大數據傳輸方法淺析
前言
近年來,隨著社會服務信息化的高速發展,在互聯網、物聯網、金融、物流、電磁等各方面數據都呈現指數級的增長。大數據的傳輸是大數據處理基本流程的重要一環,高性能的數據傳輸可以為后續數據分析特別是實時分析提供保障。本文簡要介紹了主流的大數據傳輸方法和多源異構數據傳輸的設計方案,為大家提供參考。
1、大數據傳輸相關背景
2003年起,Google公司相繼發表了Google FS、MapReduce、BigTable等3個系統(框架)的論文,說明了這3個產品的詳細設計方法,為后來全球的大數據發展奠定了基礎。由于數據量和效率的問題,傳統的單機存儲與計算已經不適應時代的發展,多節點的分布式存儲逐漸取而代之,這種方法可以在多個廉價的節點上同時存儲和并行計算,并且提供了很好的容錯能力。
隨著大數據技術的不斷發展,更多高性能的處理框架走上了歷史舞臺,形成了大數據生態系統。例如分布式存儲有HDFS、Hbase、hive等,分布式計算有MapReduce、Spark、Storm等,而作為該生態系統的重要組成部分,數據傳輸模塊必不可少,現在比較流行的有Kafka、Logstash、Sqoop等。
在數據傳輸的過程中,不論是類似將文件導入數據庫的離線數據傳輸,還是類似實時采集數據傳輸到數據庫進行計算的實時傳輸,我們都希望具有高速優質的傳輸效率,同時,還要求數據傳輸達到良好的安全性、穩定性、可靠性。另一方面,對于實時性要求比較高的,例如金融股票、數據可視化等方面需要獲得快速的響應,而對于傳入數據倉庫保存的可以有一定延遲。
基于最基本的用戶需求,大數據傳輸機制應當遵循以下原則:
(1)模型安全性。大數據計算一般是由幾十個甚至上百個節點組成的,在獲取數據的時候,節點與數據源之間,節點與節點之間,都會有占有較大的I/O使用率,數據傳輸之間必須滿足必要的安全性。對于保密要求較高的數據,更要建立全面的數據保護措施,以防數據泄露。
(2)傳輸可靠性。隨著計算存儲設備和數據傳輸通道的不斷升級,數據的傳輸速度和效率逐漸提高。在獲取數據源的時候,數據管道必須提供一個可靠的傳輸,以達到至少交付一次的保證。
(3)網絡自適應性。用戶和分析設備可以根據自身的需求,適應數據傳輸的服務,最大化對接數據格式,達到良好的對接效果。
2、主流傳輸方法
目前在大數據的廣泛應用中,Kafka、Logstash、Sqoop等都是傳輸數據的重要途徑,這里簡要介紹傳輸原理。
2.1Kafka
Kafka最初由Linkedin公司開發,是一個分布式、分區的、多副本的、多訂閱者,基于zookeeper協調的分布式日志系統,常見可以用于web/nginx日志、訪問日志,消息服務等等,Linkedin于2010年將該系統貢獻給了Apache基金會并成為頂級開源項目。
Kafka主要設計特點如下:
- 以時間復雜度為O(1)的方式提供消息持久化能力,即使對TB級以上數據也能保證常數時間的訪問性能。
- 高吞吐率。即使在非常廉價的商用機器上也能做到單機支持每秒100K條消息的傳輸。
- 支持Kafka Server間的消息分區,及分布式消費,同時保證每個part內的消息順序傳輸。
- 同時支持離線數據處理和實時數據處理。
- Scale out:支持在線水平擴展。
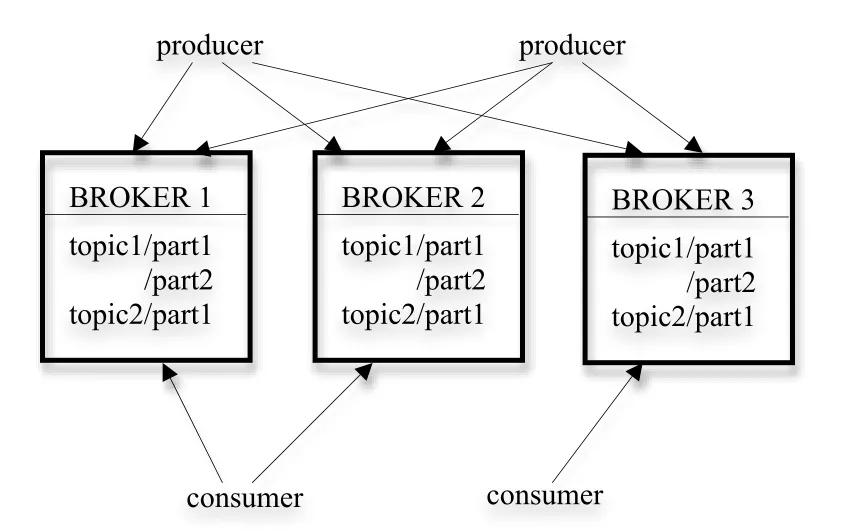
圖1 kafka的架構
