Redis突然報(bào)錯(cuò),今晚又不能回家了...
原創(chuàng)【51CTO.com原創(chuàng)稿件】今天在容器環(huán)境發(fā)布服務(wù),我發(fā)誓我就加了一行日志,在點(diǎn)擊發(fā)布按鈕后,我悠閑地掏出泡著枸杞的保溫杯,準(zhǔn)備來一口老年人大保健......
圖片來自 Pexels
正當(dāng)我一邊喝,一邊沉思今晚吃點(diǎn)啥的問題時(shí),還沒等我想明白,報(bào)警系統(tǒng)把我的黃粱美夢震碎成一地雞毛。
我急忙去 Sentry 上查看上報(bào)錯(cuò)誤日志,發(fā)現(xiàn)全都是:
- redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool
我沒動(dòng)過 Redis 啊......
內(nèi)心激動(dòng)的我無以言表,但是外表還是得表現(xiàn)鎮(zhèn)定,此時(shí)我必須的做出選擇:回滾or重啟。
我也不知道是從哪里來的蜜汁自信,我堅(jiān)信這跟我沒關(guān)系,我不管,我就要重啟。
時(shí)間每一秒對(duì)于等待重啟過程中的我來說變得無比的慢,就像小時(shí)候犯了錯(cuò),在老師辦公室等待父母到來那種感覺。
重啟的過程中我繼續(xù)去看報(bào)錯(cuò)日志,猛地發(fā)現(xiàn)一條:

什么鬼,誰打日志打成這樣?當(dāng)我點(diǎn)開準(zhǔn)備看看是哪位大俠打的日志的時(shí)候,我驚奇的發(fā)現(xiàn):
- ***************************
- APPLICATION FAILED TO START
- ***************************
- ......
- ......
原來是服務(wù)沒起來。此刻我的內(nèi)心是凌亂的,無助的,彷徨不安的。服務(wù)沒起來,哪里來的 Redis 請(qǐng)求?
能解釋通的就是應(yīng)該是來自于定時(shí)任務(wù)刷新數(shù)據(jù)對(duì) Redis 的請(qǐng)求。這里也說明另一個(gè)問題:雖然端口占用,但是服務(wù)其實(shí)還是發(fā)布起來了,不然不可能運(yùn)行定時(shí)任務(wù)。
但是還有另一個(gè)問題,Redis 為什么報(bào)錯(cuò),且報(bào)錯(cuò)的原因還是:
- java.lang.IllegalStateException: Pool not open
Jedis 線程池未初始化。項(xiàng)目既然能去執(zhí)行定時(shí)任務(wù),為什么不去初始化 Redis 相關(guān)配置呢?想想都頭疼。這里可以給大家留個(gè)坑盡管猜。
我們今天的重點(diǎn)不是項(xiàng)目為啥沒起來,而是 Redis 那些年都報(bào)過哪些錯(cuò),讓你夜不能寐。以下錯(cuò)誤都基于 Jedis 客戶端。
忘記添加白名單
之所以把這個(gè)放在第一位,是因?yàn)樯暇€不規(guī)范,親人不能睡。
上線之前檢查所有的配置項(xiàng),只要是測試環(huán)境做過的操作,一定要拿個(gè)小本本記下。
在現(xiàn)如今使用個(gè)啥啥都要授權(quán)的時(shí)代你咋能就忘了白名單這種東西呢!
無法從連接池獲取到連接
如果連接池沒有可用 Jedis 連接,會(huì)等待 maxWaitMillis(毫秒),依然沒有獲取到可用 Jedis 連接,會(huì)拋出如下異常:
- redis.clients.jedis.exceptions.JedisException: Could not get a resource from the pool
- at redis.clients.util.Pool.getResource(Pool.java:51)
- at redis.clients.jedis.JedisPool.getResource(JedisPool.java:226)
- at com.yy.cs.base.redis.RedisClient.zrangeByScoreWithScores(RedisClient.java:2258)
- ......
- java.util.NoSuchElementException: Timeout waiting for idle object
- at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:448)
- at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:362)
- at redis.clients.util.Pool.getResource(Pool.java:49)
- at redis.clients.jedis.JedisPool.getResource(JedisPool.java:226)
- ......
