程序員修神之路--它可能是分布式系統中最重要的樞紐
- 分布式系統為什么需要注冊中心呢?
- 分布式系統注冊中心有哪些坑?
- 分布式系統注冊中心怎么來實現呢?
- 注冊中心利用現成的組件很好實現嗎?
看到標題你可能會鄙視一下,注冊中心有是什么講的。注冊中心作為現在架構中的一個組件來說,確實很常見。微服務作為分布式系統最典型的一種表現形式,是最近幾年最流行的概念之一。每個講微服務的文章中或多或少都會提及注冊中心,但也只是一帶而過,注冊中心作為分布式系統或者微服務架構中最重要的一環,我覺得有必要寫一篇單獨的文章來詳細的介紹一下,這也是有這篇文章的原因。
分布式系統的痛點
注冊中心從架構的角度來講,其實是一個統稱的概念,并非現在流行的微服務所有,在很早之前利用Nginx做負載均衡(反向代理)的時候,Nginx會根據配置文件把每個請求根據配置的策略導向后端具體的處理程序,在這個流程中,站在客戶端角度,Nginx很像一個網關,站在后端處理程序的角度,Nginx更像是服務的管理中心,它管理著所有可以提供服務的后端處理程序信息,并且還可以利用某些手段來達到服務的健康檢查,服務的自動注冊和剔除等操作。
當然現在流行微服務,網關和注冊中心被分為兩個并行的概念和組件。在重要性上來說,我覺得注冊中心的權重要大于網關。現在十分流行單體服務拆分操作,但是這里我要強調一點,你的單體服務是否有必要拆分,還要根據很多情況來綜合考慮,畢竟拆分成小的微服務并非沒有代價。
在很早之前,如果客戶端需要請求后端的多個服務,很多情況下后端的服務信息是寫在請求方的配置文件中的,類似于這樣
- {
- "ServiceA":[
- "http://192.168.100.100",
- "http://192.168.100.101",
- "http://192.168.100.102"
- ]
- }
這種方式固然是一種解決方案,但是隨著系統的不斷升級會遇到很多問題:
- 在系統需要擴容后端服務器的時候,需要手動修改客戶端的配置文件,而且在多數情況下還需要重啟客戶端進程
- 當后端的一個服務節點出現故障的時候,需要手動刪除客戶端配置文件中對應的節點,而且在多數情況下還需要重啟客戶端進程
- 每次增加或者刪除節點的時候需要人工干預,大大提高了維護成本
鑒于以上幾個原因,注冊中心應運而生。
注冊中心的作用
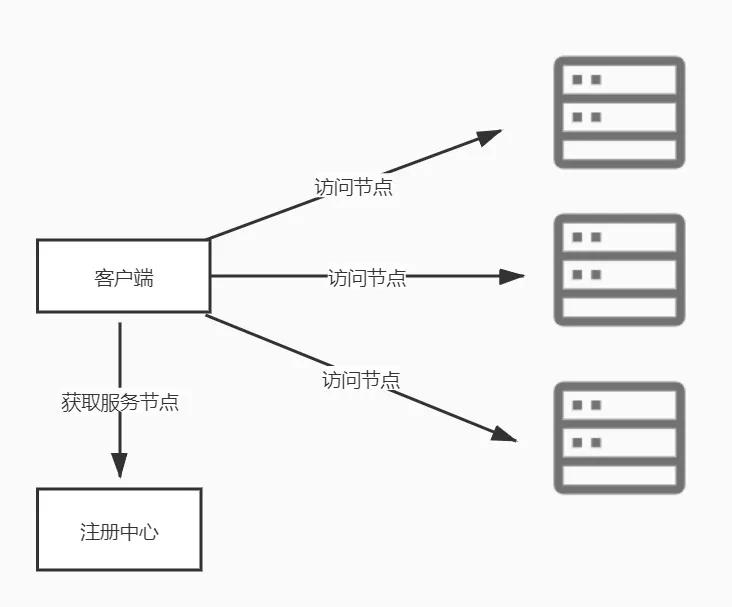
注冊中心不僅僅解決了服務節點的增加刪除問題,而且在整個的查找服務可用節點的流程上做了修改,在搭配了服務健康檢查的手段之后,更可以做到自動化。目前業界有很多可供選擇的注冊中心,比如ZooKeeper,ETCD,阿里的微服務注冊中心 Nacos、Spring Cloud 的 Eureka 等等,之前菜菜的文章就有寫過利用ETCD來實現一個配置中心
