













2020大數據十大關鍵詞
為加快培育數據要素市場,進一步支撐國家大數據戰略落地,推動“十四五”期間大數據產業交流與合作,2020大數據產業峰會·成果發布會于線上召開。本次大會由中國信息通信研究院、中國通信標準化協會大數據技術標準推進委員會主辦。
會上,中國信通院云大所所長何寶宏發布了《2020大數據十大關鍵詞》。
關鍵詞一:數據生產要素
2020年4月,《中共中央、國務院關于構建更加完善的要素市場化配置體制機制的意見》正式發布。《意見》指出了土地、勞動力、資本、技術、數據五個要素領域改革的方向,明確了完善要素市場化配置的具體措施。數據作為一種新型生產要素,成為了《意見》中備受關注的內容。由于數據是新型生產要素,具有無限復制、通用性強、流動性高、難確權等特點,傳統的資源管理模式無法完全適配,數據要素市場的培育,需要新的制度來提供適宜的土壤,需要在法規、機制、技術等方面大膽創新。
關鍵詞二:數據治理
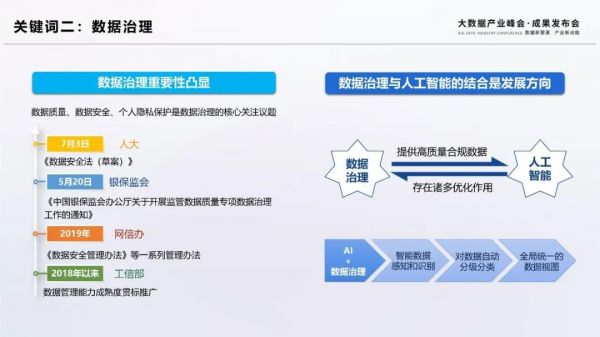
數據治理的目標是釋放數據價值,其核心議題是保障數據安全,推動數據有序管理和流動,提升數據質量。近期國家各部門密集出臺多項數據治理相關政策法規,數據治理重要性日益凸顯。例如全國人大發布《數據安全法(草案)》,中國銀保監會開展數據質量專項數據治理工作,中央網信辦出臺《數據安全管理辦法》等一系列管理辦法,工信部大力推進數據管理能力成熟度評估(DCMM)等。
智能化成為新階段數據治理工作的重要特點。一方面,數據治理為人工智能提供了高質量的數據。數據治理通過定義數據質量需求、定義數據質量測量指標、定義數據質量業務規則等環節,為深度學習等人工智能技術提供可信的數據輸入。另一方面,人工智能技術的引入提升了數據治理工作的效率,在識別主數據、數據自動分析分級、維護元數據、提升數據質量、輔助數據建模等方面都有重要作用。
關鍵詞三:隱私計算
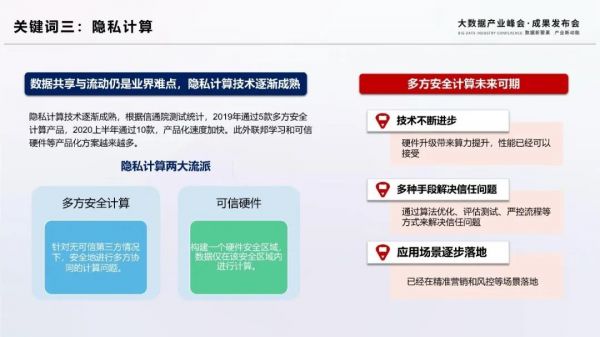
當前,數據流通不暢已成為制約我國大數據產業發展的重要問題。數據擁有者出于數據安全保密的顧慮而不愿共享數據,使得不同企業、不同機構間難以獲取對方的數據進行聯合分析或建模。為解決這一問題,大數據從業者們從多種角度進行了諸多探索。從目前發展現狀和趨勢看,隱私計算技術最有可能成為實現這一突破的關鍵。
隱私計算主要分為多方安全計算和可信硬件兩大流派,近期多方安全計算技術廣受產業關注,多家企業推出了相關產品。根據信通院測試統計,截至2020上半年,一共有15款多方安全計算產品通過評測,產品化速度明顯加快。
隨著硬件的升級和算法的優化,多方安全計算產品性能不斷提升。近兩年來,密文計算的效率已經基本達到了可商用要求。而產品供應商需要通過多種方式來解決用戶的信任問題,例如產品算法優化、第三方評估測試、嚴控流程等。目前,多方安全計算產品已經在精準營銷和金融風控等場景落地,基于可信執行環境、聯邦學習的產品逐漸增多,整體隱私計算技術未來可期。