其實(shí)出現(xiàn)這個(gè)問題,我們從兩個(gè)方面來探測一下原因:
- 連接池配置有問題
- 連接池沒問題,使用有問題
連接池配置
Jedis Pool 有如下參數(shù)可以配置:
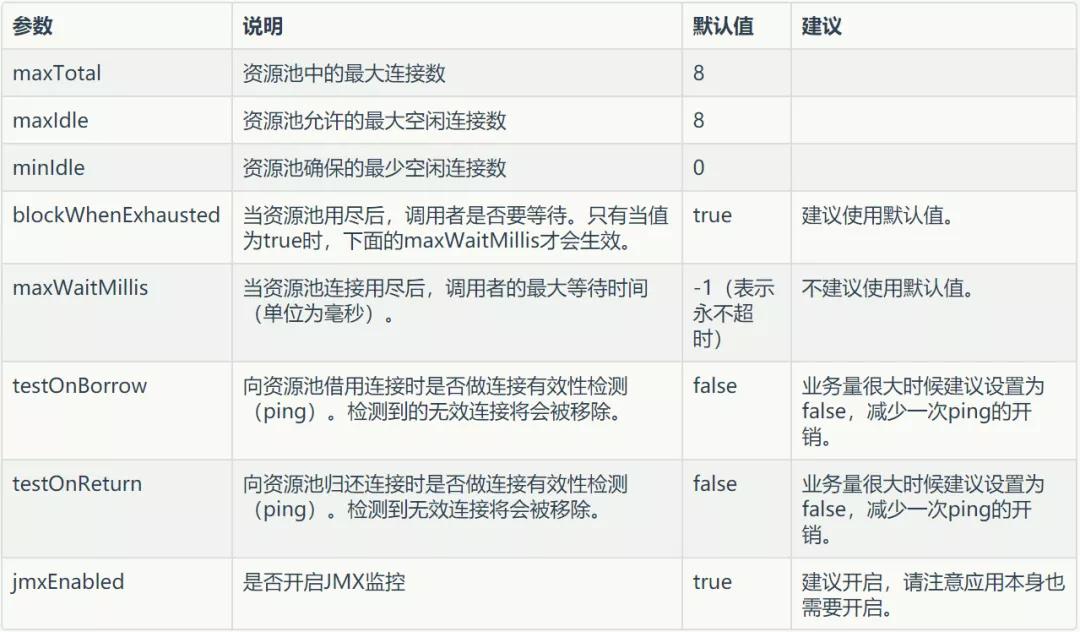
①如何確定 maxTotal 呢?
最大連接數(shù)肯定不是越大越好,首先 Redis 服務(wù)端已經(jīng)配置了允許所有客戶端連接的最大連接數(shù),那么當(dāng)前連接 Redis 的所有節(jié)點(diǎn)的連接池加起來總數(shù)不能超過服務(wù)端的配置。
其次對(duì)于單個(gè)節(jié)點(diǎn)來說,需要考慮單機(jī)的 Redis QPS,假設(shè)同機(jī)房 Redis 90% 的操作耗時(shí)都在 1ms,那么 QPS 大約是 1000。
而業(yè)務(wù)系統(tǒng)期望 QPS 能達(dá)到 10000,那么理論上需要的連接數(shù)=10000/1000=10。
考慮到網(wǎng)絡(luò)抖動(dòng)不可能每次操作都這么準(zhǔn)時(shí),所以實(shí)際配置值應(yīng)該比當(dāng)前預(yù)估值大一些。
②maxIdle 和 minIdle 如何確定?
