













速度超快!字節(jié)跳動(dòng)開源序列推理引擎LightSeq
這應(yīng)該是業(yè)界第一款完整支持 Transformer、GPT 等多種模型高速推理的開源引擎。
2017 年 Google 提出了 Transformer [1] 模型,之后在它基礎(chǔ)上誕生了許多優(yōu)秀的預(yù)訓(xùn)練語(yǔ)言模型和機(jī)器翻譯模型,如 BERT [2] 、GPT 系列[13]等,不斷刷新著眾多自然語(yǔ)言處理任務(wù)的能力水平。與此同時(shí),這些模型的參數(shù)量也在呈現(xiàn)近乎指數(shù)增長(zhǎng)(如下圖所示)。例如最近引發(fā)熱烈討論的 GPT-3 [3],擁有 1750 億參數(shù),再次刷新了參數(shù)量的記錄。
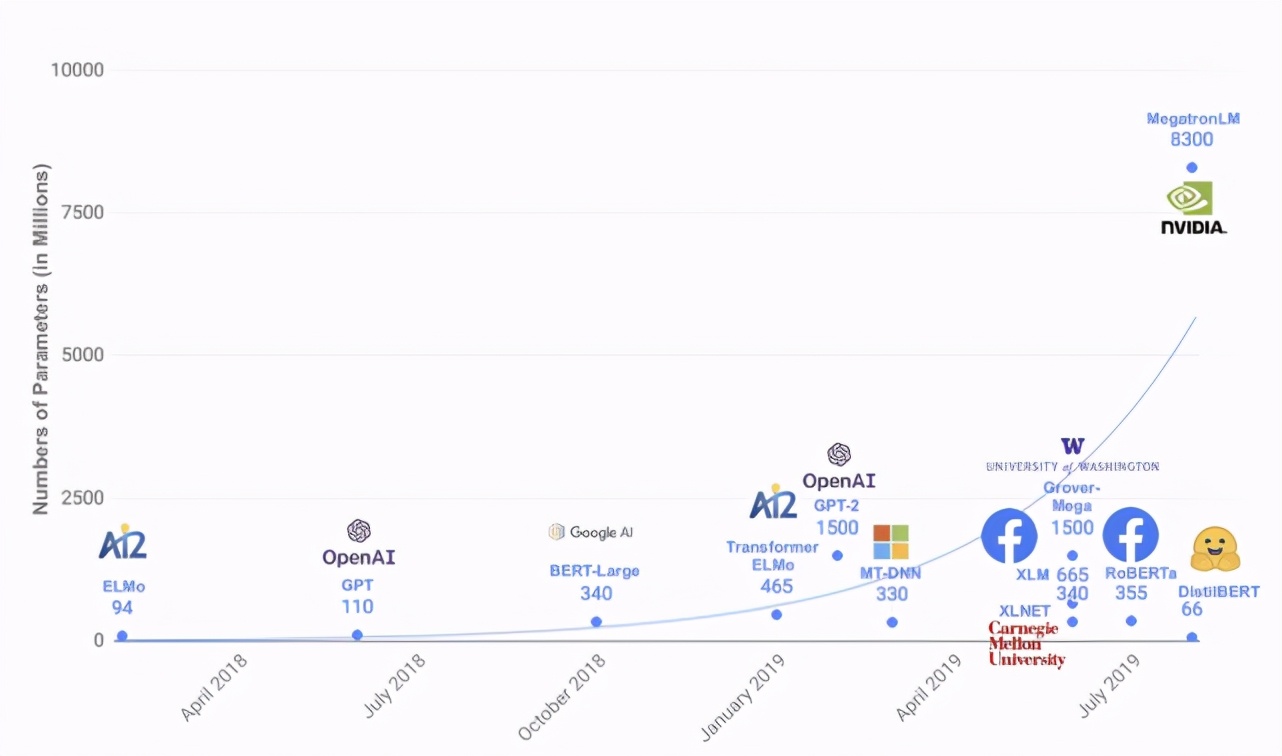
如此巨大的參數(shù)量,也為模型推理部署帶來(lái)了挑戰(zhàn)。以機(jī)器翻譯為例,目前 WMT[4]比賽中 SOTA 模型已經(jīng)達(dá)到了 50 層以上。主流深度學(xué)習(xí)框架下,翻譯一句話需要好幾秒。這帶來(lái)了兩個(gè)問題:一是翻譯時(shí)間太長(zhǎng),影響產(chǎn)品用戶體驗(yàn);二是單卡 QPS (每秒查詢率)太低,導(dǎo)致服務(wù)成本過高。
因此,今天給大家安利一款速度非常快,同時(shí)支持非常多特性的高性能序列推理引擎——LightSeq。它對(duì)以 Transformer 為基礎(chǔ)的序列特征提取器(Encoder)和自回歸的序列解碼器(Decoder)做了深度優(yōu)化,早在 2019 年 12 月就已經(jīng)開源,應(yīng)用在了包括火山翻譯等眾多業(yè)務(wù)和場(chǎng)景。據(jù)了解,這應(yīng)該是業(yè)界第一款完整支持 Transformer、GPT 等多種模型高速推理的開源引擎。
LightSeq 可以應(yīng)用于機(jī)器翻譯、自動(dòng)問答、智能寫作、對(duì)話回復(fù)生成等眾多文本生成場(chǎng)景,大大提高線上模型推理速度,改善用戶的使用體驗(yàn),降低企業(yè)的運(yùn)營(yíng)服務(wù)成本。
相比于目前其他開源序列推理引擎,LightSeq具有如下幾點(diǎn)優(yōu)勢(shì):
1. 高性能
LightSeq推理速度非常快。例如在翻譯任務(wù)上,LightSeq相比于Tensorflow實(shí)現(xiàn)最多可以達(dá)到14倍的加速。同時(shí)領(lǐng)先目前其他開源序列推理引擎,例如最多可比Faster Transformer快1.4倍。
2. 支持模型功能多
