PyTorch重大更新再戰TensorFlow,AWS也來趟深度學習框架的渾水?
剛剛,Facebook聯合AWS 宣布了PyTorch的兩個重大更新:TorchServe和TorchElastic。而不久前Google剛公布DynamicEmbedding。兩大陣營又開戰端,Facebook亞馬遜各取所長聯手對抗Google!
Facebook和亞馬遜推出全新PyTorch庫,針對大型高性能AI模型
剛剛,Facebook聯合AWS 宣布了PyTorch的兩個重大更新。
第一個是TorchServe,它是 PyTorch 的一個生產模型服務框架,可以使開發人員更容易地將他們的模型投入生產。
第二個是 TorchElastic,可以讓開發人員更容易地在 Kubernetes 集群上構建高容錯訓練作業,包括 AWS 的 EC2 spot 實例和 Elastic Kubernetes Service。
但是在發布過程中,Facebook官方博客產生了一個小插曲,將文章的發布日期2020年錯標稱了2019年。

TorchServe劍指何方
最近幾年,Facebook 和 AWS都積攢了大量的機器學習工程實踐經驗,而PyTorch在學術界和開源社區大受追捧。
TensorFlow的一個重要優勢在于TensorFlow Serving 和 Multi Model Server這些可快速部署到生產環境的模型服務器。
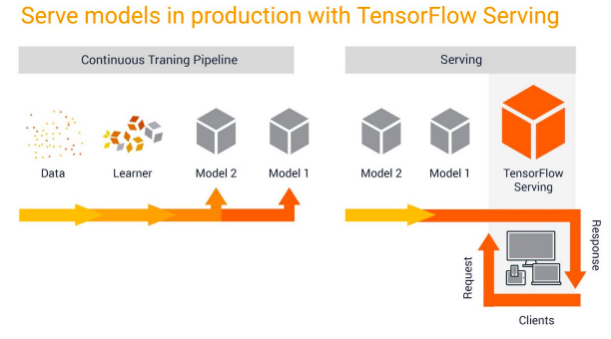
AWS 在 SageMaker 運行自己的模型服務器方面經驗豐富,SageMaker模型服務器雖然可以處理多個框架。而PyTorch則擁有十分活躍的社區,更新也頻繁。
開發者需要一個自己的模型服務器,要能根據自己的需求方便地進行定制化開發,而AWS也需要推廣自己的服務器,于是雙方一拍即合,在新版本的PyTorch中開源了TorchServe。
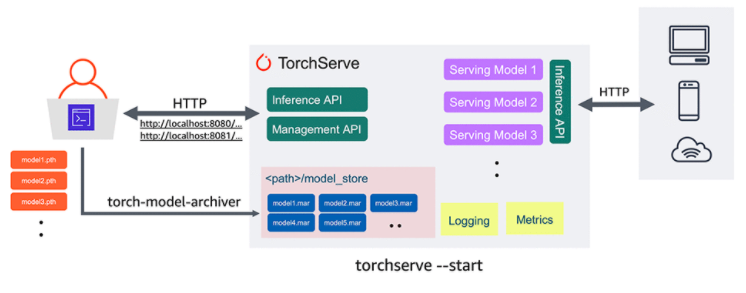
集成Kubernetes,TorchElastic讓訓練和部署更容易
TorchElastic可以和Kubernetes無縫集成,PyTorch 開發人員可以在多個計算節點上訓練機器學習模型,這些計算節點可以動態伸縮,讓模型訓練更加高效。
TorchElastic 的內置容錯能力支持斷點續傳,允許模型訓練出錯后繼續使用前面的結果。這個組件編寫好了分布式 PyTorch作業的接口,開發人員只需要簡單的編寫接口部分,就能讓模型跑在眾多分布式節點上,而不需要自己去管理 TorchElastic 節點和服務。
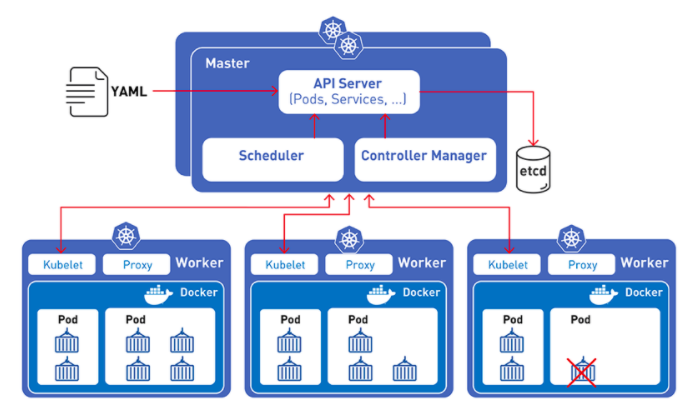
為什么結合Kubernetes如此重要
傳統的程序部署的方法是通過操作系統在主機上安裝程序。這樣做的缺點是,容易造成程序、依賴庫、環境配置的混淆。而容器部署基于操作系統級別的虛擬化,而非硬件虛擬化。
容器又小又快,每一個容器鏡像都可以打包裝載一個程序。Kubernetes 就是來管理容器的,所以PyTorch結合Kubernetes將大大提高模型的訓練速度,降低部署難度,而且更好管理模型的整個生命周期。
Google推出DynamicEmbedding,將TensorFlow推向“巨量級”應用