maxIdle 從默認(rèn)值來看是等于 maxTotal。這么做的原因在于既然已經(jīng)分配了 maxTotal 個(gè)連接,如果 maxIdle
如果你的系統(tǒng)只是在高峰期才會(huì)達(dá)到 maxTotal 的量,那么你可以通過 minIdle 來控制低峰期最低有多少個(gè)連接的存活。
所以連接池參數(shù)的配置直接決定了你能否獲取連接以及獲取連接效率問題。
使用有問題
說到使用,真的就是仁者見仁智者也會(huì)犯錯(cuò),誰都不能保證他寫的代碼一次性考慮周全。
比如有這么一段代碼:
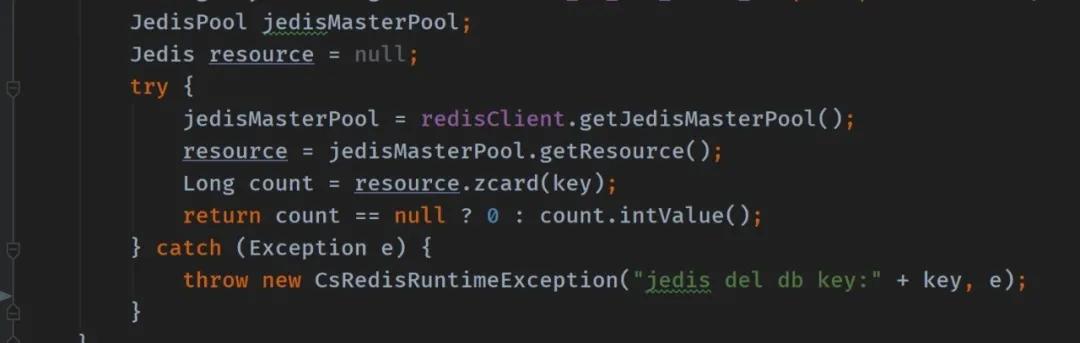
是不是沒有問題。再好好想想,這里從線程池中獲取了 Jedis 連接,用完了是不是要?dú)w還?不然這個(gè)連接一直被某個(gè)人占用著,線程池慢慢連接數(shù)就被消耗完。
所以正確的寫法:
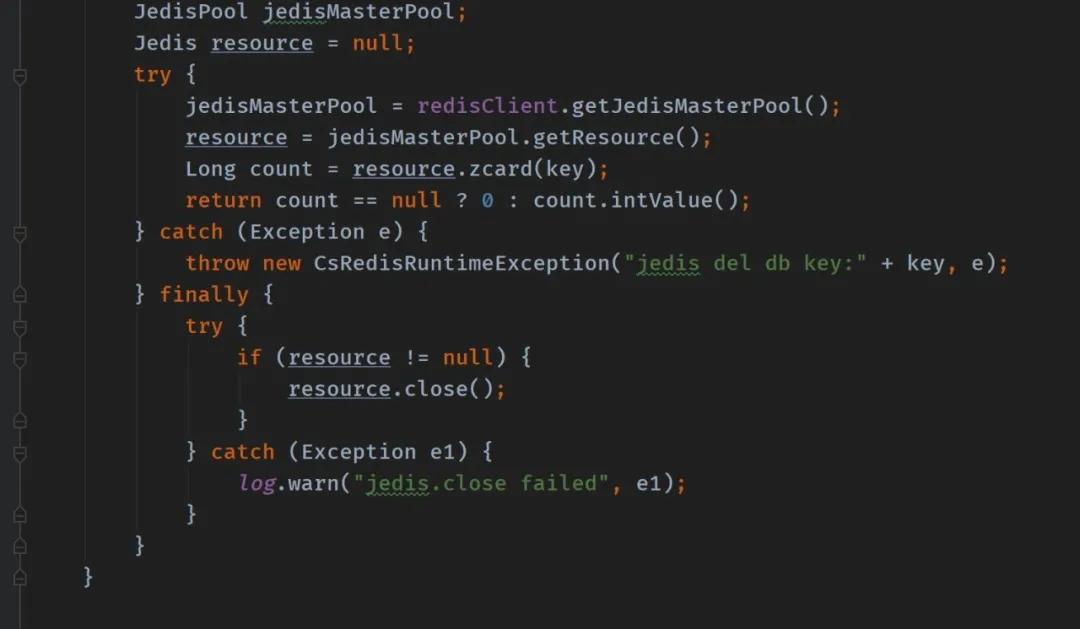
多個(gè)線程使用同一個(gè) Jedis 連接
這種錯(cuò)誤一般發(fā)生在新手身上會(huì)多一些。
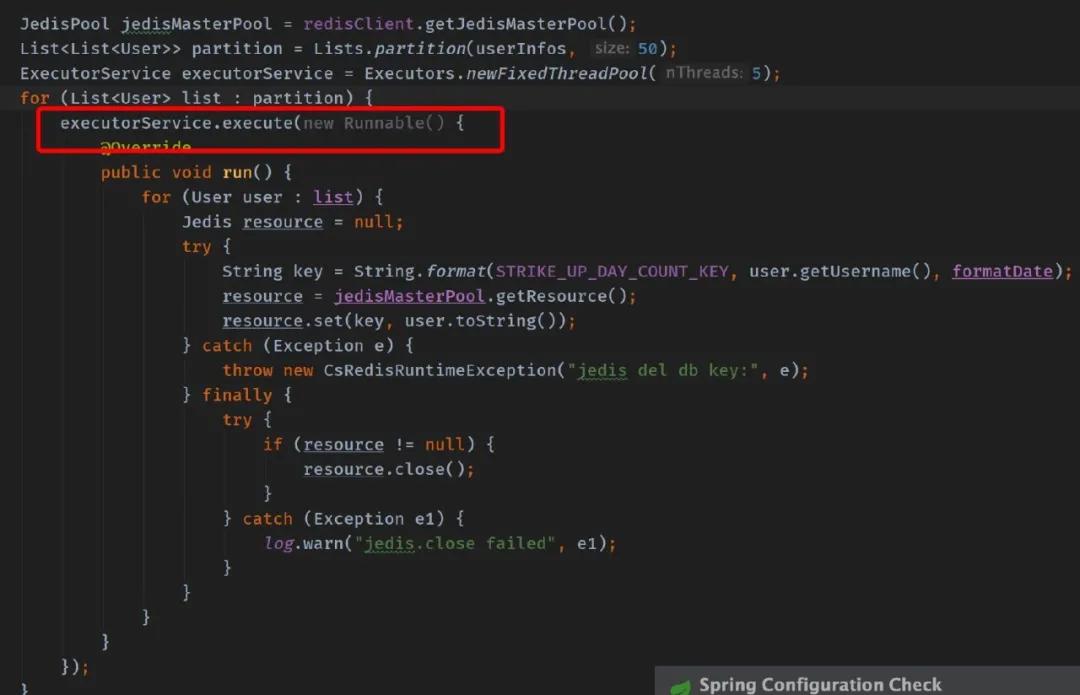
這段代碼乍看是不是感覺良好,不過你跑起來了之后就知道有多痛苦:
- redis.clients.jedis.exceptions.JedisConnectionException: Unexpected end of stream.
