譯者 | 朱先忠
審校 | 重樓
“生成對抗性網絡”(GANs)在生成與過去的真實數據無法區分的真實合成數據方面表現出了卓越的性能。不幸的是,GANs因為其缺乏職業道德的的應用程序deepfakes而引起了公眾的注意。

本文實例將使用GANs作為數據增強工具,試圖解決與不平衡數據集相關的欺詐檢測這一經典問題。更具體地說,GANs可以生成少數欺詐類的真實合成數據,并將不平衡的數據集完美平衡地轉換。
簡介
原則上,欺詐檢測是二元分類算法的一種應用:對每筆交易進行分類,無論是否是欺詐類型的交易。其實,欺詐類型的交易往往只占交易領域的一小部分。一般來說,欺詐交易屬于少數類別;因此,數據集高度不平衡。欺詐交易越少,交易系統就越健全。這一點是非常簡單和直觀的。
一個矛盾的問題是這種健全的條件很可能是過去欺詐偵查極具挑戰性的主要原因之一。這僅僅是因為分類算法很難學習少數類別欺詐的概率分布。
一般來說,數據集越平衡,分類預測器的性能就越好。換句話說,數據集越不平衡(或越不平衡),分類器的性能就越差。
這描繪了欺詐檢測的經典問題:具有高度不平衡數據集的二分類應用程序。
在這種情況下,我們可以使用生成對抗性網絡(GANs)作為數據增強工具來生成少數欺詐類別的真實合成數據,以便更為平衡地轉換整個數據集,從而提高欺詐檢測分類器模型的性能。
本文將分為以下幾個部分展開探討:
- 第1節:算法概述(GANs的雙層優化體系結構)
- 第2節:欺詐數據集
- 第3節:用于數據增強的GANs的Python代碼解析
- 第4節:欺詐檢測概述(基準場景與GANs場景)
- 第5節:結論
總的來說,我將主要介紹GANs的相關主題(包括算法和代碼)。對于GANs之外的模型開發的其他方面的內容,如數據預處理和分類器算法,我將只概述其過程,而不討論其細節。在這種情況下,本文假設讀者對二進制分類器算法(特別是我為欺詐檢測選擇的集成分類器)有基本的了解,并對數據清理和預處理也有大致的了解。
有關詳細代碼,歡迎讀者訪問以下鏈接:
第1節:算法概述(GANs的雙層優化體系架構)
GANs是一種特殊類型的生成算法,由兩個神經網絡組成:生成網絡(生成器)和對抗性網絡(鑒別器)。其中,生成器試圖生成真實的合成數據,鑒別器將合成數據與真實數據區分開來。
最初的GANs是在一篇標題為《生成對抗性網絡》的開創性的論文(Goodfellow等人共同發表,Generative Adversarial Nets,2014年出版,原文地址:https://arxiv.org/abs/1406.2661)中引入的。最初的GANs的合著者用造假者-警察的類比來描述GANs:一款迭代游戲,生成器充當造假者,鑒別器扮演警察的角色來檢測生成器偽造的贗品。
最初的GANs在某種意義上是具有創新性的,它解決并克服了過去訓練深度生成算法的傳統困難。作為其核心,它被設計為具有均衡尋求目標設置(相對于最大似然導向目標設置)的雙層優化架構。
從那以后,人們對GANs的許多變體架構進行了探索。本文將僅參考原始GANs的原型架構。
生成器和鑒別器
再強調一下,在GANs的架構中,兩個神經網絡——生成器和鑒別器——相互競爭。在這種情況下,競爭是通過前向傳播和后向傳播的迭代進行的(根據神經網絡的一般框架原理)。
一方面,鑒別器是一個設計上的二元分類器:它對每個樣本是真實的(標簽:1)還是假的/合成的(標簽為0)進行分類。在前向傳播期間向鑒別器饋送真實樣本和合成樣本;在反向傳播過程中,它學習從混合數據饋送中檢測合成數據。
另一方面,生成器被設計為一個噪聲分布。在正向傳播期間向生成器提供真實樣本。然后,在反向傳播過程中,生成器學習真實數據的概率分布,以便更好地模擬其合成樣本。
然后,通過“雙層優化”框架對這兩個代理進行交替訓練。
雙層訓練機制(雙層優化方法)
在最初的GAN論文中,為了訓練這兩個追求完全相反目標的代理,合著者設計了一個“雙層優化(訓練)”架構,其中一個內部訓練塊(鑒別器的訓練)嵌套在另一個高級訓練塊(生成器的訓練)中。
下圖說明了嵌套訓練循環中的“雙層優化”結構。鑒別器在嵌套的內部循環中訓練,而生成器在更高級別的主循環中訓練。

GANs在這種雙層訓練架構中交替訓練這兩個代理(Goodfellow等人2014年合著論文《生成對抗性神經網絡(Generative Adversarial Nets)》的第3頁)。換言之,在交替過程中訓練一個代理時,我們需要凍結另一個代理的學習過程(Goodfellow I.于2015年發表論文第3頁的結論)。
Mini-Max優化目標
除了能夠交替訓練這兩個代理的“雙層優化”機制之外,GANs與傳統神經網絡原型的另一個獨特之處是其最小-最大優化目標。簡單地說,與傳統的最大搜索方法(如最大似然)相比,GANs追求均衡搜索優化目標。
那么,什么是追求平衡的優化目標呢?
