使用Kafka和Druid了解Spark流
作為一名數據工程師,我正在研究大數據技術,例如Spark Streaming,Kafka和Apache Druid。 他們都有自己的教程和RTFM頁面。 但是,將這些技術大規模地組合在一起時,您會發現自己正在尋找涵蓋更復雜的生產用例的解決方案。 在本博文中,我將分享通過將Spark Streaming,Kafka和Apache Druid結合在一起以構建實時分析儀表板,以確保精確的數據表示而獲得的知識。
在開始之前……關于實時分析的幾句話
實時分析是大數據技術的新趨勢,通常具有顯著的業務影響。 在分析新鮮數據時,見解更加精確。 例如,為數據分析師,BI和客戶經理團隊提供實時分析儀表板可以幫助這些團隊做出快速決策。 大規模實時分析的常用架構基于Spark Streaming和Kafka。 這兩種技術都具有很好的可擴展性。 它們在群集上運行,并在許多計算機之間分配負載。 Spark作業的輸出可以到達許多不同的目的地,這取決于特定的用例和體系結構。 我們的目標是提供顯示實時事件的可視工具。 為此,我們選擇了Apache Druid數據庫。
Apache Druid中的數據可視化
Druid是高性能的實時分析數據庫。 它的好處之一是能夠使用來自Kafka主題的實時數據,并使用Pivot模塊在其上構建強大的可視化效果。 它的可視化功能可以運行各種臨時的"切片和切塊"查詢,并快速獲得可視化結果。 這對于分析各種用例非常有用,例如特定運動在某些國家的表現。 實時檢索數據,延遲1-2分鐘。
架構
因此,我們決定基于Kafka事件和Apache Druid構建實時分析系統。 我們已經在Kafka主題中進行過活動。 但是我們不能將它們直接攝取到德魯伊中。 我們需要為每個事件添加更多維度。 我們需要用更多的數據豐富每個事件,以便在德魯伊中方便地查看它。 關于規模,我們每分鐘要處理數十萬個事件,因此我們需要使用能夠支持這些數字的技術。 我們決定使用Spark Streaming作業豐富原始的Kafka事件。
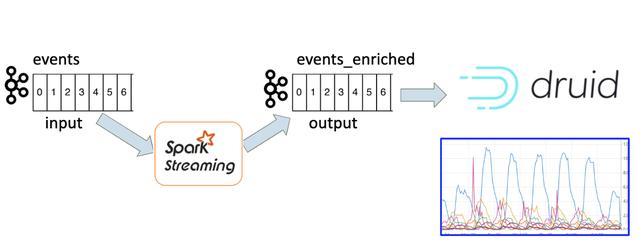
圖1.實時分析架構
Spark Streaming作業永遠運行? 并不是的。
Spark Streaming作業的想法是它始終在運行。 這項工作永遠都不應停止。 它不斷讀取來自Kafka主題的事件,對其進行處理,并將輸出寫入另一個Kafka主題。 但是,這是一個樂觀的看法。 在現實生活中,事情更加復雜。 Spark群集中存在驅動程序故障,在這種情況下,作業將重新啟動。 有時新版本的spark應用程序已部署到生產中。 在這種情況下會發生什么? 重新啟動的作業如何讀取Kafka主題并處理事件? 在深入研究這些細節之前,此圖顯示了重新啟動Spark Streaming作業時在Druid中看到的內容:
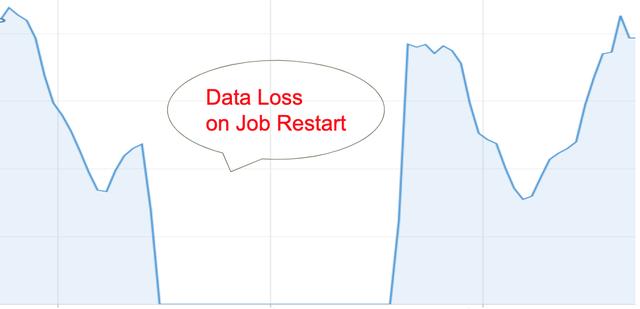
圖2.作業重新啟動時數據丟失
絕對是數據丟失!
我們要解決什么問題?
