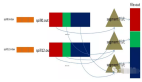
比較Hadoop、Spark和Kafka大數據框架
大約十年前,大數據開始流行。隨著存儲成本不斷下降,很多企業開始存儲他們獲取或生成的大部分數據,以便他們可以挖掘這些數據,以獲得關鍵的業務洞察力。
企業分析所有這些數據的需求推動著各種大數據框架的開發,這些框架能夠篩選大量數據,從Hadoop開始。大數據框架最初用于數據倉庫或數據湖中的靜態數據,但最近的趨勢是實時處理來自多個源的數據。
什么是大數據框架?
大數據框架是一組軟件組件,可用于構建分布式系統以處理大型數據集,包括結構化、半結構化或非結構化數據。這些數據集可以來自多個來源,大小從TB到PB到EB不等。
此類框架通常在高性能計算 (HPC) 中發揮作用,該技術可以解決材料科學、工程或金融建模等不同領域的難題。尋找這些問題的答案通常在于篩選盡可能多的相關數據。
最著名的大數據框架是Apache Hadoop。其他大數據框架包括Spark、Kafka、Storm和Flink,它們與Hadoop一樣都是由Apache軟件基金會開發的開源項目。Apache Hive最初由Facebook開發,也是一個大數據框架。
Spark相對于Hadoop的優勢是什么?
Apache Hadoop的主要組件是Hadoop分布式文件系統 (HDFS) 和數據處理引擎–部署 MapReduce程序以過濾和排序數據。還包括YARN,它是Hadoop集群的資源管理器。
Apache Spark也可以在HDFS或替代的分布式文件系統上運行。它的開發速度比MapReduce更快,通過在內存中處理和保留數據以供后續步驟使用,而不是將結果直接寫回存儲。對于較小的工作負載,這會使Spark比Hadoop快100倍。
但是,Hadoop MapReduce可以處理比Spark大得多的數據集,尤其是那些整個數據集的大小超過可用內存的數據集。如果企業擁有大量數據并且處理對時間不敏感,那么Hadoop可能是更好的選擇。
Spark更適合企業需要快速答案的應用程序,例如涉及迭代或圖形處理的應用程序。這種技術也稱為網絡分析,該技術分析客戶和產品等實體之間的關系。
Hadoop和Kafka的區別是什么?
Apache Kafka是分布式事件流平臺,旨在處理實時數據源。這意味著數據在通過系統時被處理。
與Hadoop一樣,Kafka在服務器節點集群上運行,因此具有可擴展性。有些服務器節點形成存儲層,稱為代理,而另一些則處理數據流的連續導入和導出。
嚴格來說,Kafka不是Hadoop的競爭對手平臺。企業可以將它與Hadoop一起用作整體應用程序架構的一部分,在該架構中,它處理傳入的數據流并將其輸入到數據湖中,以供Hadoop等框架進行處理。
由于其每秒可處理數千條消息,Kafka對于網站活動跟蹤或大規模物聯網部署中的遙測數據收集等應用非常有用。
Kafka和Spark的區別是什么?
Apache Spark是一種通用處理引擎,開發用于執行批處理(類似于MapReduce)和工作負載,例如流、交互式查詢和機器學習 (ML)。
Kafka的架構是分布式消息傳遞系統架構,將記錄流存儲在稱為主題的類別中。它不是用于大規模分析作業,而是用于高效的流處理。它旨在集成到應用程序的業務邏輯中,而不是用于批量分析作業。
Kafka最初是在社交網絡LinkedIn上開發,用于分析其數百萬用戶之間的聯系。也許最好將其視為能夠從眾多來源實時捕獲數據,并將其分類為要分析的主題以深入了解數據的框架。
這種分析可能會使用Spark等工具執行,Spark是一種集群計算框架,可以執行用Java、Python或Scala等語言開發的代碼。Spark還包含Spark SQL,它支持查詢結構化和半結構化數據;以及Spark MLlib,用于構建和操作ML管道的機器學習庫。
其他大數據框架
以下是其他你可能感興趣的大數據框架。
Apache Hive使SQL開發人員使用Hive查詢語言 (HQL) 語句,類似于用于數據查詢和分析的標準SQL。Hive可以在HDFS上運行,最適合數據倉庫任務,例如提取、轉換和加載 (ETL)、報告和數據分析。
Apache Flink將有狀態的流處理與處理ETL和批處理作業的能力相結合。這使其非常適合事件驅動的工作負載,例如網站上的用戶交互或在線采購訂單。與Hive一樣,Flink可以運行在HDFS或其他數據存儲層上。
Apache Storm是分布式實時處理框架,可以與帶有MapReduce的Hadoop進行比較,不同之處在于它實時處理事件數據,而MapReduce以離散批次運行。Storm是為可擴展性和高級別容錯而設計。它對于需要快速響應的應用程序也很有用,例如檢測安全漏洞。