輕松構建 PyTorch 生成對抗網(wǎng)絡(GAN)
展現(xiàn)在您眼前的這幅圖像中的人物并非自真實存在,其實她是由一個機器學習模型創(chuàng)造出來的虛擬人物。圖片取自 維基百科的 GAN 條目,畫面細節(jié)豐富、色彩逼真,讓人印象深刻。
生成對抗網(wǎng)絡(GAN)是一種生成式機器學習模型,它被廣泛應用于廣告、游戲、娛樂、媒體、制藥等行業(yè),可以用來創(chuàng)造虛構的人物、場景,模擬人臉老化,圖像風格變換,以及產(chǎn)生化學分子式等等。下面兩張圖片,分別展示了圖片到圖片轉換的效果,以及基于語義布局合成景物的效果。


本文將引領讀者,從工程實踐角度出發(fā),借助 AWS 機器學習相關云計算服務,基于 PyTorch 機器學習框架,構建第一個生成對抗網(wǎng)絡,開啟全新的、有趣的機器學習和人工智能體驗。
還等什么,讓我們馬上開始吧!
主要內(nèi)容
- 課題及方案概覽
- 模型的開發(fā)環(huán)境
- 生成對抗網(wǎng)絡模型
- 模型的訓練和驗證
- 結論與總結
課題及方案概覽
下面顯示的兩組手寫體數(shù)字圖片,您是否能從中夠辨認出由計算機生成的『手寫』字體是其中哪一組?


本文的課題是用機器學習方法『模仿手寫字體』,為了完成這個課題,您將親手體驗生成對抗網(wǎng)絡的設計和實現(xiàn)。『模仿手寫字體』與人像生成的基本原理和工程流程基本是一致的,雖然它們的復雜性和精度要求有一定差距,但是通過解決『模仿手寫字體』問題,可以為生成對抗網(wǎng)絡的原理和工程實踐打下基礎,進而可以逐步嘗試和探索更加復雜先進的網(wǎng)絡架構和應用場景。
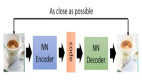
《生成對抗網(wǎng)絡》(GAN)由 Ian Goodfellow 等人在 2014年提出,它是一種深度神經(jīng)網(wǎng)絡架構,由一個生成網(wǎng)絡和一個判別網(wǎng)絡組成。生成網(wǎng)絡產(chǎn)生『假』數(shù)據(jù),并試圖欺騙判別網(wǎng)絡;判別網(wǎng)絡對生成數(shù)據(jù)進行真?zhèn)舞b別,試圖正確識別所有『假』數(shù)據(jù)。在訓練迭代的過程中,兩個網(wǎng)絡持續(xù)地進化和對抗,直到達到平衡狀態(tài)(參考:納什均衡),判別網(wǎng)絡無法再識別『假』數(shù)據(jù),訓練結束。
2016年,Alec Radford 等發(fā)表的論文 《深度卷積生成對抗網(wǎng)絡》(DCGAN)中,開創(chuàng)性地將卷積神經(jīng)網(wǎng)絡應用到生成對抗網(wǎng)絡的模型算法設計當中,替代了全鏈接層,提高了圖片場景里訓練的穩(wěn)定性。
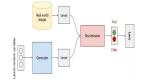
Amazon SageMaker 是 AWS 完全托管的機器學習服務,數(shù)據(jù)處理和機器學習訓練工作可以通過 Amazon SageMaker 快速、輕松地完成,訓練好的模型可以直接部署到全托管的生產(chǎn)環(huán)境中。Amazon SageMaker 提供了托管的 Jupyter Notebook 實例,通過 SageMaker SDK 與 AWS 的多種云服務集成,方便您訪問數(shù)據(jù)源,進行探索和分析。SageMaker SDK 是一套開放源代碼的 Amazon SageMaker 的開發(fā)包,可以協(xié)助您很好的使用 Amazon SageMaker 提供的托管容器鏡像,以及 AWS 的其他云服務,如計算和存儲資源。