讓我們把這個問題分解開來作解釋。
GANs的兩個代理有兩個截然相反的目標。雖然鑒別器作為一種二元分類器,旨在最大限度地提高對真實樣本和合成樣本的混合物進行正確分類的概率,但生成器的目標是最大限度地降低鑒別器正確分類合成數據的概率:因為生成器需要欺騙鑒別器。
在這種情況下,最初GANs的合著者將總體目標稱為“最小最大游戲”。(Goodfellow等人2014年合著論文的第3頁)
總體而言,GANs的最終最小-最大優化目標不是搜索這些目標函數中的任何一個的全局最大值/最小值。相反,它被設置為尋求一個平衡點,該平衡點可以被解釋為:
- “鞍點是分類器的局部最大值和生成器的局部最小值”(Goodfellow I.,2015,第2頁)。
- 其中的兩個代理都不能再提高它們的性能。
- 其中的生成器學會創建的合成數據已經變得足夠現實,足以欺騙鑒別器。
平衡點在概念上可以用隨機猜測的概率0.5(50%)來表示,對于鑒別器:D(z)=>0.5。
讓我們根據GANs的目標函數來轉錄GANs的極大極小優化的概念框架。
鑒別器的目標是使下圖中的目標函數最大化:

為了解決潛在的飽和問題,他們將生成器的原始對數似然目標函數的第二項轉換如下,并建議將轉換后的版本最大化為生成器的目標:
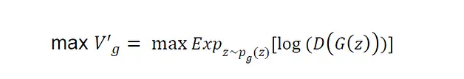
總體而言,GANs的“雙層優化”架構可以轉化為以下算法:

有關GANs算法設計的更多細節,請閱讀我的另一篇文章:《生成對抗性網絡的Mini-Max優化設計(Mini-Max Optimization Design of Generative Adversarial Nets):https://towardsdatascience.com/mini-max-optimization-design-of-generative-adversarial-networks-gan-dc1b9ea44a02》。
現在,讓我們開始使用數據集進行實際的編程分析。
為了強調GANs算法,我將在本文主要關注GANs的實現代碼,只概述一下其余的過程。
第2節:欺詐數據集
為了進行欺詐檢測,我從Kaggle網站選擇了以下信用卡交易數據集:https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
數據許可證:Database Contents License(DbCL)v1.0。
以下是該數據集的簡要說明。
該數據集包含284807筆交易。在數據集中,我們只有492起欺詐交易(包括29起重復案件)。
由于欺詐類僅占所有交易的0.172%,因此這一部分數據形成了一個占極少數的類別。該數據集適用于說明與不平衡數據集相關的欺詐檢測的經典問題。
該數據集具有以下30個特征:
- V1,V2,…V28:這28個主要成分通過PCA獲得。出于保護隱私的目的,未披露數據來源。
- “Time”:每個事務與數據集的第一個事務之間經過的秒數。
- “Amount”:交易的金額。
- “Class”:標簽設置為“Class”。欺詐情況下為1;否則,為0。
數據預處理:特征選擇
由于數據集已經被清理得很干凈,如果不是很完美的話,我只需要做幾件事來清理數據:消除重復數據和去除異常值。
此后,在數據集中給定30個特征的情況下,我決定運行特征選擇,通過在訓練過程之前消除不太重要的特征來減少特征的數量。我選擇了scikit-learn開源庫中的隨機森林分類器中內置的特征重要性分數來估計所有30個特征的分數。
下圖顯示了實驗結果的摘要信息。如果您對其詳細的流程感興趣的話,請參閱我上面列出地址處的代碼。
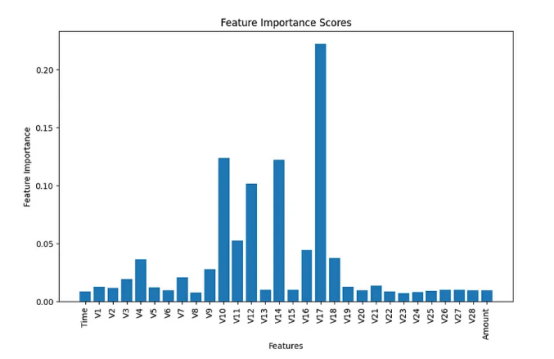
根據上面條形圖中顯示的結果,我做出了主觀判斷,選擇了前6個特征進行分析,并從模型構建過程中刪除了所有剩余的不重要特征。
以下是選定的前6個重要特征。
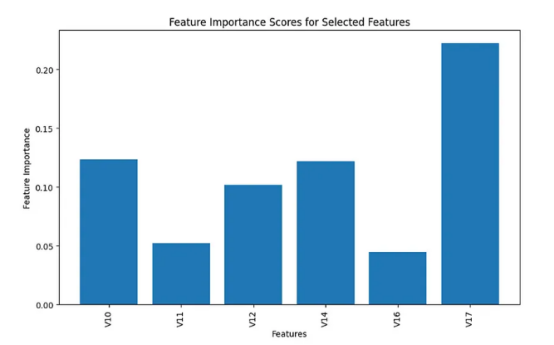
為了今后的模型構建目的,我重點介紹了這6個選定的特征。在數據預處理之后,我們得到了如下形狀的工作數據幀df:
- df.shape=(282513,7)現在,我們希望特征選擇能降低最終模型的復雜性并穩定其性能,同時保留優化二元分類器的關鍵信息。
第3節:用于數據增強的GANs的Python代碼解析
現在是我們使用GANs進行數據增強的時候了。
那么,我們需要創建多少合成數據呢?
首先,我們對數據增強的興趣僅限于模型訓練。由于測試數據集中沒有提供樣本數據;所以,我們希望保留測試數據集的原始形式。其次,因為我們的目的是完美地轉換不平衡的數據集;所以,我們不想增加占大多數的非欺詐性質的案例。
