數(shù)據(jù)挖掘技術(shù)在軌跡數(shù)據(jù)上的應(yīng)用實踐
每天滴滴都會為上千萬人提供出行服務(wù),在這一過程中積累了海量軌跡數(shù)據(jù)。這些軌跡數(shù)據(jù)來自于公共服務(wù),本文介紹如何利用這些數(shù)據(jù)回饋大眾,改善出行體驗。
1. 背景
首先簡要介紹一下什么是數(shù)據(jù)挖掘。數(shù)據(jù)挖掘(Data Mining)是指從大量數(shù)據(jù)中發(fā)現(xiàn)特定信息和模式的過程,也有很多人將這一過程看作知識發(fā)現(xiàn)(Knowledge Discovery in Database)。數(shù)據(jù)挖掘常用的算法手段有回歸、分類、聚類和模式發(fā)現(xiàn),工程上數(shù)據(jù)挖掘通常和大數(shù)據(jù)技術(shù)聯(lián)系在一起,工業(yè)實踐中還需要從業(yè)人員對數(shù)據(jù)中包含的領(lǐng)域知識有足夠了解。業(yè)界挖掘手段經(jīng)常用在用戶畫像、商業(yè)智能(Business Intelligence)、社群關(guān)系發(fā)現(xiàn)等場景。本文主要分享如何從海量軌跡數(shù)據(jù)中提取關(guān)鍵信息,改善用戶出行體驗。滴滴在業(yè)務(wù)運營過程中,司機端APP 會持續(xù)向后臺上傳位置信息,這些信息被用于分單、司乘碰面、導(dǎo)航、里程計費。每天滴滴都會為上千萬人提供出行服務(wù),在這一過程中積累了海量軌跡數(shù)據(jù)。這些軌跡數(shù)據(jù)不涉及用戶隱私,主要反應(yīng)了公共道路上的交通狀況和司機駕駛習慣。下面我們會具體介紹兩個典型場景。

2. 路網(wǎng)更新
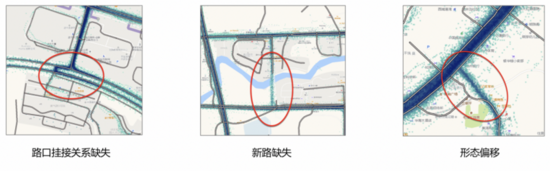
作為數(shù)字道路地圖的關(guān)鍵部分,道路交叉口是多條相互連接道路的交匯處,其幾何特征和拓撲屬性的精確性在移動導(dǎo)航和其他位置服務(wù)中起著重要作用。隨著城市發(fā)展,交叉口的更新越來越頻繁,主要包含掛接關(guān)系變更、新路、形態(tài)變更,這類拓撲錯誤如果不能及時檢測及更新,會影響路網(wǎng)匹配、路徑規(guī)劃、導(dǎo)航播報等基于路網(wǎng)數(shù)據(jù)的地圖服務(wù),產(chǎn)生導(dǎo)航繞路、播報不合理等用戶體驗問題。
▍2.1 技術(shù)挑戰(zhàn)
交叉口拓撲更新可以抽象成這樣一個問題:路口范圍內(nèi)的軌跡矢量模式與路網(wǎng)是否匹配?為此,需要解決以下幾個關(guān)鍵問題:第一,軌跡數(shù)據(jù)包含了大量噪聲,如何進行有效去噪;第二,路口位置及范圍如何確定;第三,軌跡矢量模式如何表達以及如何與路網(wǎng)差分。為了解決以上問題,我們設(shè)計出的算法框架如下,包含三個核心模塊:軌跡質(zhì)量提升,路口影響區(qū)域檢測和拓撲結(jié)構(gòu)校準模塊。相關(guān)工作發(fā)表在數(shù)據(jù)挖掘與數(shù)據(jù)庫技術(shù)頂級學(xué)術(shù)會議 International Conference on Data Engineering (ICDE) 2020上。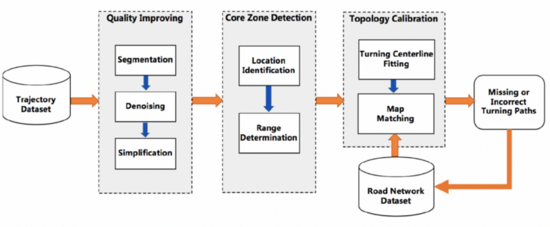
