













面向數據科學的5個Apache Spark最佳實踐
譯文【51CTO.com快譯】
為什么轉向Spark?
雖然我們都在談論大數據,但通常在職場闖蕩一段時間后才遇到大數據。在我供職的Wix.com,有逾1.6億個用戶在生成大量數據,因此需要擴展我們的數據流程。
雖然有其他選擇(比如Dask),但我們決定選擇Spark,原因主要有兩個:(1)它是目前的最新技術,廣泛用于大數據。(2)我們擁有Spark所需的基礎架構。
如何針對pandas人群用PySpark編寫代碼?
您可能很熟悉pandas,僅僅搞好語法可能開了個好頭,但確保PySpark項目成功還需要具備更多的條件,您要了解Spark的工作原理。
讓Spark正常工作很難,但一旦可以正常工作,它效果很棒!
Spark簡述
建議看看這篇文章,閱讀MapReduce方面的說明以便更深入的了解:《如何使用Spark處理大數據?》(https://towardsdatascience.com/the-hitchhikers-guide-to-handle-big-data-using-spark-90b9be0fe89a)。
我們在這里要了解的概念是橫向擴展。
從縱向擴展入手比較容易。如果我們有一個運行良好的pandas代碼,但后來數據對于它來說太大了,我們可能會轉移到一臺內存更多、功能更強的機器上,希望它能應付得了。這意味著我們仍有一臺機器同時在處理全部數據——這就是縱向擴展。
如果我們改而決定使用MapReduce,并將數據分成多個塊,然后讓不同的機器來處理每個塊,這就是橫向擴展。
五個Spark最佳實踐
這五個Spark最佳實踐幫助我將運行時間縮短至十分之一,并擴展項目。
1. 從小處入手——采樣數據
如果我們想讓大數據起作用,先要使用少量數據看到我們方向正確。在我的項目中,我采樣10%的數據,并確保管道正常工作,這讓我可以使用Spark UI中的SQL部分,并查看數字流經整個流程,不必等待太長的時間來運行流程。
憑我的經驗,如果您用小樣本就能達到所需的運行時間,通常可以輕松擴展。
2. 了解基礎部分:任務、分區和核心
這可能是使用Spark時要理解的最重要的一點:
1個分區用于在1個核心上運行的1個任務。
您要始終了解自己有多少分區——密切關注每個階段的任務數量,并在Spark連接中將它們與正確數量的核心進行匹配。幾個技巧和經驗法則可以幫助您做到這一點(所有這些都需要根據您的情況進行測試):
- 任務與核心之間的比例應該是每個核心約2至4個任務。
- 每個分區的大小應約為200MB–400MB,這取決于每個worker的內存,可根據需要來調整。
3. 調試Spark
Spark使用惰性求值,這意味著它在等到動作被調用后才執行計算指令圖。動作示例包括show()和count()等。
這樣一來,很難知道我們代碼中的bug以及需要優化的地方。我發現大有幫助的一個實踐是,使用df.cache()將代碼劃分為幾個部分,然后使用df.count()強制Spark在每個部分計算df。
現在使用Spark UI,您可以查看每個部分的計算,并找出問題所在。值得一提的是,如果不使用我們在(1)中提到的采樣就使用這種做法,可能會創建很長的運行時間,到時將很難調試。
4. 查找和解決偏度
讓我們從定義偏度開始。正如我們提到,我們的數據分到多個分區;轉換后,每個分區的大小可能隨之變化。這會導致分區之間的大小出現很大的差異,這意味著我們的數據存在偏度。
可以通過在Spark UI中查看階段方面的細節,并尋找最大數和中位數之間的顯著差異以找到偏度:

圖1. 很大的差異(中位數= 3秒,最大數= 7.5分鐘)意味著數據有偏度。
這意味著我們有幾個任務比其他任務要慢得多。
為什么這不好——這可能導致其他階段等待這幾項任務,使核心處于等待狀態而無所事事。
如果您知道偏度來自何處,可以直接解決它并更改分區。如果您不知道/或沒辦法直接解決,嘗試以下操作:
調整任務與核心之間的比例
如前所述,如果擁有的任務比核心更多,我們希望當更長的任務運行時,其他核心仍然忙于處理其他任務。盡管這是事實,但前面提到的比例(2-4:1)無法真正解決任務持續時間之間這么大的差異。我們可以試著將比例提高到10:1,看看是否有幫助,但是這種方法可能有其他缺點。
為數據加入隨機字符串(salting)
Salting是指用隨機密鑰對數據重新分區,以便可以平衡新分區。這是PySpark的代碼示例(使用通常會導致偏度的groupby):
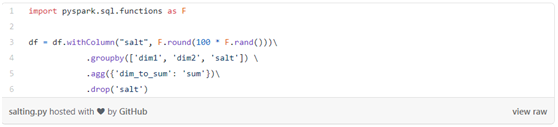
圖2
5. Spark中迭代代碼方面的問題
這是個棘手的問題。如前所述,Spark使用惰性求值,因此運行代碼時,它僅構建計算圖(DAG)。但當您有一個迭代過程時,該方法可能會很成問題,因為DAG重新打開了先前的迭代,而且變得很大。這可能太大了,驅動程序在內存中裝不下。由于應用程序卡住了,因此很難找到問題所在,但是在Spark UI中好像沒有作業在長時間運行(確實如此),直到驅動程序最終崩潰才發現并非如此。
這是目前Spark的一個固有問題,對我來說有用的解決方法是每5-6次迭代使用df.checkpoint()/ df.localCheckpoint()(試驗一番可找到適合您的數字)。這招管用的原因是,checkpoint()打破了譜系和DAG(不像cache()),保存了結果,并從新的檢查點開始。缺點在于,如果發生了什么岔子,您就沒有整個DAG來重新創建df。
原文標題:5 Apache Spark Best Practices For Data Science,作者:Zion Badash
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】