Google比Facebook早幾天公布了一個叫做DynamicEmbedding的產品,能夠將TensorFlow擴展到具有任意數量特征(如搜索查詢)的 "巨量級 "應用,還專門為此發布了一篇論文,在Google為其評估的數十個不同國家的72個重估指標中,DynamicEmbedding驅動的模型贏得了49個指標。
論文地址:
https://arxiv.org/pdf/2004.08366.pdf
論文中Google稱,DynamicEmbedding能夠通過模型訓練技術進行自我進化,能夠很好的處理可能會丟棄太多有價值信息的場景。
DynamicEmbedding擁有"不間斷地"增長特性,在不到六個月的時間里,從幾千兆字節自動增長到幾百兆字節,而不需要工程師不斷地進行回調。
同時DynamicEmbedding的內存消耗也極少。例如訓練Seq2Seq的模型時,在100個TensorFlow worker和297781個詞匯量的情況下,它只需要123GB到152GB的RAM,相比之下TensorFlow要達到同樣精度至少需要242GB的RAM。
事實上,DynamicEmbedding模型早已經應用在Google的智能廣告業務中,為 "海量 "搜索查詢所告知的圖片進行注釋(使用Inception),并將句子翻譯成跨語言的廣告描述(使用神經機器翻譯)。
其上開發的AI模型在兩年的時間里取得了顯著的準確率提升,截至2020年2月,Google Smart Campaign模型中的參數已經超過1240億,在20種語言的點擊率等指標上,其表現優于非DynamicEmbedding模型
Build過程也很簡單,只需要在TensorFlow的Python API中添加一組新的操作,這些操作將符號字符串作為輸入,并在運行模型時 "攔截 "上游和下游信號。
再通過一個叫做EmbeddingStore的組件,讓DynamicEmbedding和Spanner和Bigtable等外部存儲系統集成。數據可以存儲在本地緩存和遠程可變數據庫中。
DynamicEmbedding可以從worker故障中快速恢復,不需要等之前所有的數據加載完畢后才能接受新請求。
兩大陣營又開戰端,Facebook亞馬遜各取所長聯手對抗Google
TensorFlow依托于Google這顆大樹,占了早期紅利,在基數上暫時領先。
但隨著越來越多競爭者的加入,TF的老大地位受到了極其嚴重的威脅,PyTorch大有取而代之的勢頭。
此前,PyTorch相對TensorFlow最大優勢只是一個動態圖機制,導致PyTorch能夠比TensorFlow調試起來更容易,開發者不需要在編譯執行時先生成神經網絡的結構,然后再執行相應操作,可以更加方便地將想法轉化為代碼。
而且,相比TensorFlow,PyTorch的代碼風格是更加純正的Pythonic風味。PyTorch的動態圖機制,加上更純正Pythonic的代碼風格,使得PyTorch迅速流行起來。
等到谷歌發掘勢頭不對,在2017年著急的上了一個支持動態圖的TensorFlow Fold,后來發布升級版本Eager Excuation。但TensorFlow長久以來深入骨髓的靜態計算,怎么可能短期內就能徹底改變呢?