▍ 2.2 軌跡質(zhì)量提升原始軌跡數(shù)據(jù)可能受設(shè)備故障、信號不佳等因素影響導(dǎo)致采集到的定位信息存在漂移甚至異常,我們根據(jù)前后軌跡點的距離和時間間隔進行軌跡段的分割,保證同一軌跡段在時空上具有連續(xù)性;此外,車輛在路口一般會因為等紅綠燈或交通擁堵停留,導(dǎo)致在短距離范圍內(nèi)產(chǎn)生大量具有不同方向的位置信息(噪聲),不僅增加了路口檢測的計算開銷,還給檢測精度帶來較大影響。
針對這一問題,我們基于軌跡點的密度(時間密度、空間密度)進行數(shù)據(jù)過濾,并對局部自相交軌跡段進行分段,最后通過Douglas Peucker算法提取軌跡段關(guān)鍵形狀點,在保留軌跡轉(zhuǎn)向特征的同時,對數(shù)據(jù)實現(xiàn)了壓縮。因此,通過軌跡分段、去噪、壓縮的預(yù)處理,實現(xiàn)了對原始軌跡數(shù)據(jù)的質(zhì)量提升。
▍2.3 交叉口位置及范圍生成
為了檢測道路交叉口影響區(qū)內(nèi)的詳細拓撲信息,首先需要識別道路交叉口的核心區(qū)域,即路口位置和覆蓋范圍。考慮到不同路口大小不一,并且路口范圍內(nèi)軌跡通常具有減速、轉(zhuǎn)向等特征,我們設(shè)計了一套基于四叉樹空間劃分和Mean-shift的自適應(yīng)路口位置檢測算法。在搜索道路交叉口單元的過程中,將四叉樹的最小邊長設(shè)置為25米,并從200米大小邊長開始的層(即從四叉樹底部開始的第四層)搜索道路交叉口單元。由于交叉口中心位置的軌跡往往比路段具有更多的轉(zhuǎn)向與較低的轉(zhuǎn)速,我們對每個網(wǎng)格單元中的所有特征點(軌跡壓縮獲得)執(zhí)行速度分析和基于方向的DBSCAN聚類,篩選潛在的道路交叉口網(wǎng)格單元。隨后,鑒于Mean-Shift算法可以在聚類過程中同時檢測出密度中心,我們通過該算法,結(jié)合候選交叉口單元內(nèi)的軌跡點識別路口的中心位置。
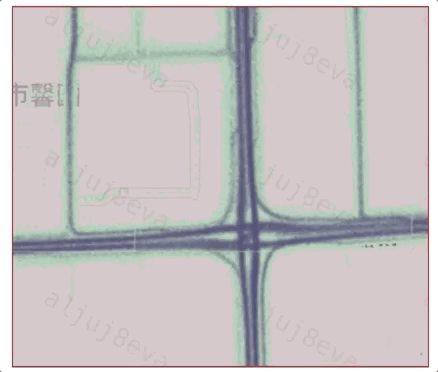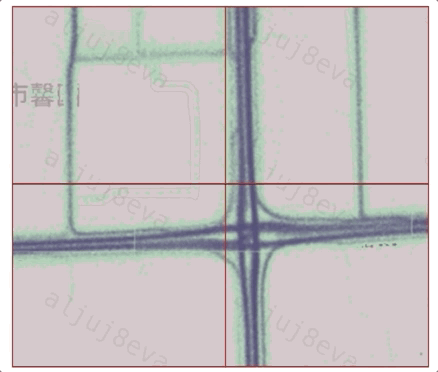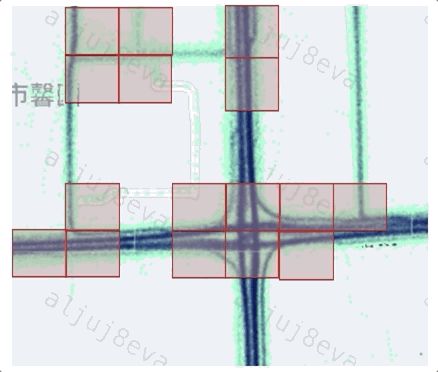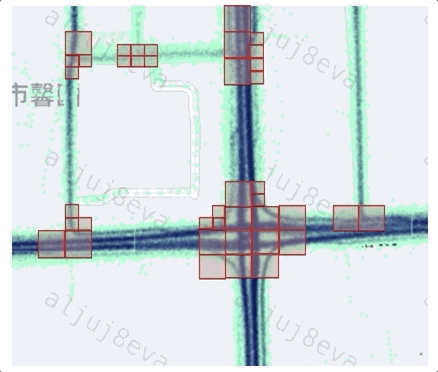
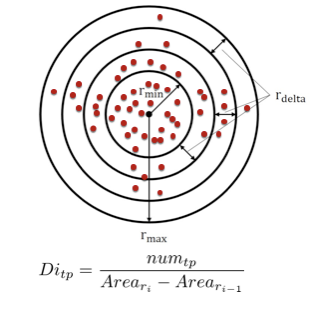