我們正在處理Spark Streaming應用程序,該應用程序從一個Kafka主題讀取事件,并將事件寫入另一個Kafka主題。 這些事件稍后將在Druid中顯示。 我們的目標是在重新啟動Spark Streaming應用程序期間實現平滑的數據可視化。 換句話說,我們需要確保在Spark Streaming作業重啟期間不會丟失或重復任何事件。
都是關于補償
為了理解為什么作業重新啟動時會丟失數據,我們需要熟悉Kafka體系結構中的一些術語。 您可以在這里找到Kafka的官方文檔。 簡而言之:Kafka中的事件存儲在主題中; 每個主題都分為多個分區。 分區中的每個記錄都有一個偏移量-一個連續的數字,它定義了記錄的順序。 當應用程序使用該主題時,它可以通過多種方式處理偏移量。 默認行為始終是從最新的偏移量讀取。 另一個選擇是提交偏移量,即持久保留偏移量,以便作業可以在重新啟動時讀取已提交的偏移量并從此處繼續。 讓我們看一下解決方案的步驟,并在每個步驟中加深對Kafka膠印管理的了解。
步驟#1-自動提交偏移量
默認行為始終是從最新的偏移量讀取。 這將不起作用,因為重新啟動作業時,該主題中有新事件。 如果作業從最新讀取,它將丟失重新啟動期間添加的所有消息,如圖2所示。Spark Streaming中有一個" enable.auto.commit"參數。 默認情況下,其值為false。 圖3顯示了將其值更改為true,運行Spark應用程序并重新啟動后的行為。
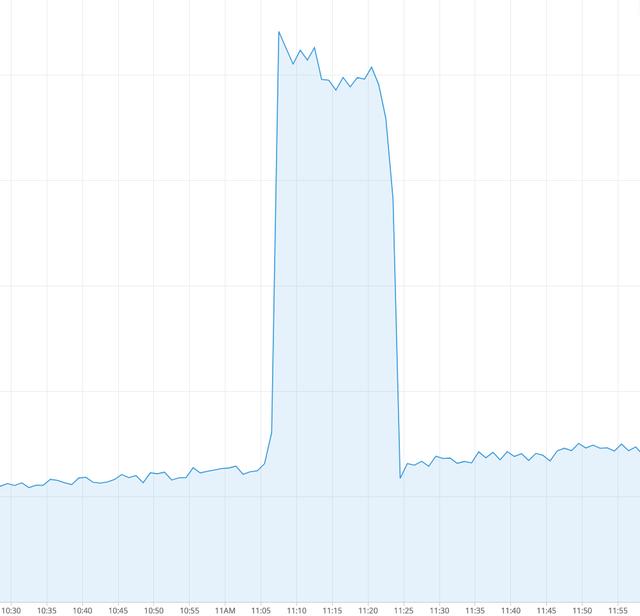
圖3.作業重啟的數據峰值
我們可以看到,使用Kafka自動提交功能會產生新的效果。 沒有"數據丟失",但是現在我們看到重復的事件。 沒有真正的事件"爆發"。 實際發生的情況是自動提交機制"不時"提交偏移量。 輸出主題中有許多未提交的消息。 重新啟動后,作業將使用最新提交的偏移量中的消息,并再次處理其中一些事件。 這就是為什么在輸出中會出現大量事件的原因。
顯然,將這些重復項合并到我們的可視化中可能會誤導業務消費者此數據,并影響他們的決策和對系統的信任。
步驟#2:手動提交Kafka偏移
因此,我們不能依靠Kafka自動提交功能。 我們需要自己進行卡夫卡補償。 為了做到這一點,讓我們看看Spark Streaming如何使用Kafka主題中的數據。 Spark Streaming使用稱為離散流或DStream的體系結構。 DStream由一系列連續的RDD(彈性分布式數據集)表示,這是Spark的主要抽象之一。 大多數Spark Streaming作業如下所示:
- dstream.foreachRDD { rdd => rdd.foreach { record => process(record)} }
在我們的案例中,處理記錄意味著將記錄寫入輸出Kafka主題。 因此,為了提交Kafka偏移量,我們需要執行以下操作:
- dstream.foreachRDD { rdd => val offsetRanges =
- rdd.asInstanceOf[HasOffsetRanges].offsetRanges rdd.foreach { record
- => process(record)}
- stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges) }