- at redis.clients.util.RedisInputStream.ensureFill(RedisInputStream.java:199)
- at redis.clients.util.RedisInputStream.readByte(RedisInputStream.java:40)
- at redis.clients.jedis.Protocol.process(Protocol.java:151)
- ......
這個(gè)報(bào)錯(cuò)是不是讓你一頭霧水,不知所措。出現(xiàn)這種報(bào)錯(cuò)是服務(wù)端無法分辨出一條完整的消息從哪里結(jié)束,正常情況下一個(gè)連接被一個(gè)線程使用,上面這種情況多個(gè)線程同時(shí)使用一個(gè)連接發(fā)送消息,那服務(wù)端可能就無法區(qū)分到底現(xiàn)在發(fā)送的消息是哪一條的。
類型轉(zhuǎn)換錯(cuò)誤
這種錯(cuò)誤雖然很低級(jí),但是出現(xiàn)的幾率還不低。
- java.lang.ClassCastException: com.test.User cannot be cast to com.test.User
- at redis.clients.jedis.Connection.getBinaryMultiBulkReply(Connection.java:199)
- at redis.clients.jedis.Jedis.hgetAll(Jedis.java:851)
- at redis.clients.jedis.ShardedJedis.hgetAll(ShardedJedis.java:198)
上面這個(gè)錯(cuò)乍一看是不是很吃驚,為啥同一個(gè)類無法反序列化。因?yàn)殚_發(fā)這個(gè)功能的同學(xué)用了一個(gè)序列化框架 Kryo 先將 User 對(duì)象序列化后存儲(chǔ)到 Redis。
后來 User 對(duì)象增加了一個(gè)字段,而反序列化的 User 與新的 User 對(duì)象對(duì)不上導(dǎo)致無法反序列化。
客戶端讀寫超時(shí)
出現(xiàn)客戶端讀超時(shí)的原因很多,這種情況就要綜合來判斷。
- redis.clients.jedis.exceptions.JedisConnectionException:
- java.net.SocketTimeoutException: Read timed out
- ......
出現(xiàn)這種情況的原因我們可以綜合分析:
- 首先檢查讀寫超時(shí)時(shí)間是否設(shè)置的過短,如果確定設(shè)置的很短,調(diào)大一點(diǎn)觀察一下效果。
- 其次檢查出現(xiàn)超時(shí)的命名是否本身執(zhí)行較大的存儲(chǔ)或者拉數(shù)據(jù)任務(wù)。如果數(shù)據(jù)量過大,那么就要考慮做業(yè)務(wù)拆分。
- 前面這兩項(xiàng)如果還不能確定,那么就要檢查一下網(wǎng)絡(luò)問題,確定當(dāng)前業(yè)務(wù)主機(jī)和 Redis 服務(wù)器主機(jī)是否在同機(jī)房,機(jī)房質(zhì)量怎么樣。
- 機(jī)房質(zhì)量如果還是沒問題,那能做的就是檢查當(dāng)前業(yè)務(wù)中 Redis 讀寫是否發(fā)生有可能發(fā)生阻塞,是否業(yè)務(wù)量大到這種程度,是否需要擴(kuò)容。
大 Key 造成的 CPU 飆升
我們有個(gè)新項(xiàng)目中 Redis 主要存儲(chǔ)教師端的講義數(shù)據(jù)(濃縮講義非全部), QPS 達(dá)到了15k,但是通過監(jiān)控查看命中率特別低,僅 15% 左右。這說明有很多講義是沒有被看的,Cache 這樣使用是對(duì)內(nèi)存的極大浪費(fèi)。
項(xiàng)目在上線中期就頻繁出現(xiàn) Redis 所在機(jī)器 CPU 使用率頻頻報(bào)警,單看這么低的命中率也很難想象到底是什么導(dǎo)致 CPU 超。后面觀察到報(bào)警時(shí)刻的 response 數(shù)據(jù)基本都在 15k-30 k 左右。
觀察了 Redis 的錯(cuò)誤日志,有一些頁交換錯(cuò)誤的日志。聯(lián)系起來看可以得出結(jié)論:Redis 獲取大對(duì)象時(shí)該對(duì)象首先被序列化到通信緩沖區(qū)中,然后寫入客戶端套接字,這個(gè)序列化是有成本的,涉及到隨機(jī) I/O 讀寫。
另外 Redis 官方也不建議使用 Redis 存儲(chǔ)大數(shù)據(jù),雖然官方建議值是一個(gè) value 最大值不能超過 512M,試想真的存儲(chǔ)一個(gè) 512M 的數(shù)據(jù)到緩存和到關(guān)系型數(shù)據(jù)庫的區(qū)別應(yīng)該不大,但是成本就完全不一樣。
Too Many Cluster Redirections
這個(gè)錯(cuò)誤信息一般在 cluster 環(huán)境中出現(xiàn),主要原因還是單機(jī)出現(xiàn)了命令堆積。
- redis.clients.jedis.exceptions.JedisClusterMaxRedirectionsException: Too many Cluster redirections?