不同路口其形狀有較大差異,如何更通用地基于軌跡數(shù)據(jù)確定路口的核心區(qū)范圍?實質(zhì)上道路交叉口的中心位置附近并不總是具有相對于路段區(qū)域更多轉(zhuǎn)向行為,例如,環(huán)島和立交橋。本文中我們利用環(huán)狀幾何模型逐層檢測路口覆蓋范圍。對于一個路口而言,越到核心區(qū)邊緣的環(huán)包含的轉(zhuǎn)向點密度越低、速度越大,因此該路口模型適于不同形狀路口的范圍提取。
▍2.4 拓撲結(jié)構(gòu)校準
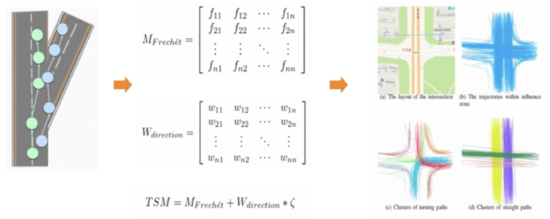
在路口范圍拓撲結(jié)構(gòu)的校準階段,我們基于檢測的路口中心位置和核心區(qū)范圍向外擴展,獲取交叉路口影響區(qū)內(nèi)的全部軌跡。我們對這些軌跡進行轉(zhuǎn)向簇提取與中心線擬合,并將擬合的轉(zhuǎn)向路徑與基準路網(wǎng)進行地圖匹配。Frechet距離適于評測曲線之間的相似性,但是對于復(fù)雜形狀的路口以及路口鄰接路段間朝向偏差較小的情況,F(xiàn)rechet表現(xiàn)不佳。鑒于此,我們將方向權(quán)重引入軌跡相似性度量中。對于任意兩條軌跡序列,分別計算起點與終點間的方向差,并結(jié)合Frechet距離生成軌跡集合的距離矩陣。基于該矩陣結(jié)合DBSCAN聚類實現(xiàn)路口范圍內(nèi)的轉(zhuǎn)向簇提取。
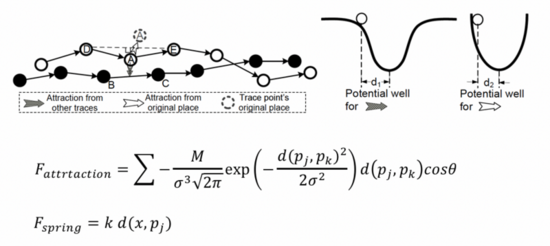
在提取轉(zhuǎn)向簇后,需要對各簇軌跡進行擬合來得到轉(zhuǎn)向矢量模式。我們采用基于Force Attraction的聚類方法獲取各簇對應(yīng)的轉(zhuǎn)向路徑,相比如其他依賴點信息的擬合算法如Sweeping等,F(xiàn)orce Attraction方法能夠充分運用軌跡線信息,因此對復(fù)雜轉(zhuǎn)向場景的擬合更加魯棒。Force Attraction方法首先隨機采樣簇中的一條軌跡作為參考軌跡,隨后使用同簇內(nèi)其余軌跡對參考軌跡中點的位置進行迭代調(diào)整。在調(diào)整過程中,F(xiàn)orce Attraction算法假定任意軌跡點上有吸引力和排斥力作用,通過搜索兩個力達到平衡的位置來獲得參考軌跡對應(yīng)點的新位置。由于隨機采樣軌跡容易導(dǎo)致擬合得到的中心線不精準,特別是當隨機采樣的參考軌跡遠離實際道路中心時,擬合偏差較大。因此,我們引入基于Frechet的采樣策略。具體來說,我們從簇中隨機采樣k條軌跡作為候選參考軌跡,并分別計算每個候選者與該簇的其余軌跡之間的Frechet距離。將具有最小距離和的候選軌跡視為參考軌跡。
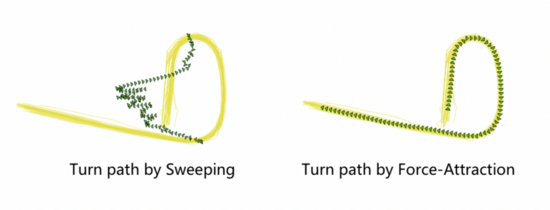
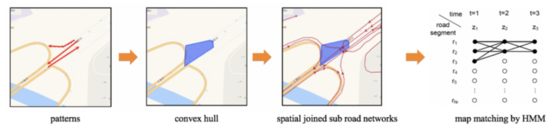