簡言之,我們只想增加少數欺詐類型的訓練數據集,而不想增加其他數據集。
現在,讓我們使用分層數據拆分方法,將工作數據幀按80/20的比例拆分為訓練數據集和測試數據集。
#分離特征和目標變量
X = df.drop('Class', axis=1)
y = df['Class']
#將數據拆分為訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
#組合訓練數據集的特征和標簽
train_df = pd.concat([X_train, y_train], axis=1)因此,訓練數據集的形狀如下:
- train_df.shape=(226010,7)
讓我們看看訓練數據集的組成(欺詐案例和非欺詐案例)。
# 加載數據集(欺詐和非欺詐數據)
fraud_data = train_df[train_df['Class'] == 1].drop('Class', axis=1).values
non_fraud_data = train_df[train_df['Class'] == 0].drop('Class', axis=1).values
# 計算要生成的合成欺詐樣本的數量
num_real_fraud = len(fraud_data)
num_synthetic_samples = len(non_fraud_data) - num_real_fraud
print("# of non-fraud: ", len(non_fraud_data))
print("# of Real Fraud:", num_real_fraud)
print("# of Synthetic Fraud required:", num_synthetic_samples)
# of non-fraud: 225632
# of Real Fraud: 378
# of Synthetic Fraud required: 225254上面的輸出告訴我們,訓練數據集(226010)由225632個非欺詐數據和378個欺詐數據組成。換句話說,它們之間的差值是225254。這個數字是我們需要增加的合成欺詐數據(num_synthetic_samples)的數量,以便與訓練數據集中這兩個類別的數量完全匹配。注意,我們確實保留了原始測試數據集。
接下來,讓我們對GANs進行編碼。
首先,讓我們創建幾個自定義函數來確定兩個代理:鑒別器和生成器。
對于生成器,我創建了一個噪聲分布函數build_generator(),它需要兩個參數:
latent_dim(噪聲的維度)作為其輸入的形狀,以及其輸出的形狀output_dim——對應于特征的數量。
#定義生成器網絡
def build_generator(latent_dim, output_dim):
model = Sequential()
model.add(Dense(64, input_shape=(latent_dim,)))
model.add(Dense(128, activation='sigmoid'))
model.add(Dense(output_dim, activation='sigmoid'))
return model對于鑒別器,我創建了一個自定義函數build_descriminator(),它接受一個input_dim參數,對應于特性的數量。
#定義鑒別器網絡
def build_discriminator(input_dim):
model = Sequential()
model.add(Input(input_dim))
model.add(Dense(128, activation='sigmoid'))
model.add(Dense(1, activation='sigmoid'))
return model然后,我們可以調用這些函數來創建生成器和鑒別器。在這里,對于生成器,我隨便將latent_dim設置為32:如果您愿意,當然也可以使用其它的值。
#生成器輸入噪聲的尺寸
latent_dim = 32
#構造生成器和鑒別器模型
generator = build_generator(latent_dim, fraud_data.shape[1])
discriminator = build_discriminator(fraud_data.shape[1])在這個階段,我們需要編譯鑒別器,它稍后將嵌套在主(更高)優化循環中。我們可以使用以下參數設置來編譯鑒別器。
- 鑒別器的損失函數:二值分類器的通用交叉熵損失函數。
- 評價指標:準確度和召回率。
# 編譯鑒別器模型
from keras.metrics import Precision, Recall