- at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:97)
- at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:152)
- at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:131)
- at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:152)
- at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:131)
- at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:152)
- at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:131)
- at redis.clients.jedis.JedisClusterCommand.run(JedisClusterCommand.java:30)
- at redis.clients.jedis.JedisCluster.get(JedisCluster.java:81)
Redis 是單線程處理請(qǐng)求的,如果一條命令執(zhí)行的特別慢(可能是網(wǎng)絡(luò)阻塞,可能是獲取數(shù)據(jù)量大),那么新到來的請(qǐng)求就會(huì)放在 TCP 隊(duì)列中等待執(zhí)行。但是等待執(zhí)行的命令數(shù)如果超過了設(shè)置的隊(duì)列大小,后面的請(qǐng)求就會(huì)被丟棄。
出現(xiàn)上面這個(gè)錯(cuò)誤的原因是:
- 集群環(huán)境中 client 先通過key 計(jì)算 slot,然后查詢 slot 對(duì)應(yīng)到哪個(gè)服務(wù)器,假設(shè)這個(gè) slot 對(duì)應(yīng)到 server1,那么就去請(qǐng)求 server1。
- 此時(shí)如果 server1 整由于執(zhí)行慢命令而被阻塞且 TCP 隊(duì)列也已滿,那么新來的請(qǐng)求就會(huì)直接被拒絕。
- client 以為是 server1不可用,隨即請(qǐng)求另一個(gè)服務(wù)器 server2。server2 檢查到該 slot 由 server1 負(fù)責(zé)且 server1 心跳檢查正常,所以告訴 client 你還是去找 server1 吧。
- client 又來請(qǐng)求 server1,但是 server1 此時(shí)還是阻塞中,又回到 3。當(dāng)請(qǐng)求的次數(shù)超過拒絕服務(wù)次數(shù)之后,就會(huì)拋出異常。
再次說明,大命令要不得。對(duì)于這種錯(cuò)誤,最首要的就是要優(yōu)化存儲(chǔ)結(jié)構(gòu)或者獲取數(shù)據(jù)方式。其次,增加 TCP 隊(duì)列長度。再次,擴(kuò)容也是可以解決的。
集群擴(kuò)容之后找不到 Key
現(xiàn)在有如下集群,6 臺(tái)主節(jié)點(diǎn),6 臺(tái)從節(jié)點(diǎn):
- redis-master001~redis-master006
- redis-slave001~redis-slave006
之前 Redis 集群的 16384 個(gè)槽均勻分配在 6 臺(tái)主節(jié)點(diǎn)中,每個(gè)節(jié)點(diǎn) 2730 個(gè)槽。
現(xiàn)在線上主節(jié)點(diǎn)數(shù)已經(jīng)出現(xiàn)到達(dá)容量閾值,需要增加 3 主 3 從。
為保證擴(kuò)容后,槽依然均勻分布,需要將之前 6 臺(tái)的每臺(tái)機(jī)器上遷移出 910 個(gè)槽,方案如下:
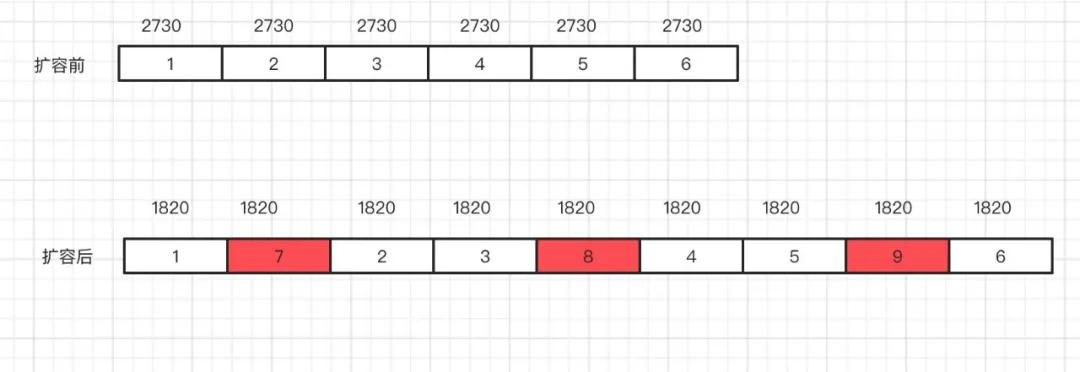
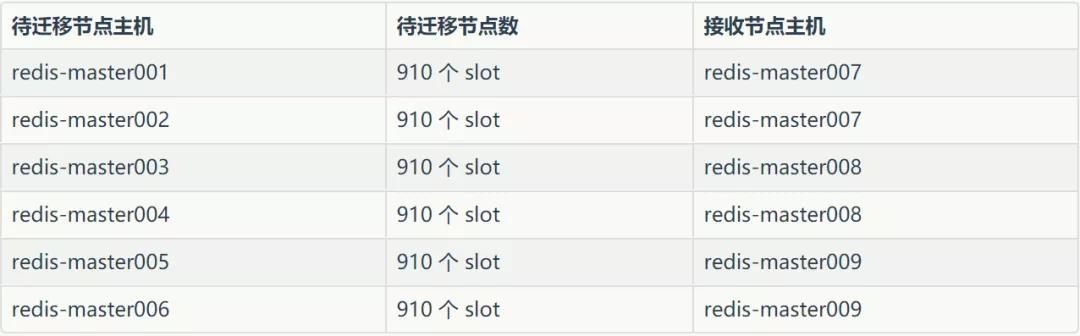
分配完之后,每臺(tái)節(jié)點(diǎn) 1820 個(gè) slot。遷移完數(shù)據(jù)之后,開始報(bào)如下異常:
- Exception in thread "main" redis.clients.jedis.exceptions.JedisMovedDataException: MOVED 1539 34.55.8.12:6379