在獲得轉(zhuǎn)向路徑后,我們采用經(jīng)典的HMM算法結(jié)合基準路網(wǎng)進行地圖匹配。為加速匹配過程,我們基于每個路口的轉(zhuǎn)向路徑集生成凸包再與路網(wǎng)空間關(guān)聯(lián)。根據(jù)匹配概率得到低置信度轉(zhuǎn)向路徑,作為需修正拓撲情報。
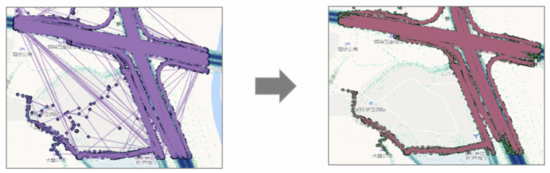
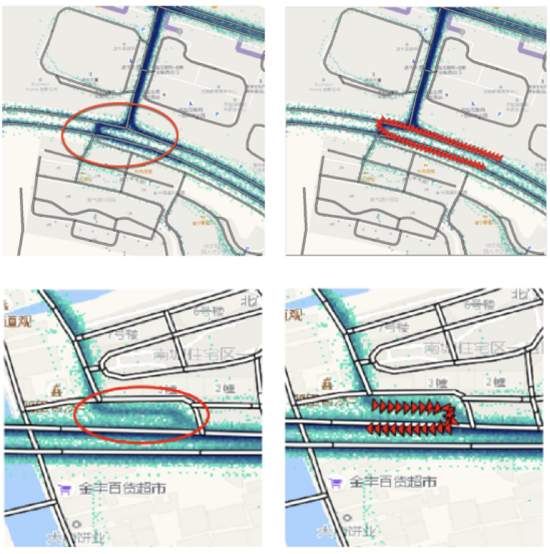
在最終的路口拓撲校準上,為了評估我們解決方案的有效性,我們基于滴滴實際軌跡數(shù)據(jù)和路網(wǎng)檢測兩種類型的錯誤拓撲:轉(zhuǎn)向路徑缺失和轉(zhuǎn)向路徑偏移。根據(jù)我們的評估,整體的精確率能夠達到70%,轉(zhuǎn)向路徑缺失和偏移的比例在1 : 5。目前該方法已經(jīng)在滴滴路網(wǎng)更新產(chǎn)線中得到應(yīng)用,下圖為兩個典型案例(路網(wǎng)為淡灰色線,軌跡分布以深藍色表示,校正的轉(zhuǎn)向路徑以紅色箭頭線突出顯示。
3. 路線偏移
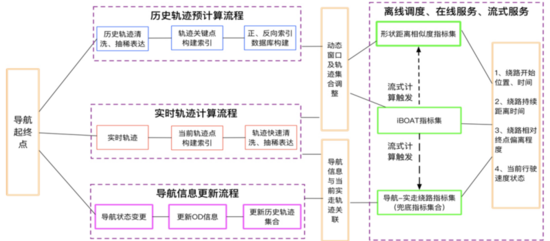
在網(wǎng)約車業(yè)務(wù)場景中,可能會出現(xiàn)司機師傅未能按照導(dǎo)航路線行駛而出現(xiàn)路線偏移的現(xiàn)象,導(dǎo)致此類場景出現(xiàn)的原因可能是路況不佳、路線不合理、道路封閉,也可能是司機發(fā)現(xiàn)了更好的路線躲避擁堵,或者是對路線不熟悉,甚至故意繞路等。挖掘此類場景對于網(wǎng)約車提升地圖用戶體驗、避免司乘糾紛、保障司乘安全具有至關(guān)重要的意義。為了解決此類問題,地圖團隊通過全局/局部的起終點(Origin-Destination,簡稱OD) 約束,基于用戶歷史軌跡行為特征建模,實時觀測目標用戶軌跡行為空間分布特征,從而檢測路線偏移行為。基于用戶軌跡的路線偏移檢測,我們最終構(gòu)建了實時觸達用戶的軌跡安全產(chǎn)品與路網(wǎng)狀態(tài)更新體系。
▍3.1 技術(shù)挑戰(zhàn)
基于OD軌跡路線偏移檢測,通常涉及到路線表征維度多樣性、OD觀測空間下歷史正常軌跡稀疏性、檢測實時性等建模問題以及TB級軌跡大數(shù)據(jù)的離線特征存儲更新、在線實時查詢等工程問題。雖然在學(xué)術(shù)研究領(lǐng)域,軌跡異常檢測已經(jīng)形成了相對成熟的解決方案與不同角度的研究積累,但在實際工程實踐會面臨復(fù)雜多樣的業(yè)務(wù)場景,具體來講:
1.路線表征維度多樣性
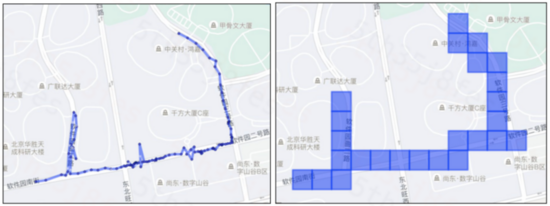
用戶軌跡路線可以用一系列有序的GPS點串表征,該方式可以保留最原始的路線信息,但是會存在軌跡飄點、冗余、無法批量高效建模的問題;也可以基于軌跡匹配道路結(jié)果進而通過一系列路段表征路線,該種表征方式最為常見,同時也會存在軌跡質(zhì)量、綁路策略而帶來的誤匹問題;還可以將GPS映射到空間瓦片表示,該方式可以有效規(guī)避以上兩類問題,但是無法精確定位路網(wǎng)問題。因此在不同的建模場景中,應(yīng)該采取不同的路線表征維度。左側(cè)藍色點串GPS軌跡的原始表示,右側(cè)表示軌跡的瓦片表示。