discriminator.compile(optimizer=Adam(learning_rate=0.0002, beta_1=0.5), loss='binary_crossentropy', metrics=[Precision(), Recall()])對于生成器,我們將在構建主(上)優化循環時對其進行編譯。
在這個階段,我們可以定義生成器的自定義目標函數,如下所示。請記住,推薦的目標是最大化以下公式:

注意,上面返回值前面的負號是必需的,因為默認情況下損失函數被設計為最小化。
然后,我們便可以構建雙層優化架構的主(上)循環build_GANs(generator, discriminator)。在這個主循環中,我們隱式編譯生成器。在這種情況下,當我們編譯主循環時,我們需要使用生成器的自定義目標函數generator_loss_log_d。
如上所述,當我們訓練生成器時,我們需要凍結鑒別器。
#結合生成器和鑒別器,構建并編譯GANs主優化循環
def build_gan(generator, discriminator):
discriminator.trainable = False
model = Sequential()
model.add(generator)
model.add(discriminator)
model.compile(optimizer=Adam(learning_rate=0.0002, beta_1=0.5), loss=generator_loss_log_d)
return model
# 調用主循環函數
gan = build_gan(generator, discriminator)在上面的最后一行,GANs調用build_gan()函數,以便使用Keras框架中的model.train_on_batch()方法實現下面的批處理訓練。
注意,當我們訓練鑒別器時,我們需要凍結生成器的訓練;當我們訓練生成器時,我們需要凍結鑒別器的訓練。
這是在雙層優化框架下結合兩個代理的交替訓練過程的批量訓練代碼。
# 設置超參數
epochs = 10000
batch_size = 32
#訓練GANs的循環
for epoch in range(epochs):
#訓練鑒別器(凍結發生器)
discriminator.trainable = True
generator.trainable = False
#從真實的欺詐數據中隨機抽樣
real_fraud_samples = fraud_data[np.random.randint(0, num_real_fraud, batch_size)]
# 使用生成器生成虛假欺詐樣本數據
noise = np.random.normal(0, 1, size=(batch_size, latent_dim))
fake_fraud_samples = generator.predict(noise)
#為真實和偽造的欺詐樣本數據創建標簽
real_labels = np.ones((batch_size, 1))
fake_labels = np.zeros((batch_size, 1))
#訓練針對真偽欺詐樣本的鑒別器
d_loss_real = discriminator.train_on_batch(real_fraud_samples, real_labels)
d_loss_fake = discriminator.train_on_batch(fake_fraud_samples, fake_labels)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
#訓練生成器(凍結鑒別器)
discriminator.trainable = False
generator.trainable = True
#生成合成欺詐樣本并創建標簽以訓練生成器
noise = np.random.normal(0, 1, size=(batch_size, latent_dim))
valid_labels = np.ones((batch_size, 1))
# 訓練生成器生成“欺騙”鑒別器的樣本
g_loss = gan.train_on_batch(noise, valid_labels)
#打印進度
if epoch % 100 == 0:
print(f"Epoch: {epoch} - D Loss: {d_loss} - G Loss: {g_loss}")這里,我即興想到一個問題,請你回答一下。
下面我們摘錄了上面代碼中與生成器訓練相關的內容。
你能解釋一下這個代碼是做什么的嗎?