- at redis.clients.jedis.Protocol.processError(Protocol.java:93)
- at redis.clients.jedis.Protocol.process(Protocol.java:122)
- at redis.clients.jedis.Protocol.read(Protocol.java:191)
- at redis.clients.jedis.Connection.getOne(Connection.java:258)
- at redis.clients.jedis.ShardedJedisPipeline.sync(ShardedJedisPipeline.java:44)
- at org.hu.e63.MovieLens21MPipeline.push(MovieLens21MPipeline.java:47)
- at org.hu.e63.MovieLens21MPipeline.main(MovieLens21MPipeline.java:53
報(bào)這種錯(cuò)誤肯定就是 slot 遷移之后找不到了。
我們看一下代碼:
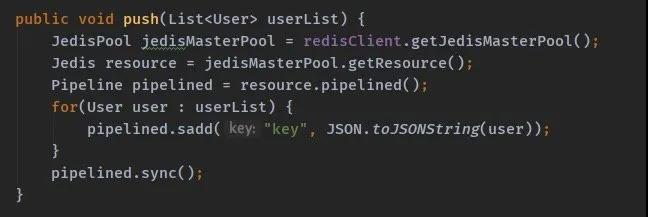
之所以這種方式會(huì)出問題還是在于我們沒有明白 Redis Cluster 的工作原理。
Key 通過 Hash 被均勻的分配到 16384 個(gè)槽中,不同的機(jī)器被分配了不同的槽,那么我們使用的 API 是不是也要支持去計(jì)算當(dāng)前 Key 要被落地到哪個(gè)槽。
你可以去看看 Pipelined 的源碼它支持計(jì)算槽嗎。動(dòng)腦子想想 Pipelined 這種批量操作也不太適合集群工作。
所以我們用錯(cuò)了 API。如果在集群模式下要使用 JedisCluster API,示例代碼如下:
- JedisPoolConfig config = new JedisPoolConfig();
- //可用連接實(shí)例的最大數(shù)目,默認(rèn)為8;
- //如果賦值為-1,則表示不限制,如果pool已經(jīng)分配了maxActive個(gè)jedis實(shí)例,則此時(shí)pool的狀態(tài)為exhausted(耗盡)
- private Integer MAX_TOTAL = 1024;
- //控制一個(gè)pool最多有多少個(gè)狀態(tài)為idle(空閑)的jedis實(shí)例,默認(rèn)值是8
- private Integer MAX_IDLE = 200;
- //等待可用連接的最大時(shí)間,單位是毫秒,默認(rèn)值為-1,表示永不超時(shí)。
- //如果超過等待時(shí)間,則直接拋出JedisConnectionException
- private Integer MAX_WAIT_MILLIS = 10000;
- //在borrow(用)一個(gè)jedis實(shí)例時(shí),是否提前進(jìn)行validate(驗(yàn)證)操作;
- //如果為true,則得到的jedis實(shí)例均是可用的
- private Boolean TEST_ON_BORROW = true;
- //在空閑時(shí)檢查有效性, 默認(rèn)false
- private Boolean TEST_WHILE_IDLE = true;
- //是否進(jìn)行有效性檢查
- private Boolean TEST_ON_RETURN = true;
- config.setMaxTotal(MAX_TOTAL);
- config.setMaxIdle(MAX_IDLE);
- config.setMaxWaitMillis(MAX_WAIT_MILLIS);
- config.setTestOnBorrow(TEST_ON_BORROW);
- config.setTestWhileIdle(TEST_WHILE_IDLE);
- config.setTestOnReturn(TEST_ON_RETURN);
- Set<HostAndPort> jedisClusterNode = new HashSet<HostAndPort>();
- jedisClusterNode.add(new HostAndPort("192.168.0.31", 6380));