2. OD觀測空間下歷史正常軌跡稀疏性
由于我們是在OD的空間約束下進行軌跡建模,并且需要觀測在該空間下歷史用戶軌跡分布特征,如果用戶行程起終點下關(guān)聯(lián)的歷史用戶軌跡數(shù)量過少甚至不存在,那對于軌跡建模來講將是巨大的挑戰(zhàn)。
3. 檢測實時性
在路線偏移的場景下,不管是路網(wǎng)狀態(tài)異常還是訂單狀態(tài)異常,都要求算法能夠?qū)崟r、精確、可解釋的計算結(jié)果并觸達用戶,因此要求我們的算法要能夠?qū)崟r地對端上上報的軌跡點進行狀態(tài)判定。
為了解決異常路線偏移檢測的問題,考慮到不同的產(chǎn)品及業(yè)務(wù)需求,我們設(shè)計并完成了以下兩大類檢測解決方案,下面進行簡單的介紹。
▍3.2 "少而不同"繞路檢測
該類場景主要是檢測單一、少數(shù)繞路訂單的異常狀態(tài),該類訂單在OD約束下,與其他正常相同OD下其他正常訂單軌跡空間分布存在明顯的差異,主要表現(xiàn)為連續(xù)地出現(xiàn)離群軌跡點,所以可以將我們的任務(wù)轉(zhuǎn)化為實時離群軌跡點檢測,檢測方法可以由以下部分組成:
- 路線形狀表達
軌跡路線形狀表達的目的主要是壓縮軌跡,同時保證形狀信息和壓縮率;同時也要平滑軌跡,去除停留點與噪點。我們采用了Minimum Description Length Partition算法對軌跡進行壓縮表示,該算法通過定義角度距離、垂直距離等,拓展了傳統(tǒng)的Douglas-Peucker算法,無需定義閾值,可以自適應(yīng)增量式劃分和壓縮軌跡。
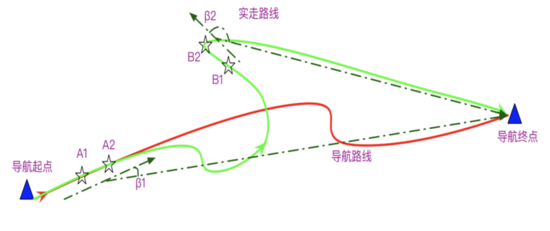
- 導(dǎo)航特征表達
在實際業(yè)務(wù)場景中,除了軌跡路線形狀之外,我們還可以實時獲取到用戶導(dǎo)航-偏航狀態(tài)的特征,通過行駛方向與導(dǎo)航起終點方位關(guān)系,可以判定用戶當前是否在朝向終點運動。紅色線條為道路路線,綠色線條為軌跡路線,β1表示A1A2導(dǎo)航起終點夾角為銳角,朝向相近,即朝向終點運動,β2反之。
- 稀疏OD軌跡Embedding
為了克服上文中提到的同OD下歷史正常軌跡稀疏性的問題,我們提出了一種基于地理空間關(guān)系學(xué)習的軌跡Embedding方案。該方案主要是在訂單起終點的約束下,建模軌跡中途經(jīng)點與起終點之間的關(guān)系,由于不涉及到具體特定軌跡,只是建模起終點與途經(jīng)點關(guān)系,因而在可以在一定程度上解決OD空間下稀疏性的問題。Embedding主要更新學(xué)習過程如下:
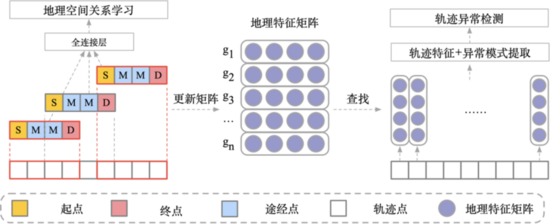
其中,地理特征矩陣更新學(xué)習的過程為:
S1)將行駛的軌跡T={p1, p2, … , pn}根據(jù)坐標映射到對應(yīng)的路網(wǎng)網(wǎng)格中。軌跡可以表示為T={g1, g2, … , gn}其中g(shù)i為行駛軌跡中坐標pi在路網(wǎng)中對應(yīng)的網(wǎng)格。
S2)使用具有固定窗口大小和固定滑動步長的滑動窗口,將軌跡T={g1, g2, … , gn}劃分為若干定長的子軌跡,如滑動窗口大小為10,滑動步長為1,則原始軌跡T可被劃分為子軌跡集合T’ = {Tj | Tj={gj, gj+1, … , gj+9}, 1≤i≤n-9}
S3)假設(shè)路網(wǎng)中有N個互不相同的路網(wǎng)網(wǎng)格,則對目標區(qū)域的所有路網(wǎng)網(wǎng)格隨機初始化兩個N d維特征矩陣,特征矩陣中的每一行為一個特征向量,分別表示對應(yīng)網(wǎng)格作為起點和終點時的特征。將兩個特征矩陣拼接后可以得到一個N 2d維的特征矩陣,用于表示對應(yīng)網(wǎng)格作為軌跡途經(jīng)點(既非起點也非終點)時的特征。
S4)將S2)中得到的每條子軌跡T={g0, g1, … , gn} 根據(jù)軌跡點性質(zhì)轉(zhuǎn)化T={S, M1, … , Mj, D},其中S=g0表示子軌跡起點,D=gn表示子軌跡終點,M1, … , Mj表示子軌跡途經(jīng)點。
S5)在起終點約束的條件下,最大化途徑點M1, … , Mj出現(xiàn)的平均對數(shù)概率,即可完成在在地理空間約束下的軌跡建模。根據(jù)軌跡點性質(zhì),分別從不同特征矩陣查找軌跡經(jīng)過的路網(wǎng)網(wǎng)格的性質(zhì)。即從起點特征矩陣中查找起點S的特征向量,為d維向量;從終點矩陣中查找終點D的特征向量,為d維向量;從途徑點矩陣中查找途徑點Mj的特征向量,為2d維向量。拼接起點S和終點D的特征向量和,即可得到2d維的起終點特征向量。
S6)通過反向傳播更新起點、途經(jīng)點和終點的特征矩陣,直到模型收斂。此時即可得到送駕區(qū)域路網(wǎng)網(wǎng)格在地理空間約束下的特征向量。
- 實時離群點檢測
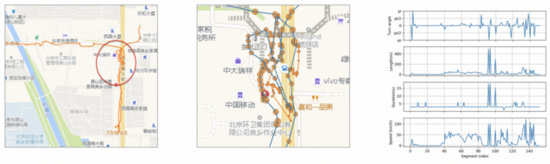
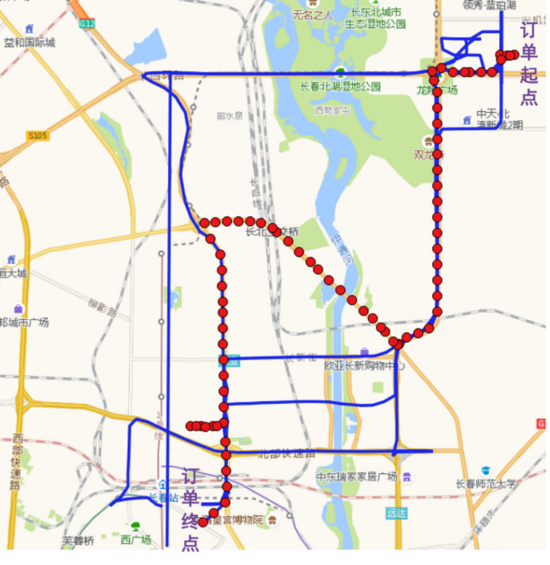
為了滿足軌跡實時異常檢測需求,需要算法能夠在系統(tǒng)輸入的一定時間窗口的軌跡之后,完成路形表達、導(dǎo)航特征提取、軌跡特征Embedding之后,立即給出在該OD空間約束下,當前行程軌跡是否處于偏移狀態(tài)以及該狀態(tài)下基于以上特征的支持度【支持度可以定義為在OD約束下,歷史正常路線途徑該瓦片的訂單數(shù)量 / OD約束下總訂單數(shù)量】,借鑒iBOAT自適應(yīng)窗口檢測在線檢測思路,類似的,我們提出了一種基于多特征表征的實時路線偏移檢測框架,具體檢測過程為:當偏航發(fā)生時,在一定時間窗口,獲取目標訂單行程軌跡,對該行程進行路形、導(dǎo)航、軌跡特征的表征與判別。下圖中,圖一藍色為歷史正常用戶實際軌跡路線,紅色為目標用戶軌跡;圖二為iBOAT自適應(yīng)窗口判別示意圖。