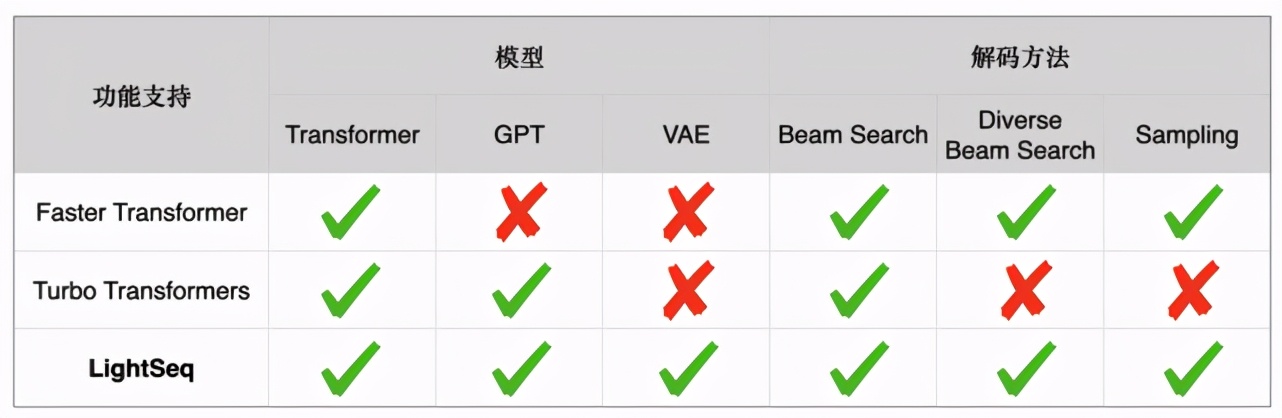
LightSeq支持BERT、GPT、Transformer、VAE 等眾多模型,同時(shí)支持beam search、diverse beam search[5]、sampling等多種解碼方式。下表詳細(xì)列舉了Faster Transformer[7]、Turbo Transformers[6]和LightSeq三種推理引擎在文本生成場(chǎng)景的功能差異:
3. 簡(jiǎn)單易用,無(wú)縫銜接Tensorflow、PyTorch等深度學(xué)習(xí)框架
LightSeq通過定義模型協(xié)議,支持各種深度學(xué)習(xí)框架訓(xùn)練好的模型靈活導(dǎo)入。同時(shí)包含了開箱即用的端到端模型服務(wù),即在不需要寫一行代碼的情況下部署高速模型推理,同時(shí)也靈活支持多層次復(fù)用。
使用方法
利用 LightSeq 部署線上服務(wù)比較簡(jiǎn)便。LightSeq 支持了 Triton Inference Server[8],這是 Nvidia 開源的一款 GPU 推理 server ,包含眾多實(shí)用的服務(wù)中間件。LightSeq 支持了該 server 的自定義推理引擎 API 。因此只要將訓(xùn)練好的模型導(dǎo)出到 LightSeq 定義的模型協(xié)議[9]中,就可以在不寫代碼的情況下,一鍵啟動(dòng)端到端的高效模型服務(wù)。更改模型配置(例如層數(shù)和 embedding 大小)都可以方便支持。具體過程如下:
首先準(zhǔn)備好模型倉(cāng)庫(kù),下面是目錄結(jié)構(gòu)示例,其中 transformer.pb 是按模型協(xié)議導(dǎo)出的模型權(quán)重,libtransformer.so 是 LightSeq 的編譯產(chǎn)物。
- - model_zoo/- model_repo/- config.pbtxt- transformer.pb- 1/- libtransformer.so
然后就可以啟動(dòng)Triton Inference Server[8],搭建起模型服務(wù)。
- trtserver --model-store=${model_zoo}
性能測(cè)試
在 NVIDIA Tesla P4 和 NVIDIA Tesla T4 顯卡上,筆者測(cè)試了 LightSeq 的性能,選擇了深度學(xué)習(xí)框架 Tensorflow v1.13 和解碼場(chǎng)景支持較為豐富的 Faster Transformer v2.1 實(shí)現(xiàn)作為對(duì)比。Turbo Transformers 解碼方法比較單一(只支持 Beam Search ,不支持文本生成中常用的采樣解碼),尚未滿足實(shí)際應(yīng)用需求,因此未作對(duì)比。