服務注冊發現
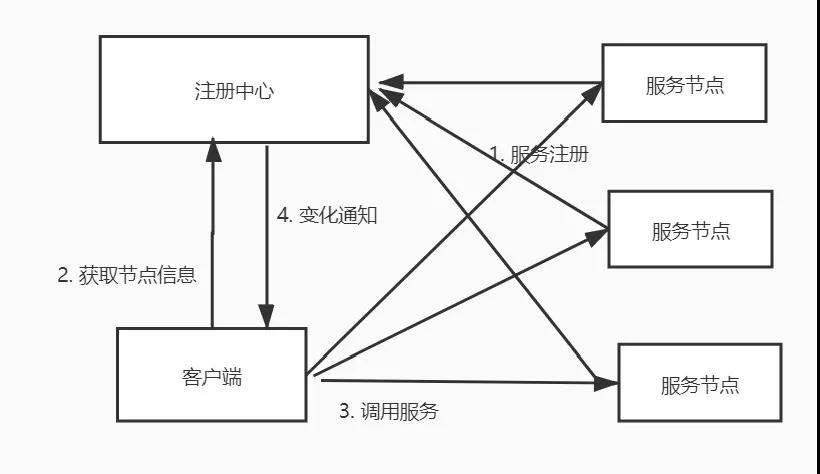
服務的注冊發現是注冊中心提供的最基礎也是最主要的功能:
- 當一個新的服務節點上線的時候,可以通過注冊中心的接口進行注冊,當一個服務節點發生故障的時候,注冊中心會自動刪除該服務節點
- 當注冊中心的服務節點發生變化的時候,能夠及時通知調用方,服務的調用方可以近乎實時的來更新可用的服務節點信息
負載均衡
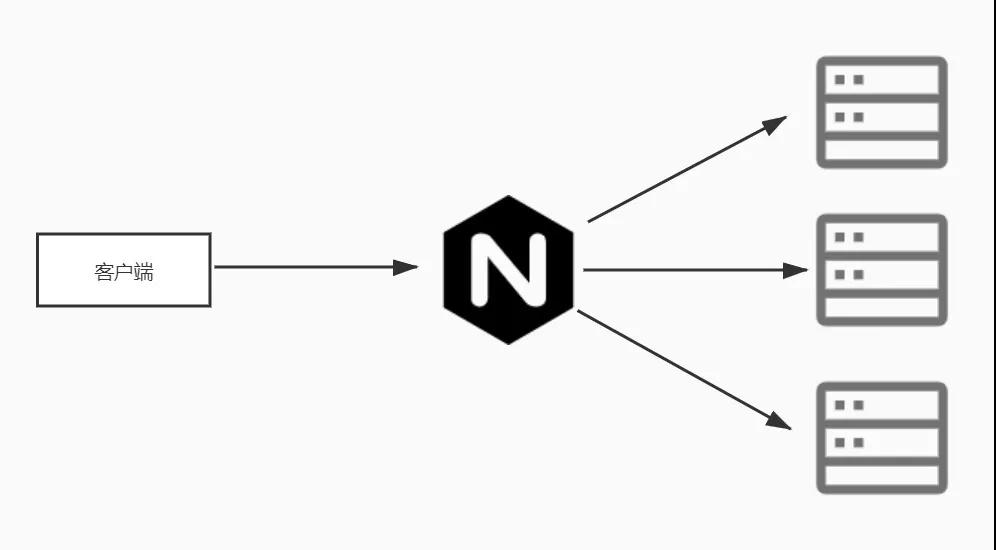
當客戶端在注冊中心獲取到可用的服務節點之后,就可以根據輪訓或者權重等策略來訪問服務了,這種場景下注冊中心更像一個負載均衡器,把流量導向多個不同的節點。
既然是負載均衡,在某種意義上講就可以實現服務的橫向擴展,說實話這確實沒有什么問題,道理和Nginx做負載均衡道理類似。
那些坑
服務中心雖然在整體架構模式上解決了很多問題,但是在使用中我們也要直面它所帶來的一些副作用,而且這些副作用有時候會成為整個系統癱瘓的導火線。
數據一致性問題
數據的一致性好像是所有系統都要面對的問題,注冊中心也不例外。這里的一致性是指注冊中心內存儲的可用節點數據和后端真實可用節點以及客戶端存儲的可用節點之間的差異性問題。舉個栗子:假如注冊中心中存儲了ABC三個服務節點信息,而這個時候節點A由于某種原因下線了,注冊中心必須要及時把A節點移除掉,并且通知客戶端也把A節點移除。
從理論上來講,以上過程跨越了注冊中心和調用方以及被調用方的交互流程,屬于分布式中的事務問題,即:分布式事務問題。在之前菜菜的文章中也說過,分布式的事務要想保證嚴格的一致性必然會影響可用性
分布式下,我想要一致性
而且從目前主流的注冊中心技術來看,注冊中心和雙方的通信流程屬于異步流程,所以做不到實時的事務性要求。
目前注冊中心在通知客戶端變化的方面可以做到近乎于實時(其實并非實時),但是在監測后端服務節點是否可用的過程中,卻很難做到近乎實時。其中的原因一是因為網絡的不可靠特性,一次網絡通信失敗,并非意味著下次網絡通信失敗,二是監測后端服務可用的方式并非實時的。目前流行的兩種探測后端服務可用的方式為:
注冊中心主動探測
很多注冊中心的組件都支持這種方式,在這種方式下,后端的每個服務需要提供一個可供探測的接口或者端口,注冊中心根據配置每隔一段時間去調用一次服務的接口或端口,如果返回正常就認為服務處于正常運行狀態,否則則認為服務不可用,不可用的情況下注冊中心會主動把當前服務移除列表,并通知客戶端。
雖然這種方式看似很完美,其實還是有坑:
- 注冊中心在探測的過程中,可能會由于網絡問題而出錯,但是服務其實是在正常運行狀態,也就是說會產生誤判的結果,當然這種問題,我們可以設置通過多次探測結果來確定,而不是通過一次探測結果就草草確定。