▍3.3 “多而不同”封路檢測
基于“少而不同”的思路針對極少數(shù)用戶軌跡偏移的異常檢測主要是為了解決司乘糾紛、軌跡安全等問題;“多而不同”主要是多數(shù)用戶在同OD空間約束下,出現(xiàn)了群體性的路線偏移,該現(xiàn)象往往意味路網(wǎng)的狀態(tài)發(fā)生了變更而導(dǎo)航依舊按照發(fā)生變更前狀態(tài)規(guī)劃,從而導(dǎo)致用戶的集體被迫繞路。因此針對路網(wǎng)狀態(tài)異常,以道路封閉為例,我們提出了一種基于 Siamese LSTM (孿生長短期記憶網(wǎng)絡(luò))與LSPD(缺失路段模式檢測方法)的軌跡時空模型來解決路網(wǎng)封閉檢測問題。相關(guān)工作發(fā)表在GIS領(lǐng)域國際會議ACM SIGSPATIAL 2019 (International Workshop on Ride-hailing Algorithms, Applications, and Systems)(SIGSPATIAL 2019 RAAS)該模型主要結(jié)構(gòu)如下:
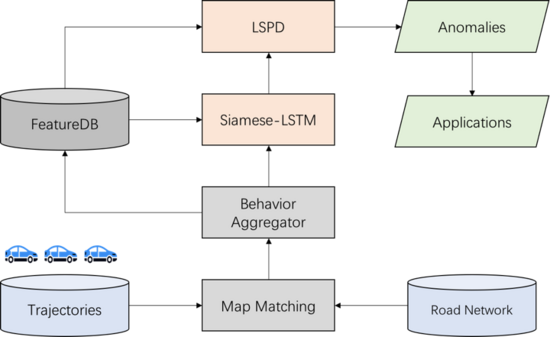
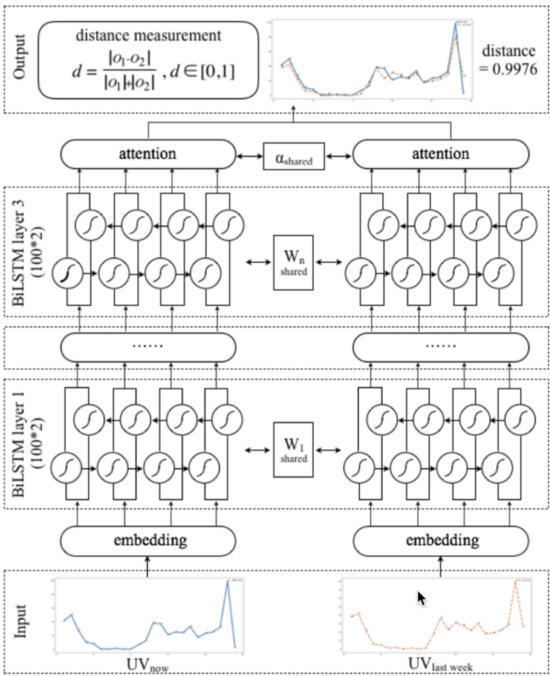
該模型主要分為兩個模塊,第一個算法模塊是基于時間序列流量信息相似性建模,該模型可以引入經(jīng)典的Siamese LSTM網(wǎng)絡(luò),并融合注意力機制與自定義損失函數(shù),實時刻畫歷史同期流量曲線與當前流量曲線的相似性,從而在線檢測流量異常。由于采取了與歷史同期(例如本周一與上周一)的流量序列建模,因而對流量自然下降及波動具備很強的魯棒性。
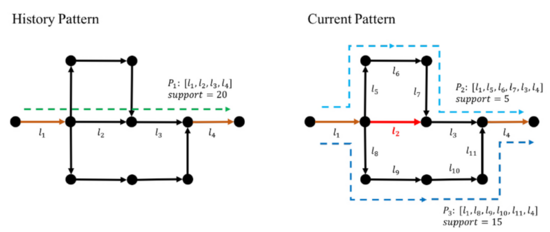
基于Siamese LSTM流量異常檢測可以對全路網(wǎng)空間的流量異常進行實時檢測,其檢測的結(jié)果需要更強的證據(jù)佐證道路異常,因此,我們設(shè)計了第二個算法模塊LSPD, 該算法側(cè)重于通過群體用戶行為的異常判別第一個算法模塊結(jié)果的可解釋性與概率性,主要思想是統(tǒng)計同OD下路線模式的分布變更,不同于軌跡異常檢測算法(iBOAT) 在OD場景下關(guān)注“少而不同“的異常軌跡,我們重點關(guān)注“多而不同“的用戶群體性異常行為,例如某時間段內(nèi)歷史用戶集中出現(xiàn)了繞路事件,則通過我們的LSPD算法模塊可以精確定位到哪些路段可能出現(xiàn)了道路封閉以及發(fā)生發(fā)生該類事件的置信度有多大。
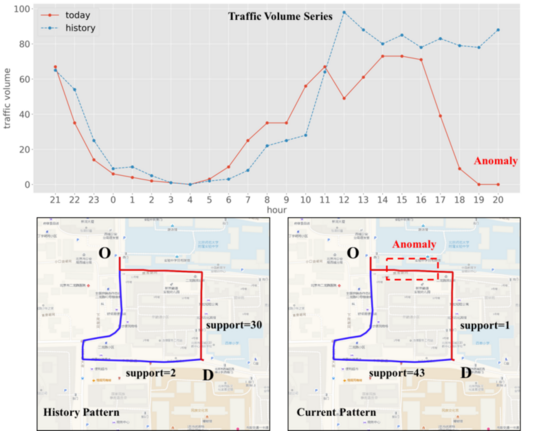