機(jī)器翻譯性能
在機(jī)器翻譯場(chǎng)景下,筆者測(cè)試了 Transformer base 模型(6層 encoder、6層 decoder 、隱層維度 512 )采用 beam search 解碼的性能,實(shí)驗(yàn)結(jié)果如下:
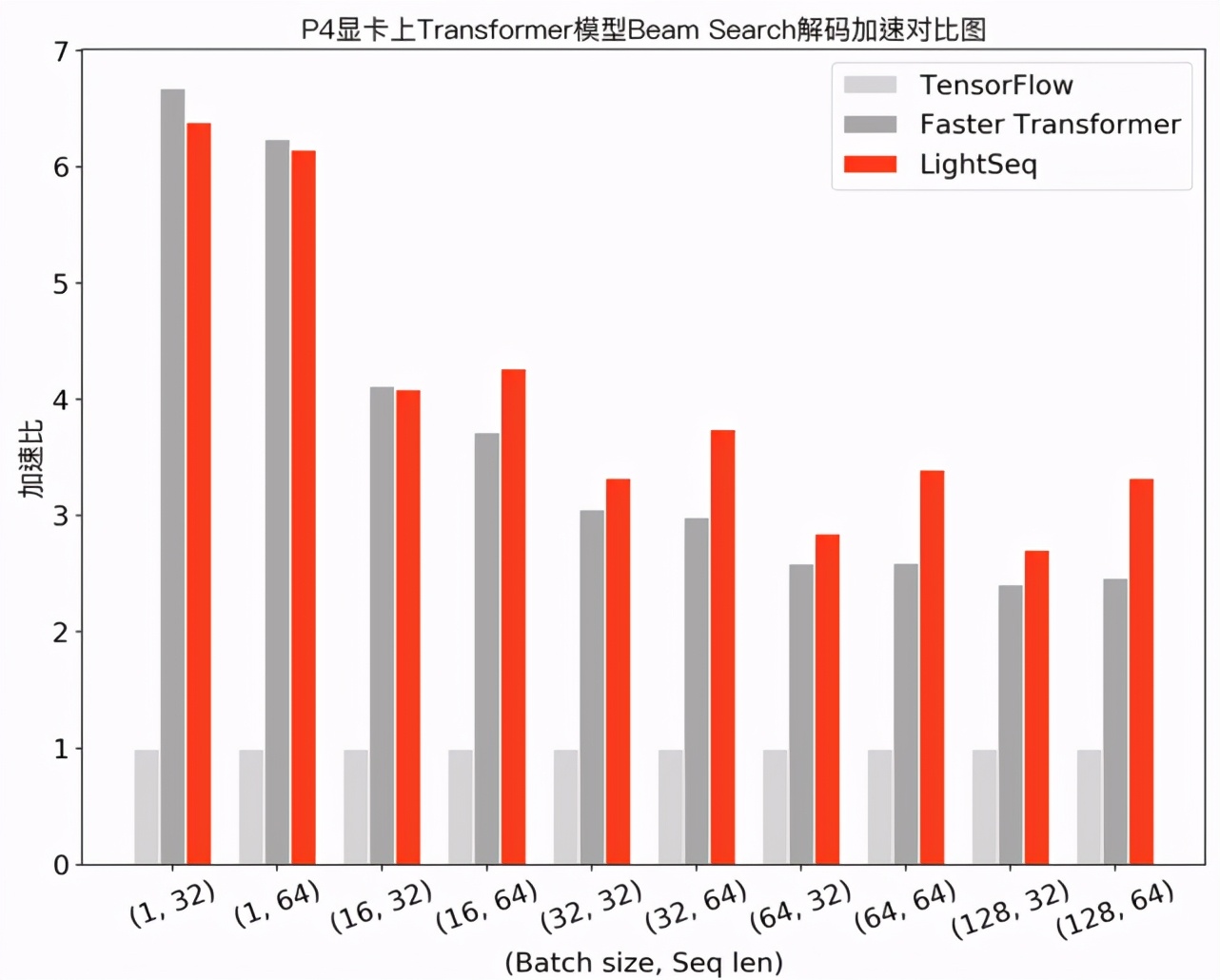
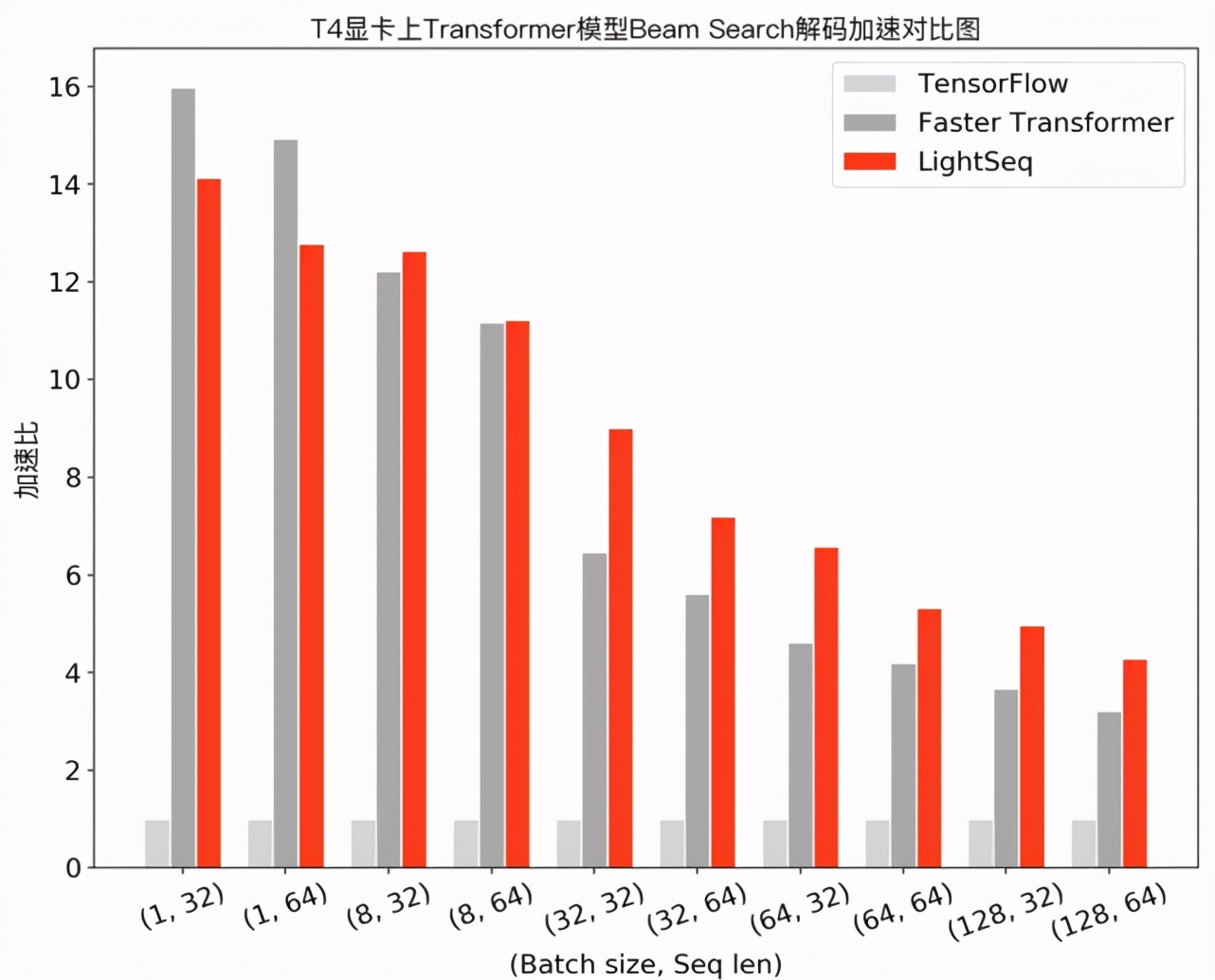
可以發(fā)現(xiàn),在小 batch 場(chǎng)景下,F(xiàn)aster Transformer 和 LightSeq 對(duì)比 Tensorflow 都達(dá)到了 10 倍左右的加速。而隨著 batch 的增大,由于矩陣乘法運(yùn)算占比越來(lái)越高,兩者對(duì) Tensorflow 的加速比都呈衰減趨勢(shì)。LightSeq 衰減相對(duì)平緩,特別是在大 batch 場(chǎng)景下更加具有優(yōu)勢(shì),最多能比 Faster Transformer 快 1.4 倍。這也對(duì)未來(lái)的一些推理優(yōu)化工作提供了指導(dǎo):小 batch 場(chǎng)景下,只要做好非計(jì)算密集型算子融合,就可以取得很高的加速收益;而大 batch 場(chǎng)景下則需要繼續(xù)優(yōu)化計(jì)算密集型算子,例如矩陣乘法等。
最后在 WMT14 標(biāo)準(zhǔn)的法英翻譯任務(wù)上,筆者測(cè)試了 Transformer big 模型的性能。LightSeq 在 Tesla P4 顯卡上平均每句翻譯延遲為 167ms ,Tesla T4 上減小到了 82ms。而作為對(duì)比, TensorFlow 延遲均為 1071ms,LightSeq 分別達(dá)到了 6.41 和 13.06 倍加速。另外,筆者嘗試了其他多種模型配置,得到了比較一致的加速效率。例如更深層的模型結(jié)構(gòu)上(encoder加深至 16 層),LightSeq 得到的加速比,分別是 6.97 和 13.85 倍。
文本生成性能
上述機(jī)器翻譯通常采用 Beam Search 方法來(lái)解碼, 而在文本生成場(chǎng)景,經(jīng)常需要使用采樣( Sampling )來(lái)提升生成結(jié)果的多樣性。下圖展示了 Transformer base 模型采用 top-k/top-p sampling 的性能測(cè)試對(duì)比:
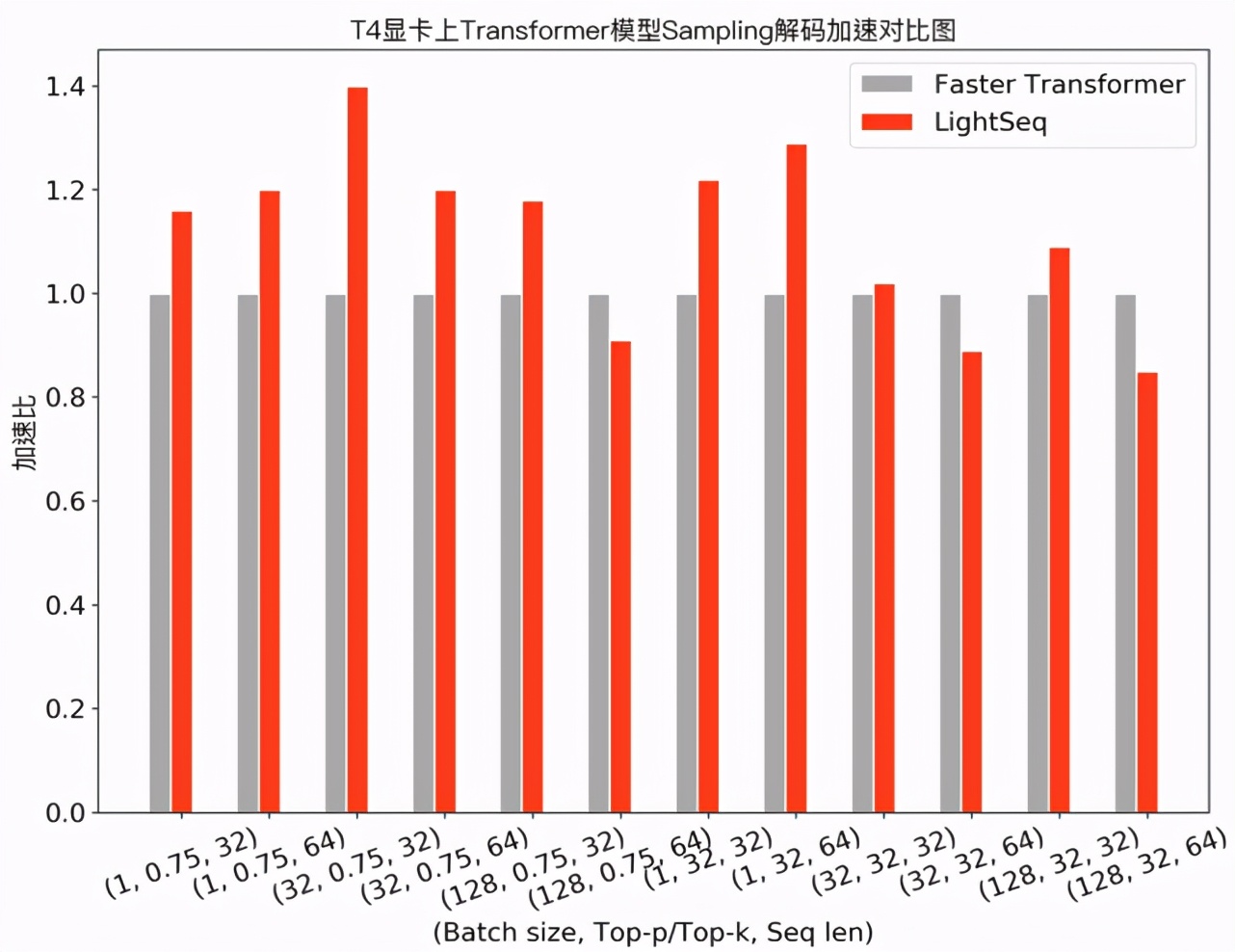