這是一種簡單明了的方法,在我們深入討論之前,讓我們看一下大局。 假設我們正確處理了偏移量。 即,在每次RDD處理之后都保存偏移量。 當我們停止工作時會怎樣? 該作業在RDD的處理過程中停止。 微批處理的部分將寫入輸出Kafka主題,并且不會提交。 一旦作業再次運行,它將第二次處理某些消息,并且重復消息的峰值將(與以前一樣)出現在Druid中:
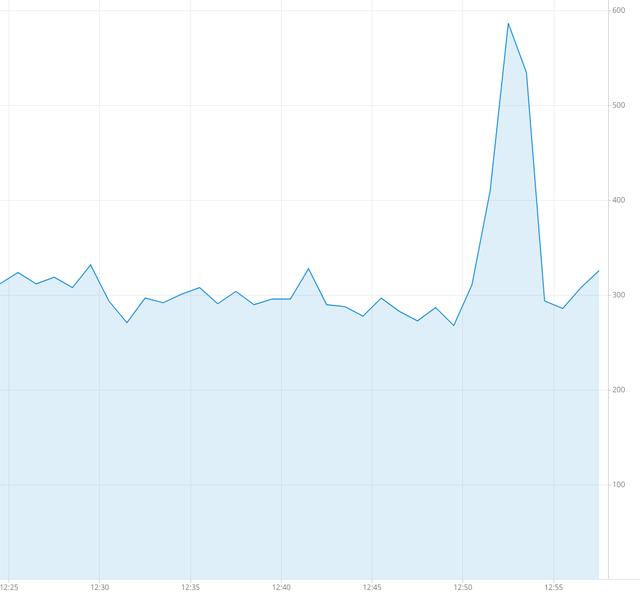
圖4.作業重新啟動時的數據峰值
正常關機
事實證明,有一種方法可以確保在RDD處理期間不會殺死作業。這稱為"正常關機"。有幾篇博客文章描述了如何優雅地殺死Spark應用程序,但是其中大多數與舊版本的Spark有關,并且有很多限制。我們一直在尋找一種適用于任何規模且不依賴于特定Spark版本或操作系統的"安全"解決方案。要啟用正常關機,應使用以下參數創建Spark上下文:spark.streaming.stopGracefullyOnShutdown = true。這指示Spark在JVM關閉時(而不是立即)正常關閉StreamingContext。另外,我們需要一種機制來有意地停止工作,例如在部署新版本時。我們已經通過簡單地檢查是否存在指示作業關閉的HDFS文件來實現該機制的第一個版本。當文件顯示在HDFS中時,流上下文將使用以下參數停止:ssc.stop(stopSparkContext = true,stopGracefully = true)
在這種情況下,只有在完成所有接收到的數據處理之后,Spark應用程序才會正常停止。 這正是我們所需要的。
步驟#3:Kafka commitAsync
讓我們回顧一下到目前為止的情況。 我們有意在每個RDD處理中提交Kafka偏移量(使用Kafka commitAsync API),并使用Spark正常關機。 顯然,還有另一個警告。 深入研究Kafka API和Kafka commitAsync()源代碼的文檔,我了解到commitAsync()僅將offsetRanges放入隊列中,實際上僅在下一個foreachRDD循環中進行處理。 即使Spark作業正常停止并完成了所有RDD的處理,實際上也不會提交最后一個RDD的偏移量。 為解決此問題,我們實現了一個代碼,該代碼可同步保留Kafka偏移量,并且不依賴于Kafka commitAsync()。 然后,對于每個RDD,我們將提交的偏移量存儲在HDFS文件中。 當作業再次開始運行時,它將從HDFS加載偏移文件,并從這些偏移開始使用Kafka主題。
在這里,它有效!
僅僅是正常關機和Kafka偏移量同步存儲的組合,才為我們提供了理想的結果。 重新啟動期間沒有數據丟失,沒有數據高峰:
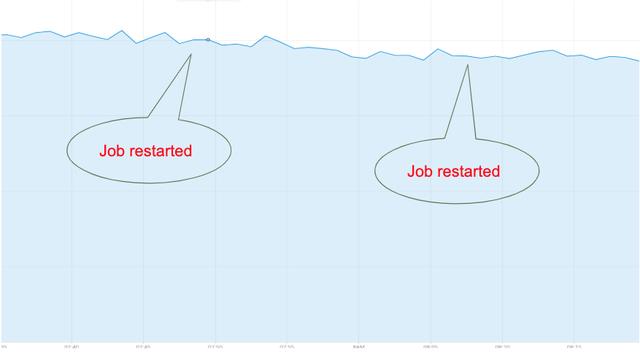
圖5.重新啟動Spark作業期間沒有峰值數據丟失
結論
解決Spark Streaming和Kafka之間的集成問題是構建實時分析儀表板的重要里程碑。 我們找到了可以確保穩定的數據流的解決方案,而不會在Spark Streaming作業重啟期間丟失事件或重復。 現在,我們獲得了在Druid中可視化的可信賴數據。 因此,我們將更多類型的事件(Kafka主題)添加到了Druid中,并建立了實時儀表板。 這些儀表板為各種團隊提供了見解,例如BI,產品和客戶支持。 我們的下一個目標是利用Druid的更多功能,例如新的分析功能和警報。