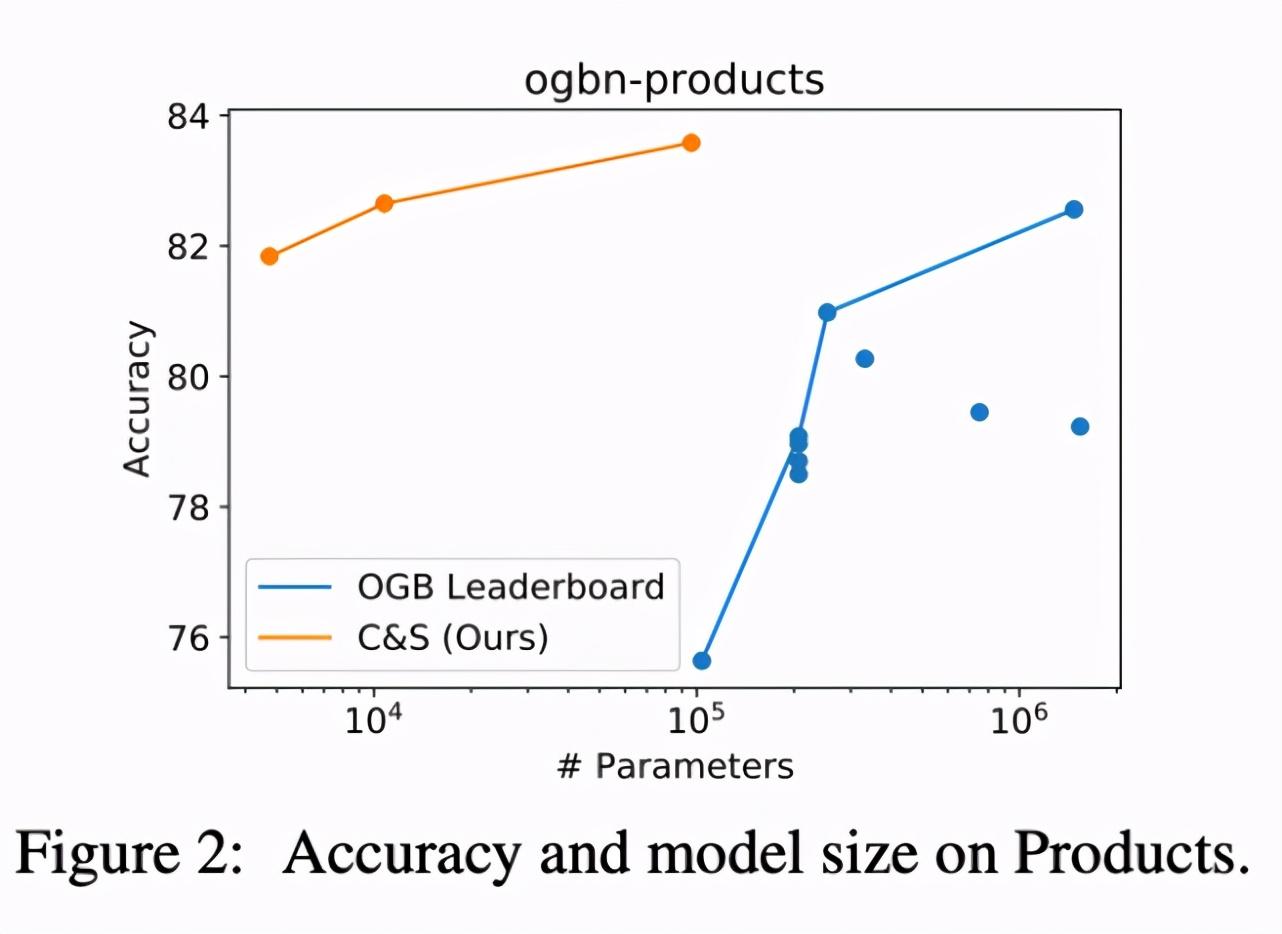
除了參數量變少之外,真正的增益之處在于訓練速度更快了。由于研究者在基礎預測中沒有使用圖結構,與其他模型相比,C&S 模型在保持準確率相當的同時往往實現了訓練速度的數量級提升。
具體而言,與 OGB-Products 數據集上的 SOTA GNN 相比,具有線性基礎預測器的 C&S 框架表現出更高的準確率,并且訓練時長減至 1/100,參數量降至 1/137。
性能可視化
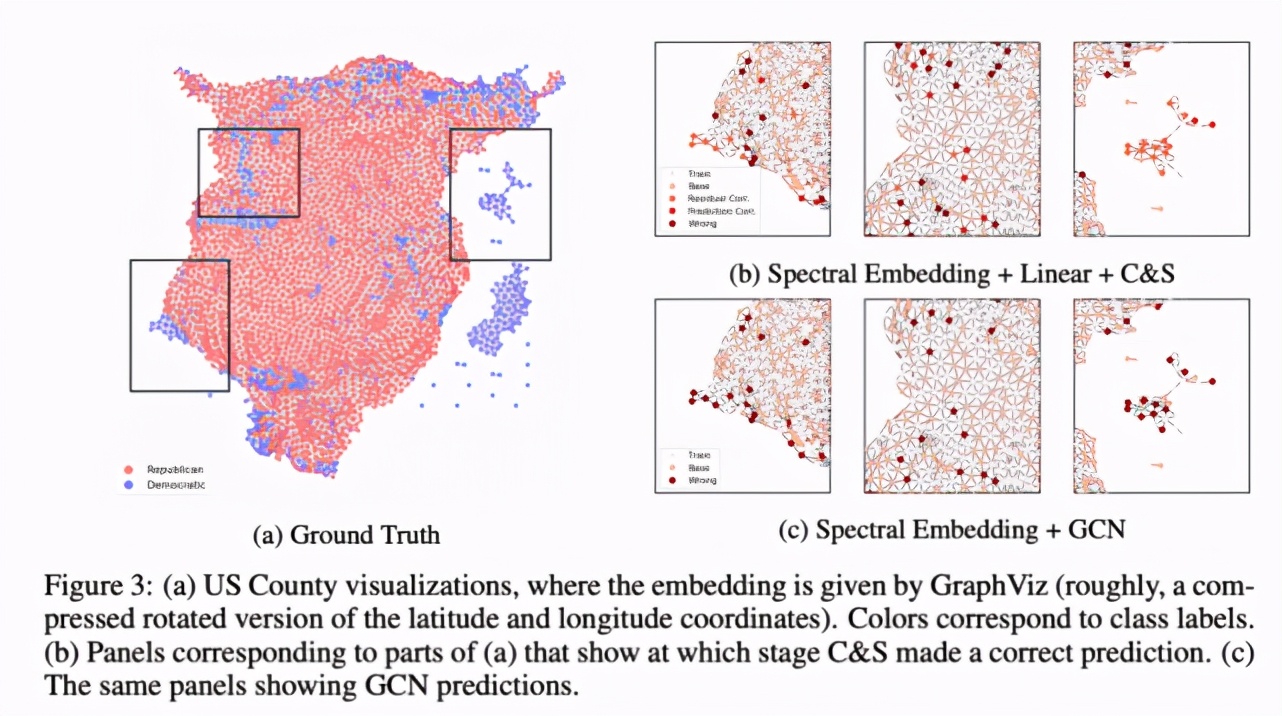
為了更好地理解 C&S 模型的性能,研究者將 US County 數據集上的預測結果進行了可視化操作,具體如下圖 3 所示。正如預期的一樣,對于相鄰 county 提供相關信息的節點而言,殘差關聯往往會予以糾正。