可以發(fā)現(xiàn),在需要使用采樣解碼的任務(wù)中,LightSeq 在大部分配置下領(lǐng)先于 Faster Transformer,最多也能達(dá)到 1.4 倍的額外加速。此外,相比于 TensorFlow 實(shí)現(xiàn),LightSeq 對(duì) GPT 和 VAE 等生成模型也達(dá)到了 5 倍以上的加速效果。
服務(wù)壓力測(cè)試
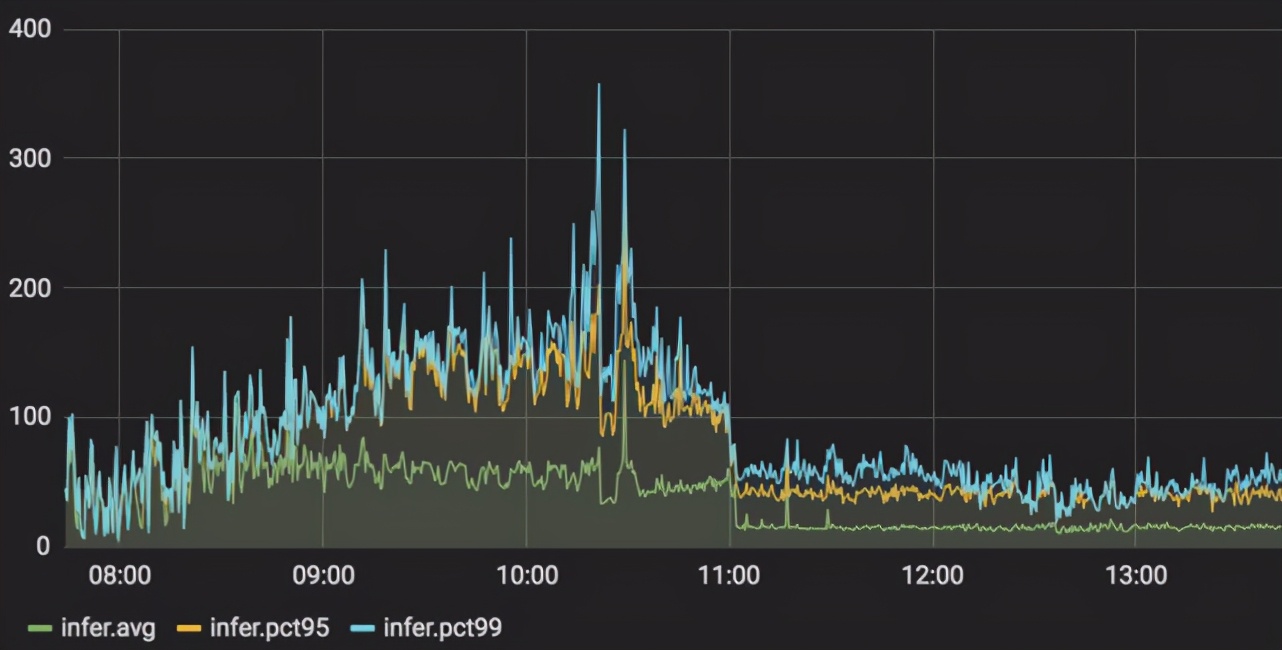
在云服務(wù)上,筆者測(cè)試了在實(shí)際應(yīng)用中 GPT 場(chǎng)景下,模型服務(wù)從 Tensorflow 切換到LightSeq 的延遲變化情況(服務(wù)顯卡使用 NVIDIA Tesla P4)。可以觀察到,pct99 延遲降低了 3 到 5 倍,峰值從 360 毫秒左右下降到 80 毫秒左右,詳細(xì)結(jié)果如下圖所示:
更多的對(duì)比實(shí)驗(yàn)結(jié)果可以在 LightSeq 性能評(píng)測(cè)報(bào)告 [10] 中查看到。
技術(shù)原理
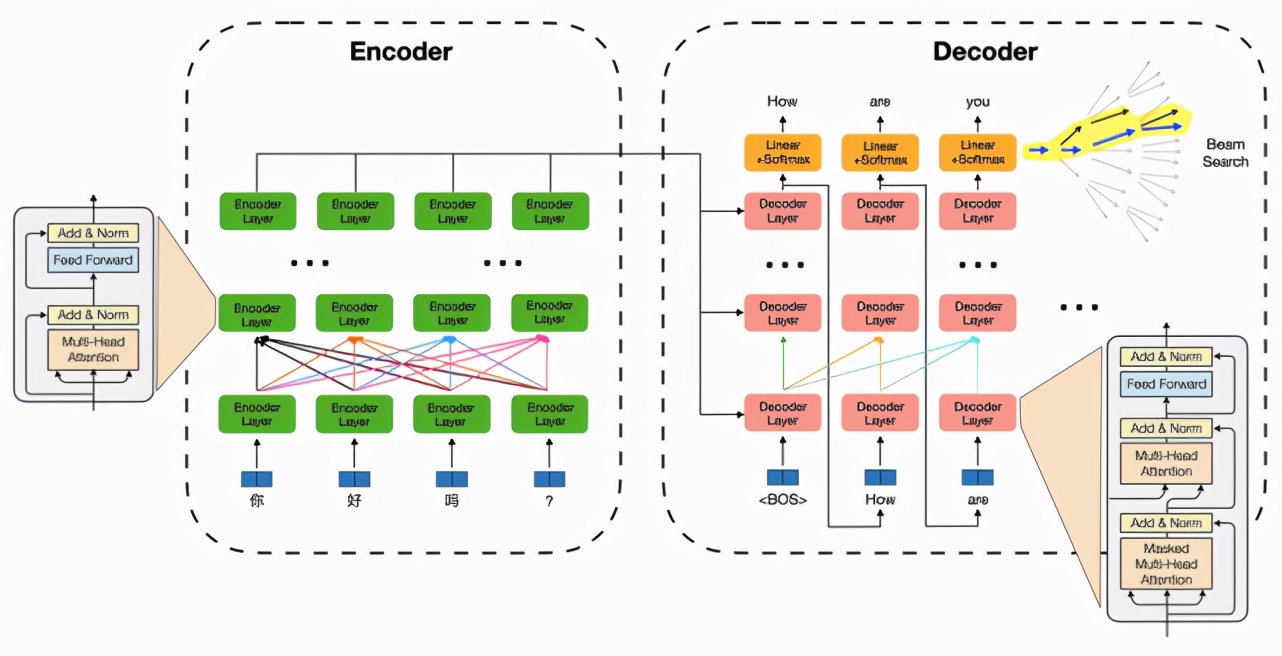
以 Transformer 為例,一個(gè)機(jī)器翻譯/文本生成模型推理過程包括兩部分:序列編碼模塊特征計(jì)算和自回歸的解碼算法。其中特征計(jì)算部分以自注意力機(jī)制及特征變換為核心(矩陣乘法,計(jì)算密集型),并伴隨大量 Elementwise(如 Reshape)和 Reduce(如Layer Normalization)等 IO 密集型運(yùn)算;解碼算法部分包含了詞表 Softmax、beam 篩選、緩存刷新等過程,運(yùn)算瑣碎,并引入了更復(fù)雜的動(dòng)態(tài) shape。這為模型推理帶來(lái)了眾多挑戰(zhàn):
1. IO 密集型計(jì)算的細(xì)粒度核函數(shù)調(diào)用帶來(lái)大量冗余顯存讀寫,成為特征計(jì)算性能瓶頸。
2. 復(fù)雜動(dòng)態(tài) shape 為計(jì)算圖優(yōu)化帶來(lái)挑戰(zhàn),導(dǎo)致模型推理期間大量顯存動(dòng)態(tài)申請(qǐng),耗時(shí)較高。
3. 解碼生成每一步字符過程邏輯復(fù)雜,難以并行化計(jì)算從而發(fā)揮硬件優(yōu)勢(shì)。
LightSeq 取得這么好的推理加速效果,對(duì)這些挑戰(zhàn)做了哪些針對(duì)性的優(yōu)化呢?筆者分析發(fā)現(xiàn),核心技術(shù)包括這幾項(xiàng):融合了多個(gè)運(yùn)算操作來(lái)減少 IO 開銷、復(fù)用顯存來(lái)避免動(dòng)態(tài)申請(qǐng)、解碼算法進(jìn)行層級(jí)式改寫來(lái)提升推理速度。下面詳細(xì)介紹下各部分的優(yōu)化挑戰(zhàn)和 LightSeq 的解決方法。