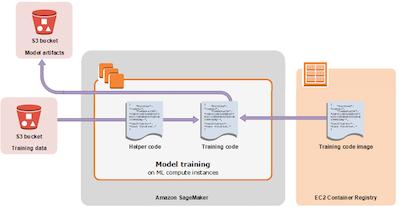
如上圖所示,訓練用數(shù)據(jù)將來自 Amazon S3 的存儲桶;訓練用的框架和托管算法以容器鏡像的形式提供服務,在訓練時與代碼結合;模型代碼運行在 Amazon SageMaker 托管的計算實例中,在訓練時與數(shù)據(jù)結合;訓練輸出物將進入 Amazon S3 專門的存儲桶里。后面的講解中,我們會了解到如何通過 SageMaker SDK 使用這些資源。
我們將用到 Amazon SageMaker、Amazon S3 、Amazon EC2 等 AWS 服務,會產(chǎn)生一定的云資源使用費用。
模型的開發(fā)環(huán)境
創(chuàng)建Notebook實例
請打開 Amazon SageMaker 的儀表板(點擊打開 北京區(qū)域 | 寧夏區(qū)域 ),請點擊Notebook instances 按鈕進入筆記本實例列表。
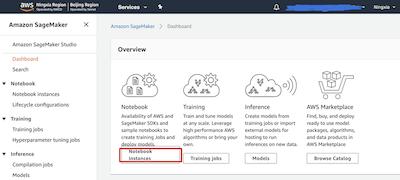
如果您是第一次使用Amazon SageMaker,您的 Notebook instances 列表將顯示為空列表,此時您需點擊 Create notebook instance 按鈕來創(chuàng)建全新 Jupyter Notebook 實例。
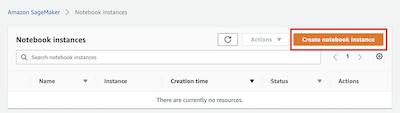
進入 Create notebook instance 頁面后,請在 Notebook instance name 字段里輸入實例名字,本文將使用 MySageMakerInstance 作為實例名,您可以選用您認為合適的名字。本文將使用默認的實例類型,因此 Notebook instance type 選項將保持為 *ml.t2.medium*。如果您是第一次使用Amazon SageMaker,您需要創(chuàng)建一個 IAM role,以便筆記本實例能夠訪問 Amazon S3 服務。請在 IAM role 選項點擊為 Create a new role。Amazon SageMaker 將創(chuàng)建一個具有必要權限的角色,并將這個角色分配給正在創(chuàng)建的實例。另外,根據(jù)您的實際情況,您也可以選擇一個已經(jīng)存在的角色。
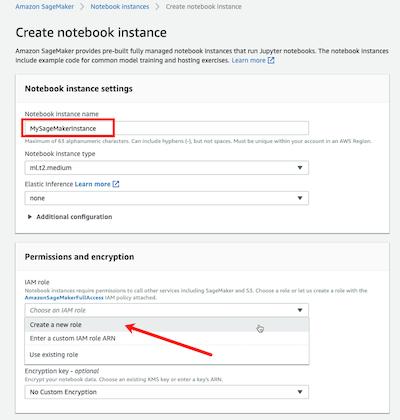
在 Create an IAM role 彈出窗口里,您可以選擇 *Any S3 bucket*,這樣筆記本實例將能夠訪問您賬戶里的所有桶。另外,根據(jù)您的需要,您還可以選擇 Specific S3 buckets并輸入桶名。點擊 Create role 按鈕,這個新角色將被創(chuàng)建。
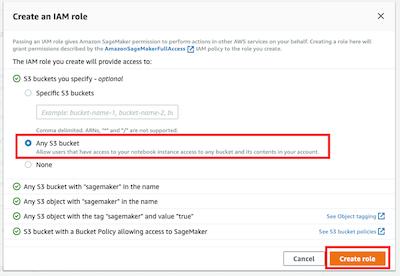
此時,可以看到 Amazon SageMaker 為您創(chuàng)建了一個名字類似 *
AmazonSageMaker-ExecutionRole-**** 的角色。對于其他字段,您可以使用默認值,請點擊 Create notebook instance 按鈕,創(chuàng)建實例。
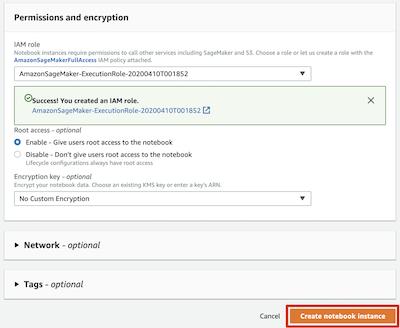
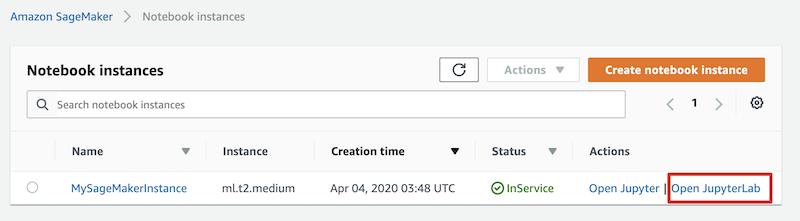
