













MySQL數據庫字符編碼總結--數據傳輸編碼
概述
前面分享了mysql數據庫字符編碼中的數據存儲編碼,今天主要介紹下數據傳輸編碼方面的內容,看完后大家應該對mysql數據庫字符編碼的策略很清楚了。
01、名詞解釋
1、character_set_client:客戶端數據解析、編碼的字符集。
2、character_set_connection:連接層字符集。
3、character_set_server:服務器內部操作字符集。
4、character_set_results:查詢結果字符集。
5、character_set_database:當前數據庫的字符集。
6、character_set_system:系統源數據(字段名等)字符集。
注:
1、還有以collation_開頭的同上面對應的變量,用來描述字符序。
2、服務端編碼、解析時,是按照前一環節的編碼進行解析的,按照各自的字符集進行編碼的。
3、character_set_server是mysql數據庫內存的操作字符集。如果創建數據庫時,沒有指定數據庫的字符集,則使用character_set_server的字符集作為默認字符集;如果創建表時,沒有指定表的字符集,則使用character_set_database的字符集作為默認字符集;如果在創建字段時,沒有指定字段的字符集,則使用表的字符集作為默認字符集。
4、set names gbk;等同于同時設置character_set_client,character_set_connection,character_set_results這三個字符集。
MySQL的客戶端可以分為兩種:一種就是用C語言寫的官方客戶端——MySQL命令程序;一種就是平常程序員使用JDBC等connector API寫成的客戶端。這里以***種做分析,分成windows和Linux兩個層面。
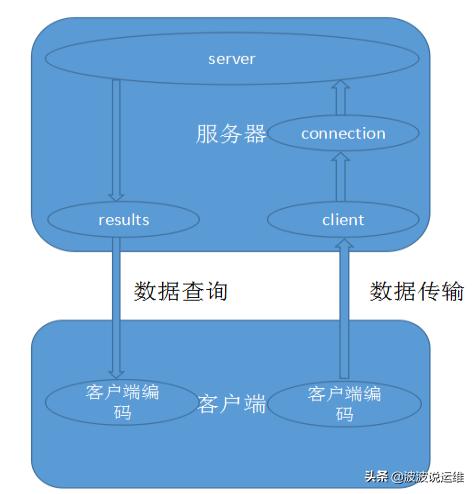
02、Windows客戶端
MySQL命令程序在Windows和Linux系統中關于字符編碼處理的部分并不等效,下圖是Windows系統的客戶端字符編碼轉換邏輯:
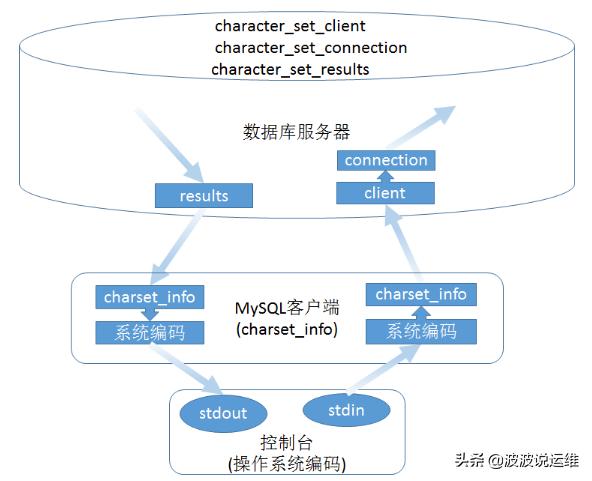
其中的三個character變量存在于服務器上,而charset_info存在于客戶端。
當客戶端啟動連接到服務器時,客戶端將根據配置參數設置charset_info為指定編碼,同時通知服務器讓服務器把三個character變量設置為相同編碼。
Windows客戶端數據傳輸流程:
1)客戶端從控制臺標準輸入讀取一行命令文本,其編碼為操作系統編碼;
2)客戶端將命令從系統編碼轉碼為客戶端charset_info變量設定的編碼;
3)客戶端將命令文本發送給服務器;
4)服務器把收到的文本解碼為character_set_client編碼,這個編碼通常與客戶端charset_info一致;
5)服務器把命令文本轉碼為character_set_connection;
6)服務器執行命令,產生結果;
7)將結果轉碼為character_set_results發送給客戶端;
8)客戶端把收到的結果解碼為charset_info編碼,這個編碼通常與character_set_results一致;
9)客戶端將結果轉碼為操作系統編碼,輸出到控制臺標準輸出。
由于在Windows平臺上MySQL程序在讀取控制臺時使用了Unicode Console Read API,所以程序從控制臺獲取的原始字符串實際上是UTF16編碼,所以這里的“操作系統編碼”并不是Windows通常的GBK,而應該看做UTF16。
03、Linux客戶端
下圖是Linux系統中的MySQL客戶端程序字符編碼轉換邏輯:
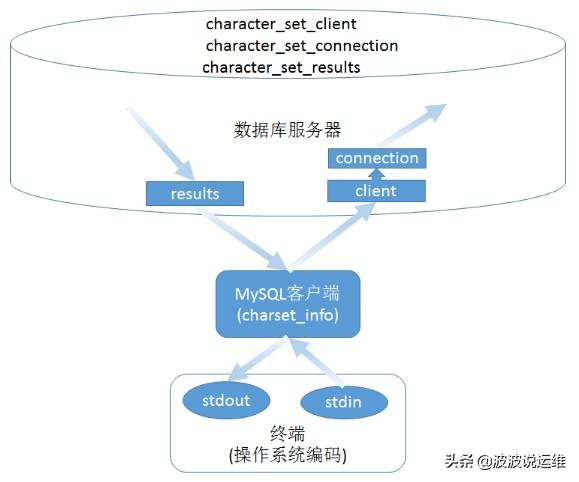
它與Windows版的不同之處就在于,它并不把來自終端標準輸入的操作系統編碼字符串強制轉換為charset_info編碼,也不會把輸出到終端的charset_info編碼結果字符串強制轉換為操作系統編碼。
也就是說,Linux平臺的MySQL程序這時候會會忽略charset_info變量。當然,這樣一來Linux客戶端的數據傳輸流程就比Windows客戶端對應地少幾步。
其實字符集出現亂碼的地方***可能在兩個地方,character_set_client和character_set_results。如果這兩個地方的編碼個客戶端編碼不一致會亂碼。數據有可能存都存不進去。***老老實實不要亂設置character_set_client這些值。如果能保持所有的都是utf8,那肯定沒問題。