算子多運(yùn)算融合
近年來(lái),由于其高效的特征提取能力,Transformer encoder/decoder 結(jié)構(gòu)被廣泛應(yīng)用于各種 NLP 任務(wù)中,例如海量無(wú)標(biāo)注文本的預(yù)訓(xùn)練。而多數(shù)深度學(xué)習(xí)框架(例如 Tensorflow、Pytorch 等)通常都是調(diào)用基礎(chǔ)運(yùn)算庫(kù)中的核函數(shù)(kernel function)來(lái)實(shí)現(xiàn) encoder/decoder 計(jì)算過程。這些核函數(shù)往往粒度較細(xì),通常一個(gè)組件需要調(diào)用多個(gè)核函數(shù)來(lái)實(shí)現(xiàn)。
以層歸一化(Layer Normalization)為例,Tensorflow 是這樣實(shí)現(xiàn)的:
- mean = tf.reduce_mean(x, axis=[-1], keepdims=True)variance = tf.reduce_mean(tf.square(x - mean), axis=[-1], keepdims=True)result = (x - mean) * tf.rsqrt(variance + epsilon) * scale + bias
可以發(fā)現(xiàn),即使基于編譯優(yōu)化技術(shù)(自動(dòng)融合廣播(Broadcast)操作和按元素(Elementwise)運(yùn)算),也依然需要進(jìn)行三次核函數(shù)調(diào)用(兩次 reduce_mean,一次計(jì)算最終結(jié)果)和兩次中間結(jié)果的顯存讀寫(mean 和 variance)。而基于 CUDA,我們可以定制化一個(gè)層歸一化專用的核函數(shù),將兩次中間結(jié)果的寫入寄存器。從而實(shí)現(xiàn)一次核函數(shù)調(diào)用,同時(shí)沒有中間結(jié)果顯存讀寫,因此大大節(jié)省了計(jì)算開銷。有興趣的同學(xué)可以在文末參考鏈接中進(jìn)一步查看具體實(shí)現(xiàn)[11]。
基于這個(gè)思路,LightSeq 利用 CUDA 矩陣運(yùn)算庫(kù) cuBLAS[12]提供的矩陣乘法和自定義核函數(shù)實(shí)現(xiàn)了 Transformer,具體結(jié)構(gòu)如下圖所示:
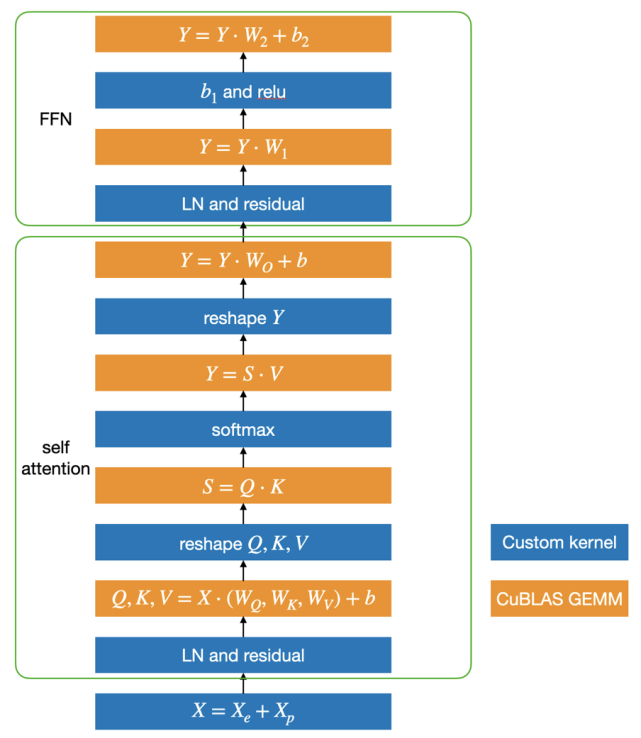
藍(lán)色部分是自定義核函數(shù),黃色部分是矩陣乘法。可以發(fā)現(xiàn),矩陣乘法之間的運(yùn)算全部都用一個(gè)定制化核函數(shù)實(shí)現(xiàn)了,因此大大減少了核函數(shù)調(diào)用和顯存讀寫,最終提升了運(yùn)算速度。
動(dòng)態(tài)顯存復(fù)用
為了避免計(jì)算過程中的顯存申請(qǐng)釋放并節(jié)省顯存占用,LightSeq 首先對(duì)模型中所有動(dòng)態(tài)的 shape 都定義了最大值(例如最大序列長(zhǎng)度),將所有動(dòng)態(tài)shape轉(zhuǎn)換為靜態(tài)。接著在服務(wù)啟動(dòng)的時(shí)候,為計(jì)算過程中的每個(gè)中間計(jì)算結(jié)果按最大值分配顯存,并對(duì)沒有依賴的中間結(jié)果共用顯存。這樣對(duì)每個(gè)請(qǐng)求,模型推理時(shí)不再申請(qǐng)顯存,做到了:不同請(qǐng)求的相同 Tensor 復(fù)用顯存;同請(qǐng)求的不同 Tensor 按 shape 及依賴關(guān)系復(fù)用顯存。
通過該顯存復(fù)用策略,在一張 T4 顯卡上,LightSeq 可以同時(shí)部署多達(dá) 8 個(gè) Transformer big 模型(batch_size=8,最大序列長(zhǎng)度=8,beam_size=4,vocab_size=3萬(wàn))。從而在低頻或錯(cuò)峰等場(chǎng)景下,大大提升顯卡利用率。
層級(jí)式解碼計(jì)算
在自回歸序列生成場(chǎng)景中,最復(fù)雜且耗時(shí)的部分就是解碼。LightSeq 目前已經(jīng)支持了 beam search、diversity beam search、top-k/top-p sampling 等多種解碼方法,并且可以配合 Transformer、GPT使用,達(dá)到數(shù)倍加速。這里我們以應(yīng)用最多的 beam search 為例,介紹一下 LightSeq 對(duì)解碼過程的優(yōu)化。
首先來(lái)看下在深度學(xué)習(xí)框架中傳統(tǒng)是如何進(jìn)行一步解碼計(jì)算的:
# 1.計(jì)算以每個(gè)token為結(jié)尾的序列的log probability
- log_token_prob = tf.nn.log_softmax(logit) # [batch_size, beam_size, vocab_size]log_seq_prob += log_token_prob # [batch_size, beam_size, vocab_size]log_seq_prob = tf.reshape(log_seq_prob, [-1, beam_size * vocab_size])