圖1展示了一個典型的kafka集群的架構,每個集群中都包含若干個生產者(producer),這些生產者可以是來自數據采集設備的硬件數據源,亦可以是服務器產生的日志信息等等;每個集群中都有若干的服務代理(broker),每個服務代理一般安裝在一個節點服務器上,kafka支持平行擴展,集群中服務代理的數量越多,吞吐量也會越高。生產者生產的數據可以向一個指定的topic中寫入,消費者可以根據自己的需求,向指定的topic中拉取數據。
為了進一步提高數據傳輸的吞吐率,kafka將每個topic分為若干個part,每個part下面都會存儲對應的數據和索引文件。當創建topic時,可以指定part的數量,part數量越多,系統的吞吐量就會越大,但是也會占用更多的資源。kafka收到生產者發送的數據后,就跟根據一定的均衡策略,將數據存放到某一個part下,等待消費者來消費數據。
除此之外,kafka還為數據建立了副本,當數據節點發生意外時,其他的副本通過一定的機制擔起主part的作用,從而使系統具有高可用性。kafka提供了至少一次的交付保證,生產者發送數據到節點,節點會反饋該消息是否存儲,若未收到確認信息,生產者則會重復發送該信息;同樣的,消費者消費數據發送收到的反饋,節點記錄被消費的位置,下次消費則從該位置開始。這些機制都保證了至少一次的可靠交付。
在安全性方面,kafka使用了SSL或者SASL驗證來自客戶端(生產者和消費者)以及其他broker和工具到broker的鏈接身份,在傳輸的過程中也可以選擇對數據進行加密,對客戶端的讀寫授權,雖然可能會導致集群性能下降,但對于保密性較高的數據來說,是可以接受的。
2.2Logstash
Logstash 是免費且開放的服務器端數據處理管道,能夠從多個來源采集數據,與此同時這根管道還可以讓你根據自己的需求在中間加上濾網轉換過濾數據,然后將數據發送到用戶指定的數據庫中。
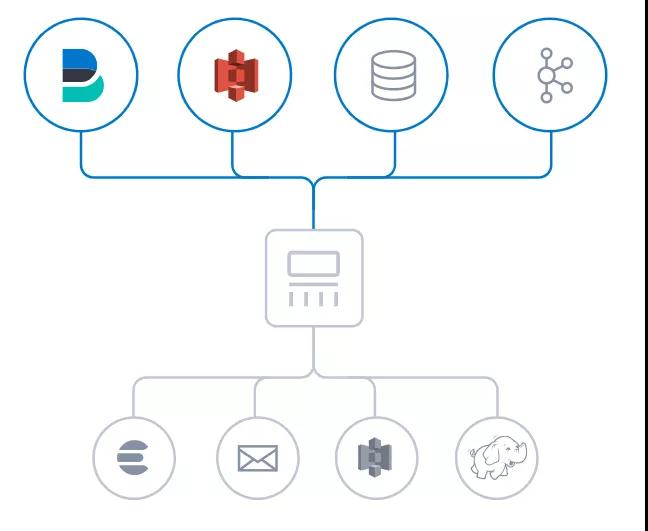
圖2 Logstash數據傳輸
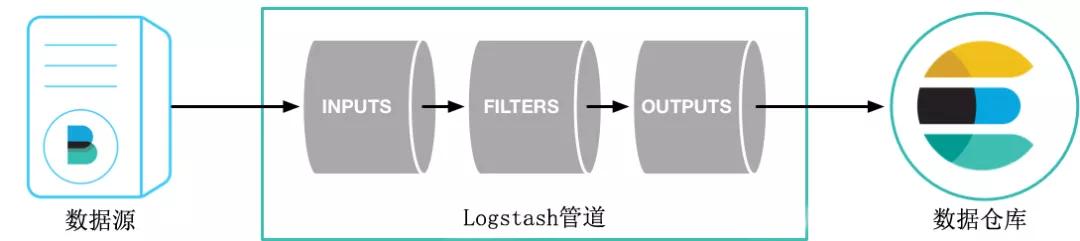
圖3 Logstash 結構
Logstash將數據流中每一條數據稱之為一個event,處理流水線有三個主要角色完成:inputs –> filters –> outputs,原始數據進入logstash后在內部流轉并不是以原始數據的形式流轉,在input處被轉換為event,在output event處被轉換為目標格式的數據。
當有一個輸入數據時,input會從文件中取出數據,然后通過json codec將數據轉換成logstash event。這條event會通過queue流入某一條pipline處理線程中,首先會存放在batcher中。當batcher達到處理數據的條件(如一定時間或event一定規模)后,batcher會把數據發送到filter中,filter對event數據進行處理后轉到output,output就把數據輸出到指定的輸出位置。輸出后還會返回ACK給queue,包含已經處理的event,queue會將已處理的event進行標記。
假如 Logstash 節點發生故障,Logstash 會通過持久化隊列來保證至少將運行中的事件送達一次。那些未被正常處理的消息會被送往死信隊列 (dead letter queue) 以便做進一步處理。由于具備了這種吸收吞吐量的能力,無需采用額外的隊列層,Logstash 就能平穩度過高峰期。此外,還能充分確保采集管道的安全性。
3、多源異構數據傳輸設計