回到 Notebook instances 頁面,您會看到 MySageMakerInstance 筆記本實例顯示為 Pending 狀態(tài),這個將持續(xù)2分鐘左右,直到轉為 InService 狀態(tài)。

編寫第一行代碼
點擊 Open JupyterLab 鏈接,在新的頁面里,您將看到熟悉的 Jupyter Notebook 加載界面。本文默認以 JupyterLab 筆記本作為工程環(huán)境,根據(jù)您的需要,可以選擇使用傳統(tǒng)的 Jupyter 筆記本。
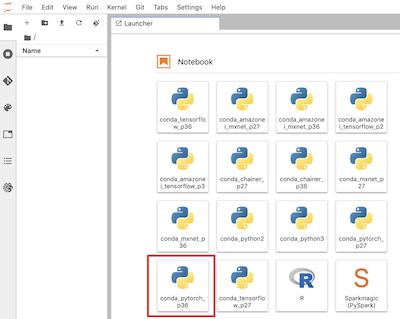
您將通過點擊 conda_pytorch_p36, 筆記本圖標來創(chuàng)建一個叫做 Untitled.ipynb 的筆記本,您可以稍后更改它的名字。另外,您也可以通過 File > New > Notebook 菜單路徑,并選擇 conda_pytorch_p36 作為 Kernel 來創(chuàng)建這個筆記本。
在新建的 Untitled.ipynb 筆記本里,我們將輸入第一行指令如下,
- import torch
- print(f"Hello PyTorch {torch.__version__}")
源代碼下載
請在筆記本中輸入如下指令,下載代碼到實例本地文件系統(tǒng)。
下載完成后,您可以通過 File browser 瀏覽源代碼結構。
本文涉及到的代碼和筆記本均通過 Amazon SageMaker 托管的 Python 3.6、PyTorch 1.4 和 JupyterLab 驗證。本文涉及到的代碼和筆記本可以通過 這里獲取。
生成對抗網(wǎng)絡模型
算法原理
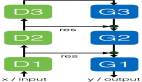
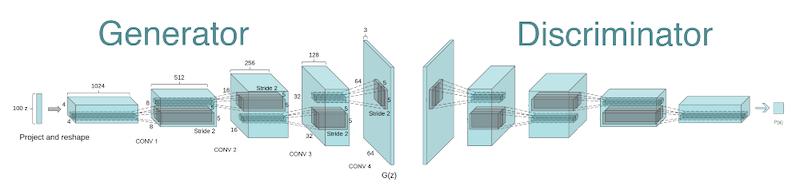
DCGAN模型的生成網(wǎng)絡包含10層,它使用跨步轉置卷積層來提高張量的分辨率,輸入形狀為 (batchsize, 100) ,輸出形狀為 (batchsize, 64, 64, 3)。換句話說,生成網(wǎng)絡接受噪聲向量,然后經(jīng)過不斷變換,直到生成最終的圖像。
判別網(wǎng)絡也包含10層,它接收 (64, 64, 3) 格式的圖片,使用2D卷積層進行下采樣,最后傳遞給全鏈接層進行分類,分類結果是 1 或 0,即真與假。
DCGAN 模型的訓練過程大致可以分為三個子過程。
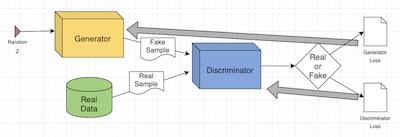
首先, Generator 網(wǎng)絡以一個隨機數(shù)作為輸入,生成一張『假』圖片;接下來,分別用『真』圖片和『假』圖片訓練 Discriminator 網(wǎng)絡,更新參數(shù);最后,更新 Generator 網(wǎng)絡參數(shù)。
代碼分析
項目目錄 byos-pytorch-gan 的文件結構如下,
文件 model.py 中包含 3 個類,分別是 生成網(wǎng)絡 Generator 和 判別網(wǎng)絡 Discriminator。
- class Generator(nn.Module):
- ...
- class Discriminator(nn.Module):
- ...
- class DCGAN(object):
- """
- A wrapper class for Generator and Discriminator,
- 'train_step' method is for single batch training.
- """