# 2. 為每個(gè)序列(batch element)找出排名topk的token
- topk_log_probs, topk_indices = tf.nn.top_k(log_seq_prob, k=K)
# 3. 根據(jù)beam id,刷新decoder中的self attention模塊中的key和value的緩存
- refresh_cache(cache, topk_indices)
可以發(fā)現(xiàn),為了挑選概率 top-k 的 token ,必須在 [batch_size, beam_size, vocab_size]大小的 logit 矩陣上進(jìn)行 softmax 計(jì)算及顯存讀寫,然后進(jìn)行 batch_size 次排序。通常 vocab_size 都是在幾萬(wàn)規(guī)模,因此計(jì)算量非常龐大,而且這僅僅只是一步解碼的計(jì)算消耗。因此實(shí)踐中也可以發(fā)現(xiàn),解碼模塊在自回歸序列生成任務(wù)中,累計(jì)延遲占比很高(超過 30%)。
LightSeq 的創(chuàng)新點(diǎn)在于結(jié)合 GPU 計(jì)算特性,借鑒搜索推薦中常用的粗選-精排的兩段式策略,將解碼計(jì)算改寫成層級(jí)式,設(shè)計(jì)了一個(gè) logit 粗選核函數(shù),成功避免了 softmax 的計(jì)算及對(duì)十幾萬(wàn)元素的排序。該粗選核函數(shù)遍歷 logit 矩陣兩次:
• 第一次遍歷,對(duì)每個(gè) beam,將其 logit 值隨機(jī)分成k組,每組求最大值,然后對(duì)這k個(gè)最大值求一個(gè)最小值,作為一個(gè)近似的top-k值(一定小于等于真實(shí)top-k值),記為R-top-k。在遍歷過程中,同時(shí)可以計(jì)算該beam中l(wèi)ogit的log_sum_exp值。
• 第二次遍歷,對(duì)每個(gè) beam,找出所有大于等于 R-top-k 的 logit 值,將(logit - log_sum_exp + batch_id * offset, beam_id * vocab_size + vocab_id)寫入候選隊(duì)列,其中 offset 是 logit 的下界。