# 生成合成欺詐樣本并創建標簽以訓練生成器
noise = np.random.normal(0, 1, size=(batch_size, latent_dim))
valid_labels = np.ones((batch_size, 1))在第一行中,noise生成合成數據。在第二行中,valid_labels指定合成數據的標簽。
為什么我們需要用1來標記它,這應該是真實數據的標簽?你沒有發現代碼違反直覺嗎?
女士們,先生們,歡迎來到造假者的世界!
這就是訓練生成器創建可以欺騙鑒別器的樣本的標記魔法!
現在,讓我們使用經過訓練的生成器為少數欺詐類型創建合成數據。
#訓練后,使用生成器創建合成欺詐數據
noise = np.random.normal(0, 1, size=(num_synthetic_samples, latent_dim))
synthetic_fraud_data = generator.predict(noise)
#將結果轉換為Pandas DataFrame格式
fake_df = pd.DataFrame(synthetic_fraud_data, columns=features.to_list())最后,創建合成數據。
在下一節中,我們可以將這些合成的欺詐數據與原始訓練數據集相結合,使整個訓練數據集完全平衡。我希望此完全平衡的訓練數據集能夠提高欺詐檢測分類模型的性能。
第4節:欺詐檢測概述(基準場景與GANs場景)
我們一再強調,本項目中使用的GANs僅用于數據增強,而不用于分類。
首先,我們需要一個基準模型作為比較的基礎,以便評估基于GANs的數據增強對欺詐檢測模型性能的改進。
作為一種二值分類器算法,我選擇了Ensemble方法來構建欺詐檢測模型。作為基準場景,我只使用原始的不平衡數據集開發了一個欺詐檢測模型:因此,沒有數據增強。然后,對于通過GANs進行數據增強的第二種場景,我可以使用完全平衡的訓練數據集訓練相同的算法,該數據集包含由GANs創建的合成欺詐數據。
- 基準場景:沒有數據增強的集成分類器
- GANs場景:使用GANs數據增強的集成分類器(Ensemble Classifier)
基準場景:沒有數據增強的集成
接下來,讓我們定義基準場景(沒有數據增強)。我決定使用集成分類器:用投票法作為元學習器,這將包括以下3個基本學習器:
- 梯度增強
- 決策樹
- 隨機森林
由于原始數據集特別不平衡——而不是準確性方面,所以我將從以下3個選項中選擇評估指標:準確性、召回率和F1分數。
以下自定義函數ensemble_training(X_train,y_train)定義了訓練和驗證過程。
def ensemble_training(X_train, y_train):
#初始化基礎學習器
gradient_boosting = GradientBoostingClassifier(random_state=42)
decision_tree = DecisionTreeClassifier(random_state=42)
random_forest = RandomForestClassifier(random_state=42)
#定義基型模型
base_models = {
'RandomForest': random_forest,
'DecisionTree': decision_tree,
'GradientBoosting': gradient_boosting
}
# 初始化元學習器
meta_learner = VotingClassifier(estimators=[(name, model) for name, model in base_models.items()], voting='soft')
# 用于存儲訓練和驗證指標的列表
train_f1_scores = []
val_f1_scores = []
# 將訓練集進一步拆分為訓練集和驗證集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=42, stratify=y_train)
# 訓練和驗證
for model_name, model in base_models.items():
model.fit(X_train, y_train)
#訓練指標
train_predictions = model.predict(X_train)
train_f1 = f1_score(y_train, train_predictions)
train_f1_scores.append(train_f1)
#使用校驗集合的校驗指標
val_predictions = model.predict(X_val)
val_f1 = f1_score(y_val, val_predictions)
val_f1_scores.append(val_f1)
# 在整個訓練集中訓練元學習器
meta_learner.fit(X_train, y_train)
return meta_learner, train_f1_scores, val_f1_scores, base_models下一個函數ensemble_evaluations(meta_learner, X_train, y_train, X_test, y_test)負責計算元學習器級別的性能評估指標。