- ...
文件 train.py 用于 Generator 和 Discriminator 兩個神經(jīng)網(wǎng)絡的訓練,主要包含以下幾個方法,
- def parse_args():
- ...
- def get_datasets(dataset_name, ...):
- ...
- def train(dataloader, hps, ...):
- ...
模型的調(diào)試
開發(fā)和調(diào)試階段,可以從 Linux 命令行直接運行 train.py 腳本。超參數(shù)、輸入數(shù)據(jù)通道、模型和其他訓練產(chǎn)出物存放目錄都可以通過命令行參數(shù)指定。
- python dcgan/train.py --dataset qmnist \
- --model-dir '/home/myhome/byom-pytorch-gan/model' \
- --output-dir '/home/myhome/byom-pytorch-gan/tmp' \
- --data-dir '/home/myhome/byom-pytorch-gan/data' \
- --hps '{"beta1":0.5,"dataset":"qmnist","epochs":15,"learning-rate":0.0002,"log-interval":64,"nc":1,"nz":100,"sample-interval":100}'
這樣的訓練腳本參數(shù)設計,既提供了很好的調(diào)試方法,又是與 SageMaker Container 集成的規(guī)約和必要條件,很好的兼顧了模型開發(fā)的自由度和訓練環(huán)境的可移植性。
模型的訓練和驗證
請查找并打開名為 dcgan.ipynb 的筆記本文件,訓練過程將由這個筆記本介紹并執(zhí)行,本節(jié)內(nèi)容代碼部分從略,請以筆記本代碼為準。
互聯(lián)網(wǎng)環(huán)境里有很多公開的數(shù)據(jù)集,對于機器學習的工程和科研很有幫助,比如算法學習和效果評價。我們將使用 QMNIST 這個手寫字體數(shù)據(jù)集訓練模型,最終生成逼真的『手寫』字體效果圖樣。
數(shù)據(jù)準備
PyTorch 框架的 torchvision.datasets 包提供了QMNIST 數(shù)據(jù)集,您可以通過如下指令下載 QMNIST 數(shù)據(jù)集到本地備用。
- from torchvision import datasets
- dataroot = './data'
- trainset = datasets.QMNIST(root=dataroot, train=True, download=True)
- testset = datasets.QMNIST(root=dataroot, train=False, download=True)
Amazon SageMaker 為您創(chuàng)建了一個默認的 Amazon S3 桶,用來存取機器學習工作流程中可能需要的各種文件和數(shù)據(jù)。 我們可以通過 SageMaker SDK 中 sagemaker.session.Session 類的 default_bucket 方法獲得這個桶的名字。
- from sagemaker.session import Session
- sess = Session()
- # S3 bucket for saving code and model artifacts.