關鍵詞四:一體化大數據平臺
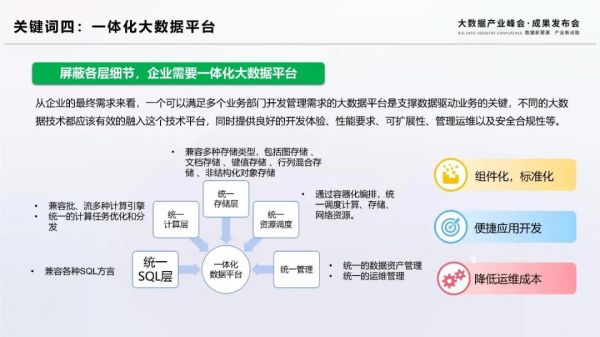
大數據技術經過10多年的發展,發展出豐富的技術棧,超過100多款開源技術,覆蓋查詢引擎、計算引擎、存儲引擎、數據集成、數據管理等多個方向,每一方向都有多種同類技術可供選擇,給企業的集成使用帶來了很大挑戰。從企業的最終需求來看,一個可以滿足多個業務部門開發管理需求的大數據平臺是支撐數據驅動業務的關鍵,這也就是一體化大數據平臺。將SQL層、計算層、存儲層、資源調度層、管理層有機的整合在一起,通過組件化和標準化的設計,提供便捷的開發能力和豐富的運維能力,成為一體化大數據平臺的重要特征。例如Cloudera的CDP、阿里巴巴的MaxComupte、星環的TDH、華為的FusionInsight,都是一體化大數據平臺的典型代表。
關鍵詞五:DataOps
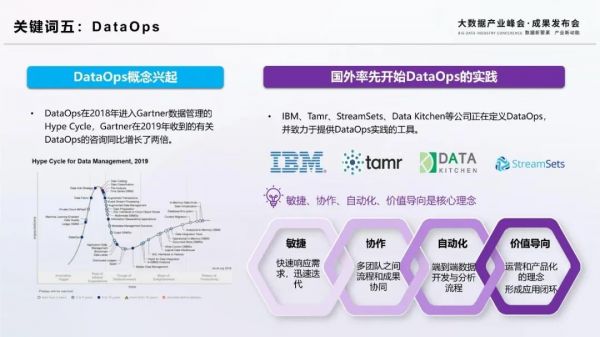
DataOps(數據運營)概念借鑒于DevOps,已經連續兩年入選Gartner數據管理的Hype Cycle,國際上IBM、Data Kitchen、StreamSets等公司均對DataOps進行了定義,并提供可以進行DataOps實踐的工具。DataOps是一種協作式數據管理實踐,將數據開發、管理、分析、運營融于一體的方法論,敏捷、協作、自動化、價值導向是DataOps的核心理念。因此,DataOps也成為了驅動數據中臺良好運轉的關鍵。在DataOps中,數據團隊需要以價值實現為導向,以持續運營的思維來主動賦能業務團隊。DataOps注重數據工程師、數據分析師、數據科學家、業務人員之間的協同,強調利用工具來實現數據生產的自動化,并建立監測和反饋機制,持續改進數據生產流程,最終形成應用的閉環。
關鍵詞六:數據與分析能力的平民化
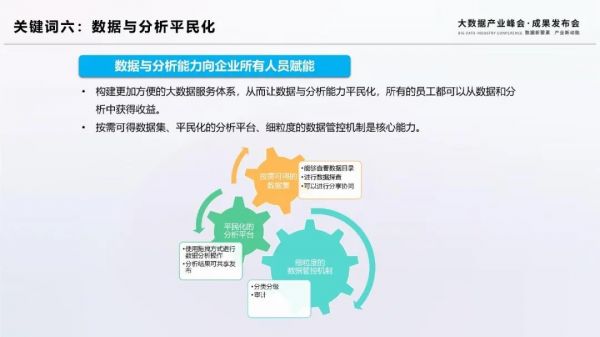
初期的大數據系統主要是為管理者提供決策依據,隨著企業數字化轉型的深入,業務人員也越來越需要深入到數據相關的工作中,數據與分析的技能不再是只需要企業IT人員具備的能力,正呈現出“平民化”的趨勢。數據與分析能力的平民化試圖為企業的每一個小細胞提供分析決策支持,加快企業整體的創新和決策能力。這就要求企業建設積極的數據文化,搭建簡單易用的數據服務和分析工具,容許業務人員發展數據技能并與他人共享成果。其核心能力包括形成按需可得的數據集,簡單易操作的分析工具,以及建立完備的數據管控機制。
關鍵詞七:計算與存儲分離

存算分離正在成為大數據與云數據庫架構變化的趨勢。傳統的存算一體模式下,數據可以“就地計算”,減少了網絡開銷,但在能力擴充方面需要同時進行,從而產生了資源浪費。在存算分離架構下,存儲層和計算層可以根據需求分別進行擴展,解決了混合計算存儲帶來資源浪費問題,也可以更好的與云平臺融合,適應云計算的發展趨勢。例如,Snowflake數據倉庫最早提出了獨特的存儲、計算以及管理服務分離的架構,使得計算層與緩存層并不強耦合,非常符合云化的思想,為現代數倉發展指明了道路。AWS的數據湖產品,通過統一集中存儲數據,減少數據的分散分布,高速網絡技術的發展,使得數據搬遷的代價降低。在數據庫端,國內外云廠商近兩三年來都研發了存算分離的產品,包括AWS的Aurora,阿里的PolarDB,騰訊的CynosDB等,為存儲和計算帶來了更好的擴展自由度和更佳的性能。