在第一次遍歷中,logit 值通常服從正態(tài)分布,因此算出的R-top-k值非常接近真實(shí)top-k值。同時(shí)因?yàn)檫@一步只涉及到寄存器的讀寫,且算法復(fù)雜度低,因此可以快速執(zhí)行完成(十幾個(gè)指令周期)。實(shí)際觀察發(fā)現(xiàn),在top-4設(shè)置下,根據(jù)R-top-k只會(huì)從幾萬(wàn)token中粗選出十幾個(gè)候選,因此非常高效。第二次遍歷中,根據(jù)R-top-k粗選出候選,同時(shí)對(duì) logit 值按 batch_id 做了值偏移,多線程并發(fā)寫入顯存中的候選隊(duì)列。
粗選完成后,在候選隊(duì)列中進(jìn)行一次排序,就能得到整個(gè)batch中每個(gè)序列的準(zhǔn)確top-k值,然后更新緩存,一步解碼過程就快速執(zhí)行完成了。
下面是k=2,詞表大小=8的情況下一個(gè)具體的示例(列代表第幾個(gè)字符輸出,行代表每個(gè)位置的候選)。可以看出,原來(lái)需要對(duì) 16 個(gè)元素進(jìn)行排序,而采用層級(jí)解碼之后,最后只需要對(duì) 5 個(gè)元素排序即可,大大降低了排序的復(fù)雜度。

可視化分析計(jì)算延遲
為了驗(yàn)證上面幾種優(yōu)化技術(shù)的實(shí)際效果,筆者用 GPU profile 工具,對(duì) LightSeq 的一次推理過程進(jìn)行了延遲分析。下圖展示了 32 位浮點(diǎn)數(shù)和 16 位浮點(diǎn)數(shù)精度下,各計(jì)算模塊的延遲占比:
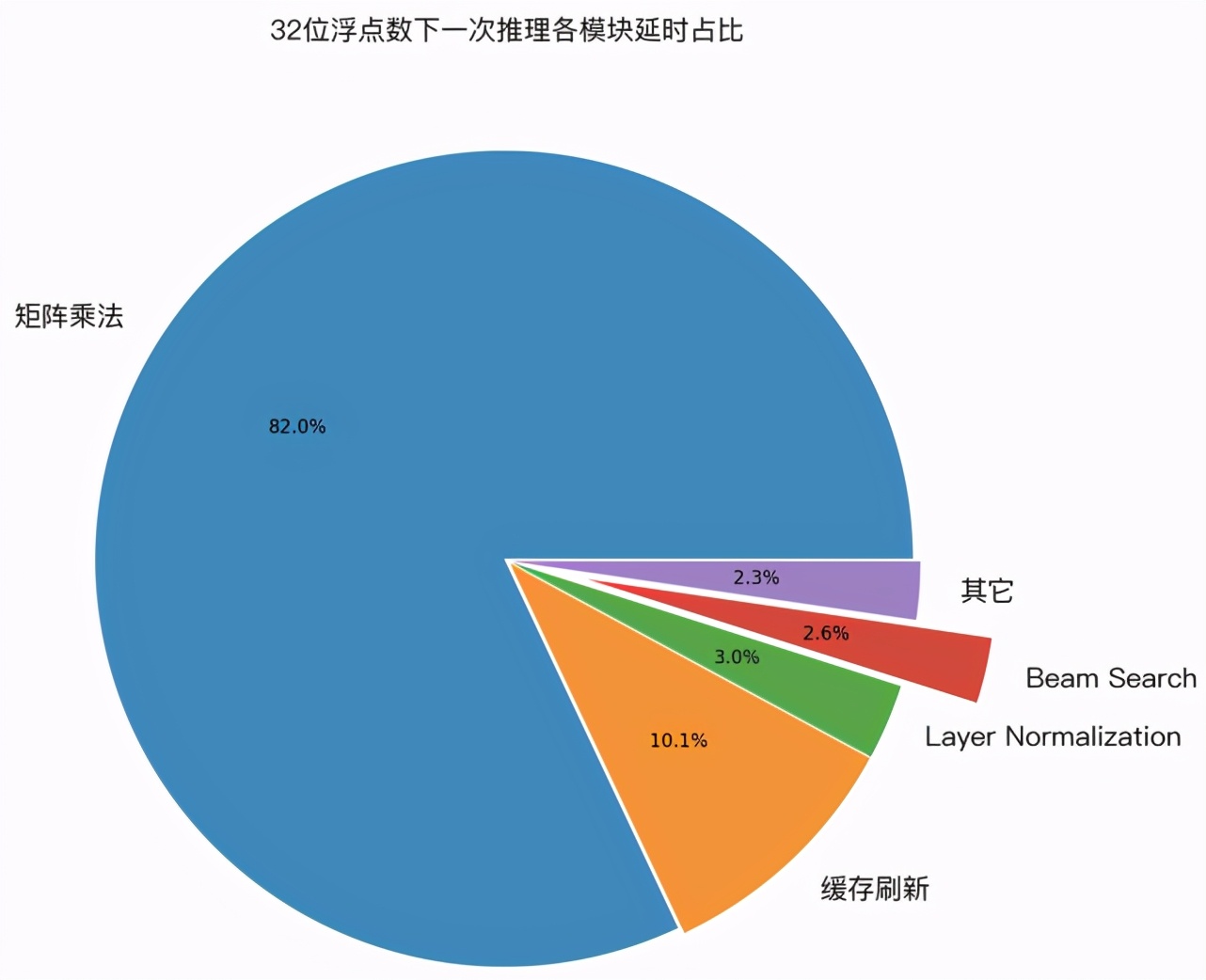
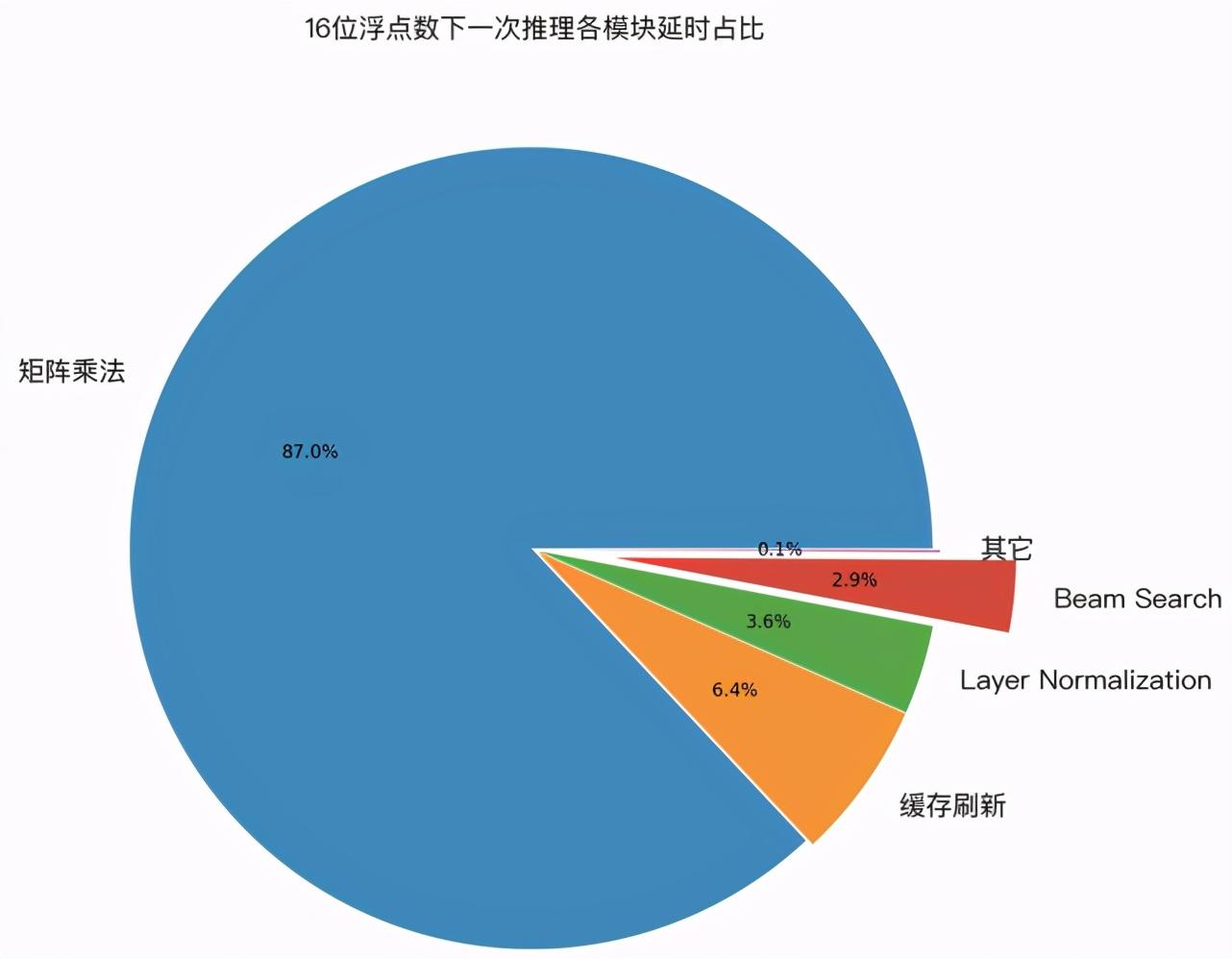
可以發(fā)現(xiàn),在兩種計(jì)算精度下:
1. 經(jīng)過優(yōu)化后,cuBLAS 中的矩陣乘法計(jì)算延遲分別占比 82% 和 88% ,成為推理加速新的主要瓶頸。而作為對(duì)比,我們測(cè)試了 Tensorflow 模型,矩陣乘法計(jì)算延遲只占了 25% 。這說(shuō)明 LightSeq 的 beam search 優(yōu)化已經(jīng)將延遲降到了非常低的水平。
2. 緩存刷新分別占比 10% 和 6% ,比重也較高,但很難繼續(xù)優(yōu)化。今后可以嘗試減少緩存量(如降低 decoder 層數(shù),降低緩存精度等)來(lái)繼續(xù)降低延遲。
3. 其他運(yùn)算總計(jì)占比 8% 和 6% ,包括了 Layer Normalization、beam search 和中間結(jié)果的顯存讀寫等。
可視化結(jié)果說(shuō)明了 LightSeq 已經(jīng)做到了極致優(yōu)化,大大提升了推理速度。
傳送門:
GitHub項(xiàng)目地址:
https://github.com/bytedance/lightseq





