- jedisClusterNode.add(new HostAndPort("192.168.0.32", 6380));
- jedisClusterNode.add(new HostAndPort("192.168.0.33", 6380));
- jedisClusterNode.add(new HostAndPort("192.168.0.34", 6380));
- jedisClusterNode.add(new HostAndPort("192.168.0.35", 6380));
- JedisCluster jedis = new JedisCluster(jedisClusterNode, 1000, 1000, 5, config);
以上介紹了看似平常實(shí)則在日常開發(fā)中只要一不注意就會(huì)發(fā)生的錯(cuò)誤。出錯(cuò)了先別慌,保留日志現(xiàn)場,如果一眼能看出問題就修復(fù),如果不能就趕緊回滾,不然再過一會(huì)就是一級(jí)事故你的年終獎(jiǎng)估計(jì)就沒了。
Redis 正確使用小技巧
①正確設(shè)置過期時(shí)間
把這個(gè)放在第一位是因?yàn)檫@里實(shí)在是有太多坑。
如果你不設(shè)置過期時(shí)間,那么你的 Redis 就成了垃圾堆,假以時(shí)日你領(lǐng)導(dǎo)看到了告警,再看一下你的代碼,估計(jì)你可能就 “沒了”!
如果你設(shè)置了過期時(shí)間,但是又設(shè)置了特別長,比如兩個(gè)月,那么帶來的問題就是極有可能你的數(shù)據(jù)不一致問題會(huì)變得特別棘手。
我就遇到過這種,用戶信息緩存中包含了除基本信息外的各種附加屬性,這些屬性又是隨時(shí)會(huì)變的,在有變化的時(shí)候通知緩存進(jìn)行更新,但是這些附加信息是在各個(gè)微服務(wù)中,服務(wù)之間調(diào)用總會(huì)有失敗的時(shí)候,只要發(fā)生那就是緩存與數(shù)據(jù)不一致之日。
但是緩存又是 2 個(gè)月過期一次,遇到這種情況你能怎么辦,只能手動(dòng)刪除緩存,重新去拉數(shù)據(jù)。
所以過期時(shí)間設(shè)置是很有技巧性的。
②批量操作使用 Pipeline 或者 Lua 腳本
使用 Pipeline 或 Lua 腳本可以在一次請(qǐng)求中發(fā)送多條命令,通過分?jǐn)傄淮握?qǐng)求的網(wǎng)絡(luò)及系統(tǒng)延遲,從而可以極大的提高性能。
③大對(duì)象盡量使用序列化或者先壓縮再存儲(chǔ)
如果存儲(chǔ)的值是對(duì)象類型,可以選擇使用序列化工具比如 protobuf,Kyro。對(duì)于比較大的文本存儲(chǔ),如果真的有這種需求,可以考慮先壓縮再存儲(chǔ),比如使用 snappy 或者 lzf 算法。
④Redis 服務(wù)器部署盡量與業(yè)務(wù)機(jī)器同機(jī)房
如果你的業(yè)務(wù)對(duì)延遲比較敏感,那么盡量申請(qǐng)與當(dāng)前業(yè)務(wù)機(jī)房同地區(qū)的 Redis 機(jī)器。同機(jī)房 Ping 值可能在 0.02ms,而跨機(jī)房能達(dá)到 20ms。當(dāng)然如果業(yè)務(wù)量小或者對(duì)延遲的要求沒有那么高這個(gè)問題可以忽略。
Redis 服務(wù)器內(nèi)存分配策略的選擇:
首先我們使用 info 命令來查看一下當(dāng)前內(nèi)存分配中都有哪些指標(biāo):
- info
- $2962
- # Memory
- used_memory:325288168
- used_memory_human:310.22M #數(shù)據(jù)使用內(nèi)存
- used_memory_rss:337371136
- used_memory_rss_human:321.74M #總占用內(nèi)存
- used_memory_peak:327635032
- used_memory_peak_human:312.46M #峰值內(nèi)存
- used_memory_peak_perc:99.28%
- used_memory_overhead:293842654
- used_memory_startup:765712
- used_memory_dataset:31445514
- used_memory_dataset_perc:9.69%