- 如果服務節點比較多,注冊中心相當于承受了比較重的探測任務,會對注冊中心的性能造成一定損失,影響它的可用性。
- 如果服務是以端口的形式開放探測接口,在服務較多的情況下可能會產生端口搶占的情況,畢竟這些服務可能會是不同團隊開發的。
后端服務主動心跳
相比較注冊中心主動探測的模式,我更喜歡使用服務主動上報心跳的模式。采用心跳的模式大體流程是這樣的:
- 后端的每個服務節點都按照配置(這個配置可以修改)每隔固定時間就主動向注冊中心發送心跳包,至于心跳包的內容可以協商約定,比如有的系統只發送ping命令,有的會發送比較詳細的服務狀態,比如cpu使用率,內存使用率等信息,然后注冊中心就可以根據這些信息來做更精確的流量分配工作,比如,可以讓資源充沛的服務節點承擔更多的流量。
- 注冊中心在接收到服務節點的心跳包之后,可以以滑動窗口的形式給服務節點續約時間(存活時間),只要服務節點不停的發送心跳包,注冊中心就可以判定這個節點一直在正常運行。
當然這個流程中也會有意外情況發生,比如由于網絡情況,某個服務節點上報心跳失敗,但是服務是在正常運行的,這種場景下,最直接的解決方案是:注冊中心判斷服務存活的時間窗口大于上報時間間隔即可,比如:心跳上報時間是10秒的話,注冊中心判定服務不可用的時間窗口設置為30秒,既:三次心跳時間都沒有上報心跳,就判定服務不可用。
當然以上只是注冊中心的一個假設而已,其實系統可以結合主動探測的方式來判定服務是否可用,這樣的話,結果的正確率會更高。也就是說:當服務的某個節點,超過配置的N次心跳時間仍然沒有上報心跳數據,注冊中心可以通過主動探測的方式來再次確定服務是否處于正常運行狀態,當然,這在設計上增加了一定的復雜度,需要編寫更多的代碼。
還有一個不太常見的但是我們需要考慮的場景,假如所有的服務節點都因為網絡異常情況而發生心跳上報超時,而且主動探測失敗的情況,按照約定,注冊中心會逐步移除所有的節點信息,這樣造成的后果是系統肯定會出問題,有的時候系統設計的同時可以考慮一些保護措施,比如:當節點信息移除的數目大于一定比率的時候,就停止移除操作并且發送報警信息,這在一定程度上可以避免注冊中心無節點數據的情況發生,當然客戶端也可以有這樣的保護策略。
通知風暴
雖然這個問題在多數情況下不算是個問題,但是還是有必要提及一下。當注冊中心隨著項目的升級承擔起越來越多的服務節點的時候,服務間的調用鏈復雜度也隨之上升,伴隨而來的是新增一個節點可能要通知數十個客戶端,移除一個節點也會有類似情況發生,如果有多個服務同時發生新增或移除節點操作,注冊中心推送的消息將會更多。這樣的場景下就需要系統設計者控制注冊中心服務節點的數量來避免產生網絡風暴,這個數量具體多少可以根據服務器的峰值帶寬來確定。
本文轉載自微信公眾號「 架構師修行之路」,可以通過以下二維碼關注。轉載本文請聯系 架構師修行之路公眾號。