關鍵詞八:分布式數據庫
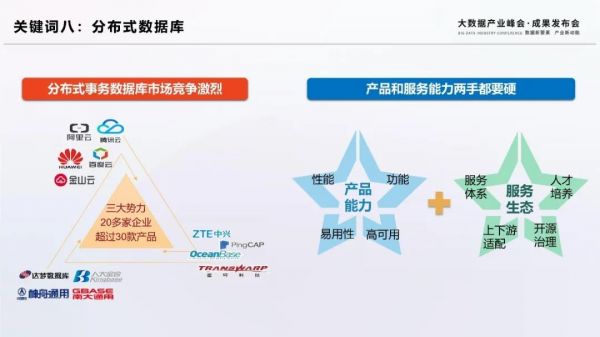
進入2020年,國內數據庫市場競爭加劇,更多廠商涌入賽道。在這之中,分布式數據庫成為諸多廠商布局的熱點。據統計,國內目前有30多款分布式事務數據庫產品,其中大多數產品都是基于開源技術進行二次開發。云數據庫廠商、創業企業和傳統數據庫企業三大勢力,聚焦金融、電信、政府等行業,提供公有云和私有交付兩種模式。為了在競爭中勝出,供應商一方面需要構建過硬的產品能力,不斷在實踐中打磨產品的功能、性能、高可用能力。另一方面需要構筑完善的服務生態,與外部服務商建立緊密合作關系,搭建咨詢、實施、運維服務體系,做好上下游的適配,推動人才的培養。
關鍵詞九:圖數據庫
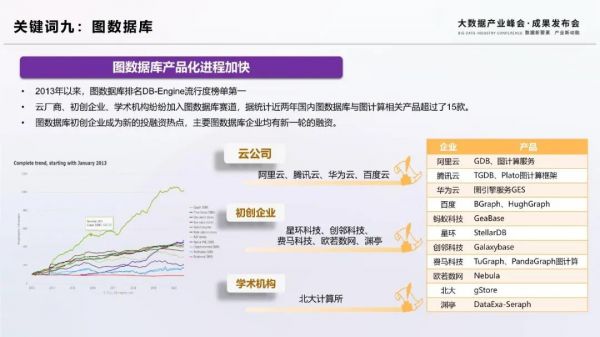
圖數據庫是以節點和邊的形式對數據關系進行存儲的數據庫,擅長處理相互關聯的數據,在社交、推薦系統等很多場景下有大量應用。2013年以來,圖數據庫一直在DB-Engine流行度排行榜上一騎絕塵,廣受開發者追捧,國外已經發展出數十款圖數據庫開源項目和商業產品。然而,國內市場一直未能迅速發展。2019年以來,國內圖數據庫產品研發速度迅速加快,兩年內推出的圖數據庫與圖計算相關產品超過了15款。特別是2020年以來,大型互聯網企業(阿里云、騰訊云)紛紛推出圖數據庫和圖計算的服務。圖數據庫賽道也誕生了諸多創業公司,并成為投融資熱點。知識圖譜、金融風控、公共安全等一些場景已經有了落地案例。
關鍵詞十:大數據服務體系
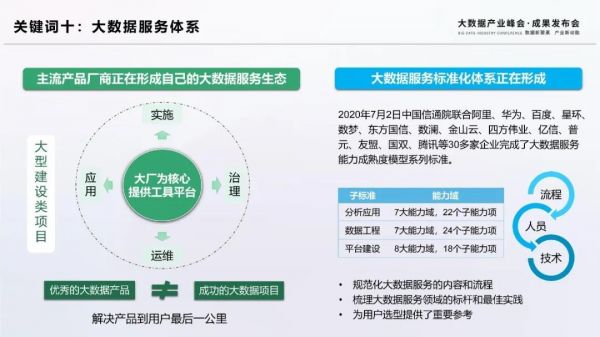
優秀的大數據產品并不等于成功的大數據項目,從產品到應用離不開實施、部署、運維等服務能力。主流的大數據產品廠商非常重視服務生態的構建,紛紛聯合外圍服務企業,圍繞自身的產品形成咨詢、實施、治理、應用等服務體系。然而,企業的大數據服務能力高低不一,存在流程不規范,人員實施經驗不足,項目管理混亂等問題,導致不少大數據項目以失敗告終。
今年來,部分大型廠商圍繞數據服務能力提升紛紛布局,顯示出對大數據服務的高度關注。為規范大數據項目的實施,建立標準的服務流程和產出物,沉淀最佳實踐,信通院在中國通信標準協會TC601聯合阿里、星環、數夢、百度、華為、數瀾等30多家企業制定了大數據服務能力成熟度模型系列標準。該標準體系將大數據服務分為平臺建設、數據工程、分析應用三類,總共形成63個子能力域,從技術、人員、流程等維度評價企業的服務能力。目前該標準已經定稿,馬上進入評估階段。



