TensorFlow 2.0不僅對開發者來說學習成本高,甚至不得不為Google自己員工撰寫操作指南。

用戶都是用腳投票的,不論你是Google還是Facebook,做不做惡,產品好用才是第一位的。而招聘網站上的需求,能夠最直觀的體現企業的態度。
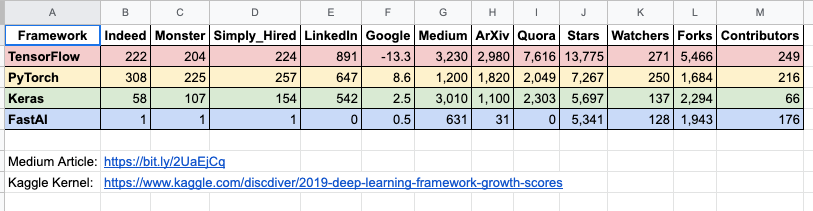
數據來源:
https://towardsdatascience.com/which-deep-learning-framework-is-growing-fastest-3f77f14aa318
根據the gradient統計的數據,PyTorch在學術界越來越受到青睞,將TensorFlow遠遠甩在身后。
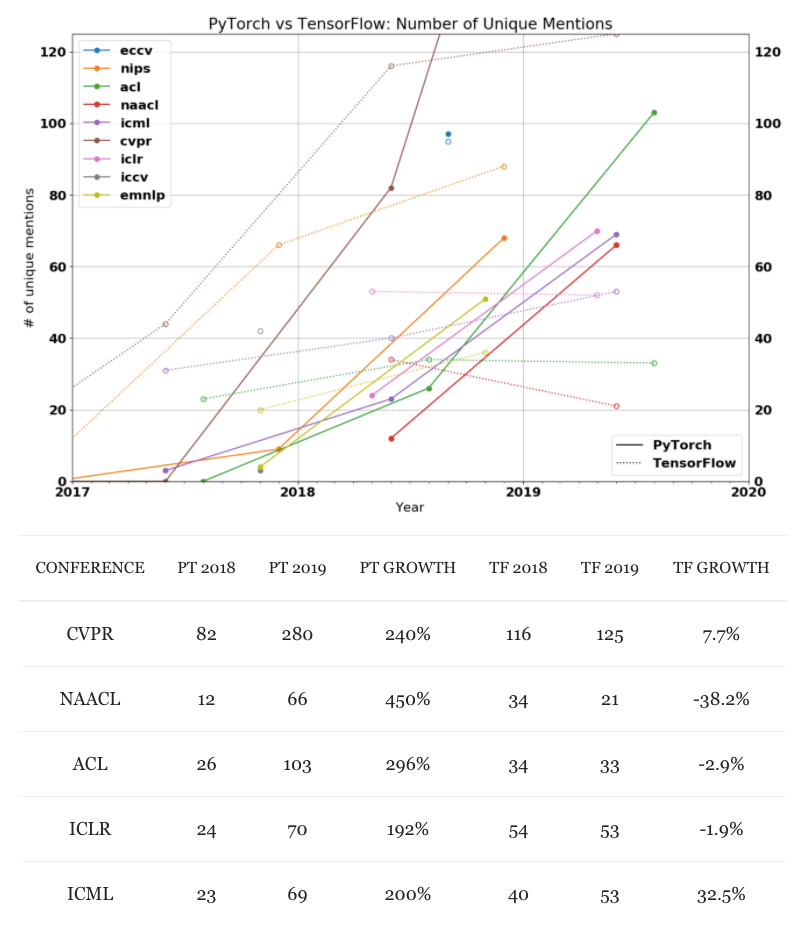
從幾大AI頂會關鍵詞數量來看,PyTorch在過去的兩年中都是呈現爆炸式增長,而TF則是不斷在走下坡路。
數據來源:
https://thegradient.pub/state-of-ml-frameworks-2019-pytorch-dominates-research-tensorflow-dominates-industry/
從業務線來看,Google不僅有框架,也有自己的云服務。而Facebook和亞馬遜,一個框架夠尖利,但是云端欠缺;另一個剛好相反,AWS穩居云計算第一的位置,但框架相比二者弱一些。
Google的意圖很明顯是要進一步擴大自己在訓練和部署方面的優勢,而Facebook的PyTorch,此前一直在生產環境部署等環節落后TensorFlow,此次更新的TorchServe和TorchElastic將彌補之前的差距。
和AWS合作也將獲得亞馬遜大量云端客戶的青睞,畢竟自己開發的框架在自己平臺用著更順手,當然亞馬遜也會在PyTorch社區獲得更多支持。
說到這里我們不得不提到另外兩個知名框架:Caffe和MXNet。雖然兩者的市場規模不大,但也曾是全村的希望。
如今,Caffe已經被PyTorch取代,而一旦F/A合體,MXNet的命運又將如何呢?歡迎大膽留言猜測!