- total_system_memory:67551408128
- total_system_memory_human:62.91G # 操作系統(tǒng)內(nèi)存
- used_memory_lua:43008
- used_memory_lua_human:42.00K
- maxmemory:2147483648
- maxmemory_human:2.00G
- maxmemory_policy:allkeys-lru # 內(nèi)存超限時(shí)的釋放空間策略
- mem_fragmentation_ratio:1.04 # 內(nèi)存碎片率(used_memory_rss / used_memory)
- mem_allocator:jemalloc-4.0.3 # 內(nèi)存分配器
- active_defrag_running:0
- lazyfree_pending_objects:0
上面我截取了 Memory 信息。根據(jù)參數(shù):mem_allocator 能看到當(dāng)前使用的內(nèi)存分配器是 jemalloc。
Redis 支持三種內(nèi)存分配器:tcmalloc,jemalloc 和 libc(ptmalloc)。
在存儲(chǔ)小數(shù)據(jù)的場景下,使用 jemalloc 與 tcmalloc 可以顯著的降低內(nèi)存的碎片率。
根據(jù)這里的評(píng)測:
- https://matt.sh/redis-quicklist
保存 200 個(gè)列表,每個(gè)列表有 100 萬的數(shù)字,使用 jemalloc 的碎片率為 3%,共使用 12.1GB 內(nèi)存,而使用 libc 時(shí),碎片率為 33%,使用了 17.7GB 內(nèi)存。
但是保存大對(duì)象時(shí) libc 分配器要稍有優(yōu)勢,例如保存 3000 個(gè)列表,每個(gè)列表里保存 800 個(gè)大小為 2.5k 的條目,jemalloc 的碎片率為 3%,占用 8.4G,而 libc 為 1%,占用 8GB。
現(xiàn)在有一個(gè)問題:當(dāng)我們從 Redis 中刪除數(shù)據(jù)的時(shí)候,這一部分被釋放的內(nèi)存空間會(huì)立刻還給操作系統(tǒng)嗎?
比如有一個(gè)占用內(nèi)存空間(used_memory_rss)10G 的 Redis 實(shí)例,我們有一個(gè)大 Key 現(xiàn)在不使用需要?jiǎng)h除數(shù)據(jù),大約刪了 2G 的空間。那么理論上占用內(nèi)存空間應(yīng)該是 8G。
如果你使用 libc 內(nèi)存分配器的話,這時(shí)候的占用空間還是 10G。這是因?yàn)?malloc() 方法的實(shí)現(xiàn)機(jī)制問題,因?yàn)閯h除掉的數(shù)據(jù)可能與其他正常數(shù)據(jù)在同一個(gè)內(nèi)存分頁中,因此這些分頁就無法被釋放掉。
當(dāng)然這些內(nèi)存并不會(huì)浪費(fèi)掉,當(dāng)有新數(shù)據(jù)寫入的時(shí)候,Redis 會(huì)重用這部分空閑空間。
如果此時(shí)觀察 Redis 的內(nèi)存使用情況,就會(huì)發(fā)現(xiàn) used_memory_rss 基本保持不變,但是 used_memory 會(huì)不斷增長。
小結(jié)
今天給大家分享 Redis 使用過程中可能會(huì)遇到的問題,也是我們稍不留神就會(huì)遇到的坑。
很多問題在測試環(huán)境我們就能遇到并解決,也有一些問題是上了生產(chǎn)之后才發(fā)生的,需要你臨時(shí)判斷該怎么做。
總之別慌,你遇到的這些問題都是前人曾經(jīng)走過的路,只要仔細(xì)看日志都是有解決方案的。
作者:楊越
簡介:目前就職廣州歡聚時(shí)代,專注音視頻服務(wù)端技術(shù),對(duì)音視頻編解碼技術(shù)有深入研究。日常主要研究怎么造輪子和維護(hù)已經(jīng)造過的輪子,深耕直播類 APP 多年,對(duì)垂直直播玩法和應(yīng)用有廣泛的應(yīng)用經(jīng)驗(yàn),學(xué)習(xí)技術(shù)不局限于技術(shù),歡迎大家一起交流。
【51CTO原創(chuàng)稿件,合作站點(diǎn)轉(zhuǎn)載請(qǐng)注明原文作者和出處為51CTO.com】