- # Feel free to specify a different bucket here if you wish.
- bucket = sess.default_bucket()
SageMaker SDK 提供了操作 Amazon S3 服務的包和類,其中 S3Downloader 類用于訪問或下載 S3 里的對象,而 S3Uploader 則用于將本地文件上傳至 S3。您將已經(jīng)下載的數(shù)據(jù)上傳至 Amazon S3,供模型訓練使用。模型訓練過程不要從互聯(lián)網(wǎng)下載數(shù)據(jù),避免通過互聯(lián)網(wǎng)獲取訓練數(shù)據(jù)的產(chǎn)生的網(wǎng)絡延遲,同時也規(guī)避了因直接訪問互聯(lián)網(wǎng)對模型訓練可能產(chǎn)生的安全風險。
- from sagemaker.s3 import S3Uploader as s3up
- s3_data_location = s3up.upload(f"{dataroot}/QMNIST", f"s3://{bucket}/data/qmnist")
訓練執(zhí)行
通過
sagemaker.getexecutionrole() 方法,當前筆記本可以得到預先分配給筆記本實例的角色,這個角色將被用來獲取訓練用的資源,比如下載訓練用框架鏡像、分配 Amazon EC2 計算資源等等。
訓練模型用的超參數(shù)可以在筆記本里定義,實現(xiàn)與算法代碼的分離,在創(chuàng)建訓練任務時傳入超參數(shù),與訓練任務動態(tài)結合。
- hps = {
- "learning-rate": 0.0002,
- "epochs": 15,
- "dataset": "qmnist",
- "beta1": 0.5,
- "sample-interval": 200,
- "log-interval": 64
- }
sagemaker.pytorch 包里的 PyTorch 類是基于 PyTorch 框架的模型擬合器,可以用來創(chuàng)建、執(zhí)行訓練任務,還可以對訓練完的模型進行部署。參數(shù)列表中, train_instance_type 用來指定CPU或者GPU實例類型,訓練腳本和包括模型代碼所在的目錄通過 source_dir 指定,訓練腳本文件名必須通過 entry_point 明確定義。這些參數(shù)將和其余參數(shù)一起被傳遞給訓練任務,他們決定了訓練任務的運行環(huán)境和模型訓練時參數(shù)。
- from sagemaker.pytorch import PyTorch
- estimator = PyTorch(role=role,
- entry_point='train.py',
- source_dir='dcgan',
- output_path=s3_model_artifacts_location,
- code_location=s3_custom_code_upload_location,
- train_instance_count=1,
- train_instance_type='ml.c5.xlarge',
- train_use_spot_instances=True,
- train_max_wait=86400,
- framework_version='1.4.0',
- py_version='py3',
- hyperparameters=hps)
請?zhí)貏e注意 train_use_spot_instances 參數(shù),True 值代表您希望優(yōu)先使用 SPOT 實例。由于機器學習訓練工作通常需要大量計算資源長時間運行,善用 SPOT 可以幫助您實現(xiàn)有效的成本控制,SPOT 實例價格可能是按需實例價格的 20% 到 60%,依據(jù)選擇實例類型、區(qū)域、時間不同實際價格有所不同。
您已經(jīng)創(chuàng)建了 PyTorch 對象,下面可以用它來擬合預先存在 Amazon S3 上的數(shù)據(jù)了。下面的指令將執(zhí)行訓練任務,訓練數(shù)據(jù)將以名為 QMNIST 的輸入通道的方式導入訓練環(huán)境。訓練開始執(zhí)行過程中,Amazon S3 上的訓練數(shù)據(jù)將被下載到模型訓練環(huán)境的本地文件系統(tǒng),訓練腳本 train.py 將從本地磁盤加載數(shù)據(jù)進行訓練。