def ensemble_evaluations(meta_learner,X_train, y_train, X_test, y_test):
#兩個訓練的GANs測試數據集上集成模型的指標
ensemble_train_predictions = meta_learner.predict(X_train)
ensemble_test_predictions = meta_learner.predict(X_test)
#計算集成模型的指標
ensemble_train_f1 = f1_score(y_train, ensemble_train_predictions)
ensemble_test_f1 = f1_score(y_test, ensemble_test_predictions)
# 計算訓練和測試數據集的精度和召回率
precision_train = precision_score(y_train, ensemble_train_predictions)
recall_train = recall_score(y_train, ensemble_train_predictions)
precision_test = precision_score(y_test, ensemble_test_predictions)
recall_test = recall_score(y_test, ensemble_test_predictions)
#輸出訓練和測試數據集的精度、召回率和f1分數
print("Ensemble Model Metrics:")
print(f"Training Precision: {precision_train:.4f}, Recall: {recall_train:.4f}, F1-score: {ensemble_train_f1:.4f}")
print(f"Test Precision: {precision_test:.4f}, Recall: {recall_test:.4f}, F1-score: {ensemble_test_f1:.4f}")
return ensemble_train_predictions, ensemble_test_predictions, ensemble_train_f1, ensemble_test_f1, precision_train, recall_train, precision_test, recall_test下面,讓我們來看一看基準集成分類器的性能數據。
Training Precision: 0.9811, Recall: 0.9603, F1-score: 0.9706
Test Precision: 0.9351, Recall: 0.7579, F1-score: 0.8372可見,在元學習器水平上,基準模型生成了0.8372的合理水平的F1分數。
接下來,讓我們轉到使用GANs進行數據增強的場景。我們想看看使用GAN的場景的性能是否能優于基準場景。
GANs場景:通過GANs增強數據進行欺詐檢測
最后,我們將原始的不平衡訓練數據集(包括非欺詐和欺詐案例)train_df和GAN生成的合成欺詐數據集fake_df相結合,構建了一個完全平衡的數據集。在這里,我們不將測試數據集包含在此過程中,以便將其保留為原始數據集。
wdf = pd.concat([train_df, fake_df], axis=0)我們將使用混合平衡數據集訓練相同的集成方法,看看它是否會優于基準模型。
現在,我們需要將混合平衡的數據集拆分為特征和標簽。
X_mixed = wdf[wdf.columns.drop("Class")]
y_mixed = wdf["Class"]請記住,當我早些時候運行基準場景時,我已經定義了必要的自定義函數來訓練和評估集成分類器。我也可以在此使用這些自定義函數并使用組合起來的平衡數據來訓練相同的Ensemble算法。
我們可以將特征和標簽(X_mixed,y_mixed)傳遞到自定義集成分類器函數Ensemble_training()中。
meta_learner_GANs, train_f1_scores_GANs, val_f1_scores_GANs, base_models_GANs=ensemble_training(X_mixed, y_mixed)最后,我們可以使用測試數據集對模型進行評估。
ensemble_evaluations(meta_learner_GANs, X_mixed, y_mixed, X_test, y_test)結果如下:
Ensemble Model Metrics:
Training Precision: 1.0000, Recall: 0.9999, F1-score: 0.9999
Test Precision: 0.9714, Recall: 0.7158, F1-score: 0.8242結論
現在,我們終于可以評估GANs的數據增強是否如我所期望的那樣提高了分類器的性能了。
讓我們來比較一下基準場景和GANs場景之間的評估指標。
以下是基準場景的結果:
# The Benchmark Scenrio without data augmentation by GANs
Training Precision: 0.9811, Recall: 0.9603, F1-score: 0.9706
Test Precision: 0.9351, Recall: 0.7579, F1-score: 0.8372以下是GANs場景的結果:
Training Precision: 1.0000, Recall: 0.9999, F1-score: 0.9999
Test Precision: 0.9714, Recall: 0.7158, F1-score: 0.8242當我們回顧訓練數據集上的評估結果時,很明顯,在所有三個評估指標中,GANs場景的表現都優于基準場景。
然而,當我們關注樣本外測試數據的結果時,GANs情景僅在精度方面優于基準情景(基準場景:0.935相對于GANs場景:0.9714):在召回和F1得分方面未能做到這一點(基準場景:0.7579;0.8372相對于GANs場景:0.7158;0.8242)。
更高的精度意味著,與基準場景相比,該模型對欺詐交易的預測中包含的非欺詐交易比例更低。
召回率較低意味著,該模型未能檢測到某些類型的實際欺詐交易。
這兩個比較表明:雖然GANs的數據增強成功地模擬了訓練數據集中的真實欺詐數據,但未能捕捉到樣本外測試數據集中實際欺詐案例的多樣性。
GANs在模擬訓練數據的特定概率分布方面做得太好了。具有諷刺意味的是,使用GANs作為數據增強工具,考慮到對訓練數據的過擬合,導致了所產生的欺詐檢測(分類)模型的泛化能力較差。
很矛盾的是,上面提供的這個特定的例子提出了一個反直覺的情況,即與更簡單的傳統算法相比,更復雜的算法可能不一定能保證更好的性能。
此外,我們還可以考慮到另一個意想不到的后果,即碳能耗問題:在模型開發中添加耗能高的算法可能會增加我們日常生活中使用機器學習的碳能耗。這種情況展示了一個不必要的浪費能耗的例子,此時不必要地浪費了能量而沒有提供更好的性能。
在這里,我想給您留下一些關于機器學習能耗知識的鏈接,供參考:
- https://spectrum.ieee.org/ai-energy-consumption
- https://www.cell.com/joule/fulltext/S2542-4351(23)00365-3?_returnURL=https%3A%2F%2Flinkinghub.elsevier.com%2Fretrieve%2Fpii%2FS2542435123003653%3Fshowall%3Dtrue
今天,我們已經擁有許多的GANs變體。在未來的文章中,我想探索GANs的其他變體,看看是否有任何變體可以捕獲更廣泛的原始樣本多樣性,從而提高欺詐檢測器的性能。
參考資料
- Borji, A. (2018, 10 24)。Pros and Cons of GAN Evaluation Measures,鏈接地址: https://arxiv.org/abs/1802.03446。
- Goodfellow, I. (2015, 5 21). On distinguishability criteria for estimating generative models,鏈接地址:https://arxiv.org/abs/1412.6515。
- Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozairy, S., . . . Bengioz, Y. (2014, 6 10). Generative Adversarial Nets,鏈接地址:https://arxiv.org/abs/1406.2661。
- Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozairy, S., . . . Bengioz, Y. (2014, 6 10). Generative Adversarial Networks,鏈接地址:https://arxiv.org/abs/1406.2661。
- Knight, W. (2018, 8 17). Fake America great again. Retrieved from MIT Technology,鏈接地址:https://www.technologyreview.com/2018/08/17/240305/fake-america-great-again/。
- Suginoo, M. (2024, 1 13). Mini-Max Optimization Design of Generative Adversarial Networks (GAN) ,鏈接地址:
https://towardsdatascience.com/mini-max-optimization-design-of-generative-adversarial-networks-gan-dc1b9ea44a02。
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Fraud Detection with Generative Adversarial Nets (GANs),作者:Michio Suginoo