以北京市某處道路封閉事件為例,該道路在下午17時左右發(fā)生道路封閉,我們的系統(tǒng)在18時通過Siamese LSTM深度網(wǎng)絡(luò)檢測出該道路存在明顯的流量異常,異常置信度為0.99,隨后,該事例被系統(tǒng)流轉(zhuǎn)至LSPD檢測模塊尋求更多的軌跡證據(jù)佐證該道路的確存在道路異常,在該模塊,我們的算法檢測到在局部起終點(OD)的作用下,用戶的出行方式已經(jīng)發(fā)生了巨大的變化,之前多數(shù)用戶選擇右側(cè)紅色路線,而當前狀態(tài)下,用戶多選擇左側(cè)藍色路線(紅色路線的支持度從30降低到6,而藍色路線的支持度則由3上升至43),從而被系統(tǒng)整體判別該道路出現(xiàn)了道路異常,即道路封閉。
4. 總結(jié)
在當前的工業(yè)實踐中,數(shù)據(jù)挖掘也常常和一些熱門詞匯聯(lián)席出現(xiàn),比如人工智能、機器學(xué)習、大數(shù)據(jù)、數(shù)據(jù)分析、數(shù)據(jù)科學(xué)等,如下圖所示。
相比于其他概念,數(shù)據(jù)挖掘不強調(diào)應(yīng)用何種手段,更強調(diào)目的:從數(shù)據(jù)中提取信息。在這個意義上講,數(shù)據(jù)挖掘天然是交叉學(xué)科,需要從業(yè)人員具備統(tǒng)計、機器學(xué)習、大數(shù)據(jù)乃至高并發(fā)后臺服務(wù)、數(shù)據(jù)可視化等復(fù)合技能。另一方面,目前的人工智能技術(shù)水平僅僅達到刻畫相關(guān)性的階段,尚不能進行通用推理或者知識學(xué)習,所以需要從業(yè)者對研究的領(lǐng)域具備一定先驗知識,并了解如何利用這些知識從數(shù)據(jù)中提取有高價值信息。這兩個特點決定了領(lǐng)域數(shù)據(jù)挖掘的門檻非常高,這影響了數(shù)據(jù)價值的快速發(fā)掘和落地。筆者所在團隊承擔了公司內(nèi)部很多挖掘任務(wù),比如安全駕駛行為檢測、路網(wǎng)挖掘、交通事件、地理畫像、出行模式分析等等,更多的數(shù)據(jù)挖掘任務(wù)因為排期和資源限制無法快速支持,而需求方因為高技能門檻無法自行對數(shù)據(jù)進行加工和價值提取。
我們下一步的目標是嘗試將軌跡數(shù)據(jù)挖掘能力中臺化或者平臺化,能夠?qū)⑺惴ā⒐こ獭⒋髷?shù)據(jù)、可視化等能力開放出來,大幅降低數(shù)據(jù)挖掘成本,使得數(shù)據(jù)的價值能被最大化利用。實際上這一挑戰(zhàn)不是我們團隊或者公司獨有的,互聯(lián)網(wǎng)公司可能會存在無法以合適的成本從數(shù)據(jù)中提取價值的問題,導(dǎo)致數(shù)據(jù)挖掘技術(shù)只在少數(shù)高ROI場景下得到應(yīng)用。即將到來的5G和萬物互聯(lián)時代,這一問題會更加嚴重。歡迎對此感興趣的同學(xué)加入我們,一起研究和探索如何解決這些挑戰(zhàn)。