在數據不斷壯大的過程中,我們往往會根據自身的需求,收集不同類型的數據,存儲在不同的數據庫中,使用數據時也會從不同的數據源讀取數據進行分析和處理。這些不同的存儲方式、不同的采集的系統、不同的數據格式,從簡單的文件數據庫到復雜的網絡數據庫,共同構成了異構數據源。為了將數據統一處理,根據可視化等現實需求,就需要將各個異構數據源通過一個引擎銜接起來,為數據的大批量處理和展示提供更為標準化的讀取方式。
目前,以異構數據批處理為目標的應用有springbatch、kettle、datax等,他們各自有各自的特點:
Springbatch是spring提供的一個輕量級、全面的批處理數據處理框架,無需用戶交互即可最有效地處理大量信息的自動化,復雜處理,并且提供了可重用的功能,這些功能對于處理大量的數據至關重要。
Kettle是一款國外開源的ETL工具,他可以通過Spoon來允許你運行或者轉換任務,支持從不同的數據源讀取、操作和寫入數據,在規定的時間間隔內用批處理的模式自動運行。
Datax一個異構數據源離線同步工具,致力于實現包括關系型數據庫(MySQL、Oracle等)、HDFS、hive、ODPS、HBase、FTP等各種異構數據源之間穩定高效的數據同步功能。
下面介紹一種輕量級的ETL工具,主要作用就是從不同源獲取數據,然后做統一的處理,最后再寫入各種目標源。它基本特性是:
基于Springboot開發,輕量級別、快速、簡單,入門門檻低
擴展性強,各個模塊均是獨立的,可以以插件的形式進行開發
可以通過UI界面來構建任務并操作,總體監控平臺的數據實時情況
基于Disruptor做緩沖,同時使用redis等內存緩存,保證高速處理任務
該ETL工具將整個系統分為如下模塊:Input、Reader、Transport、Convert、Writer和Output,在系統上層已經定義好各個模塊的接口,開發者根據自己的需要個性化定義自己的模塊,只需繼承上層接口即可實現模塊的嵌入。系統運行的簡化基本流程如圖4所示。
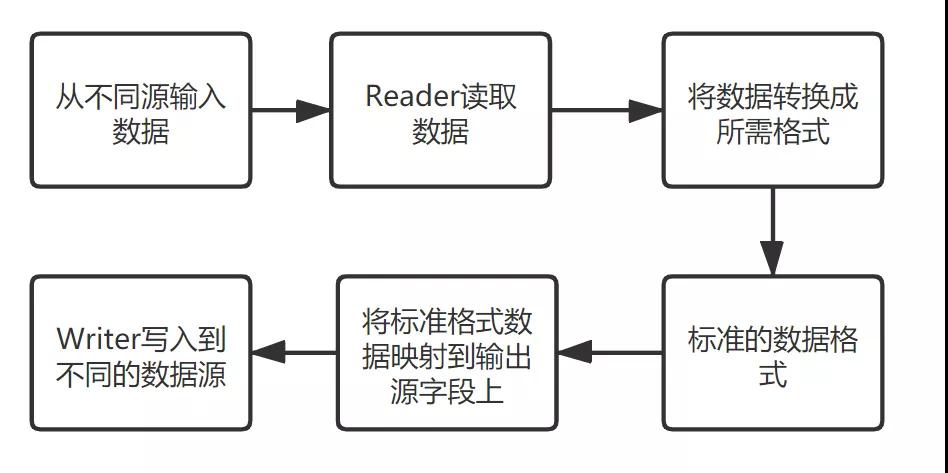
圖4 ETL工具運行簡化流程
這里所有的模塊都有一定的標準來接入系統,然后使用各數據源提供的API來讀寫數據,例如輸入可以從文件讀取、mysql、hbase、hdfs、kafka、http等,輸出同樣支持這些數據源,最終解決異構數據源相互傳輸數據不兼容的問題。
系統在應對緩沖和讀寫速度上均設置可選的策略,可以基于java的調度器,綜合當前輸入輸出的任務數量,來調整輸入輸出線程池以及線程的數量,以使數據的傳輸達到最大的性能。
4、總 結
現在數據采集的設備無處不在,在各種格式的數據匯入不同數據倉庫、數據倉庫之間互相接入數據都需要一個高效、可靠、安全的數據通道,本文介紹了大數據傳輸的一些背景知識,同時簡要描述了當前主流數據傳輸工具的應用和個性化異構數據引擎的設計問題。本文參考了一些文獻和網絡資源,對他們的觀點和技術對本文的貢獻表示感謝。
參考文獻[1] https://www.cnblogs.com/qingyunzong/p/9004509.html
[2] https://blog.csdn.net/chenleiking/article/details/73563930[3]https://gitee.com/starblues/rope/wikis/pages?sort_id=1863419&doc_id=507971