- # Start training
- estimator.fit({'QMNIST': s3_data_location}, wait=False)
根據(jù)您選擇的訓練實例不同,訓練過程中可能持續(xù)幾十分鐘到幾個小時不等。建議設置 wait 參數(shù)為 False ,這個選項將使筆記本與訓練任務分離,在訓練時間長、訓練日志多的場景下,可以避免筆記本上下文因為網(wǎng)絡中斷或者會話超時而丟失。訓練任務脫離筆記本后,輸出將暫時不可見,可以執(zhí)行如下代碼,筆記本將獲取并載入此前的訓練回話,
- %%time
- from sagemaker.estimator import Estimator
- # Attaching previous training session
- training_job_name = estimator.latest_training_job.name
- attached_estimator = Estimator.attach(training_job_name)
由于的模型設計考慮到了GPU對訓練加速的能力,所以用GPU實例訓練會比CPU實例快一些,例如,p3.2xlarge 實例大概需要15分鐘左右,而 c5.xlarge 實例則可能需要6小時以上。目前模型不支持分布、并行訓練,所以多實例、多CPU/GPU并不會帶來更多的訓練速度提升。
訓練完成后,模型將被上傳到 Amazon S3 里,上傳位置由創(chuàng)建 PyTorch 對象時提供的 output_path 參數(shù)指定。
模型的驗證
您將從 Amazon S3 下載經(jīng)過訓練的模型到筆記本所在實例的本地文件系統(tǒng),下面的代碼將載入模型,然后輸入一個隨機數(shù),獲得推理結果,以圖片形式展現(xiàn)出來。執(zhí)行如下指令加載訓練好的模型,并通過這個模型產(chǎn)生一組『手寫』數(shù)字字體。
- from helper import *
- import matplotlib.pyplot as plt
- import numpy as np
- import torch
- from dcgan.model import Generator
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- params = {'nz': nz, 'nc': nc, 'ngf': ngf}
- model = load_model(Generator, params, "./model/generator_state.pth", device=device)
- img = generate_fake_handwriting(model, batch_size=batch_size, nz=nz, device=device)
- plt.imshow(np.asarray(img))

結論與總結
近些年成長快速的 PyTorch 框架正在得到廣泛的認可和應用,越來越多的新模型采用 PyTorch 框架,也有模型被遷移到 PyTorch 上,或者基于 PyTorch 被完整再實現(xiàn)。生態(tài)環(huán)境持續(xù)豐富,應用領域不斷拓展,PyTorch 已成為事實上的主流框架之一。Amazon SageMaker 與多種 AWS 服務緊密集成,比如,各種類型和尺寸的 Amazon EC2 計算實例、Amazon S3、Amazon ECR 等等,為機器學習工程實踐提供了端到端的、一致的體驗。Amazon SageMaker 持續(xù)支持主流機器學習框架,PyTorch 是這其中之一。用 PyTorch 開發(fā)的機器學習算法和模型,可以輕松移植到 Amazon SageMaker 的工程和服務環(huán)境里,進而利用 Amazon SageMaker 全托管的 Jupyter Notebook、訓練容器鏡像、服務容器鏡像、訓練任務管理、部署環(huán)境托管等功能,簡化機器學習工程復雜度,提高生產(chǎn)效率,降低運維成本。
DCGAN 是生成對抗網(wǎng)絡領域中具里程碑意義的一個,是現(xiàn)今很多復雜生成對抗網(wǎng)絡的基石。文首提到的 StyleGAN,用文本合成圖像的 StackGAN,從草圖生成圖像的Pix2pix,以及互聯(lián)網(wǎng)上爭議不斷的 DeepFakes 等等,都有DCGAN的影子。相信通過本文的介紹和工程實踐,對您了解生成對抗網(wǎng)絡的原理和工程方法會有所幫助。