













兩個框架的故事:pytorch與tensorflow
使用Pytorch 1.x和Tensorflow 2.x比較自動差異和動態模型子類方法

> Source: Author
數據科學界是一種充滿活力和合作的空間。我們從彼此的出版物中學到,辯論關于論壇和在線網點的想法,并分享許多代碼(和許多)代碼。這種合作精神的自然副作用是遇到同事使用的不熟悉工具的高可能性。因為我們不在真空中工作,所以在給定的主題領域中獲得熟悉多種語言和圖書館的熟悉程度往往是有意義的,以便合作和學習最有效。
這并不奇怪,那么,許多數據科學家和機器學習工程師在其工具箱中有兩個流行的機器學習框架:Tensorflow和Pytorch。這些框架 - 在Python中 - 分享許多相似之處,也以有意義的方式分歧。這些差異,例如它們如何處理API,加載數據和支持專業域,可以在兩個框架繁瑣且效率低下之間交替。這是一個問題,給出了這兩個工具的常見。
因此,本文旨在通過專注于創建和訓練兩個簡單模型的基礎知識來說明Pytorch和Tensorflow之間的差異。特別是,我們將介紹如何使用來自Pytorch 1.x的模塊API和來自Tensorflow 2.x的模塊API使用動態子類模型。我們將查看這些框架的自動差異如何,以提供非常樸素的梯度下降的實現。
但首先,數據
因為我們專注于自動差分/自動求導功能的核心(作為一種進修,是可以自動提取函數的導數的容量并在一些參數上應用梯度,以便使用這些參數梯度下降)我們可以從最簡單的模型開始,是線性回歸。我們可以使用Numpy庫使用一點隨機噪聲生成一些線性數據,然后在該虛擬數據集上運行我們的模型。
- def generate_data(m=0.1, b=0.3, n=200):
- x = np.random.uniform(-10, 10, n)
- noise = np.random.normal(0, 0.15, n)
- y = (m * x + b ) + noise
- return x.astype(np.float32), y.astype(np.float32)
- x, y = generate_data()
- plt.figure(figsize = (12,5))
- ax = plt.subplot(111)
- ax.scatter(x,y, c = "b", label="samples")
模型
一旦我們擁有數據,我們就可以從Tensorflow和Pytorch中的原始代碼實現回歸模型。為簡單起見,我們不會最初使用任何層或激活器,僅定義兩個張量,W和B,表示線性模型Y = Wx + B的權重和偏置。
正如您所看到的,除了API名稱的幾個差異之外,兩個模型的類定義幾乎相同。最重要的區別在于,Pytorch需要一個明確的參數對象來定義由圖捕獲的權重和偏置張量,而TensoRFlow能夠自動捕獲相同的參數。實際上,Pytorch參數是與模塊API一起使用時具有特殊屬性的Tensor子類:它們會自動向模塊參數列表添加SELF,因此SECRES在參數()迭代器中出現。
這兩個框架都提取了從此類定義和執行方法生成圖所需的一切(__call__或轉發),并且如下,如下所示,計算實現bospropagation所需的漸變。
Tensorflow動態模型
- class LinearRegressionKeras(tf.keras.Model):
- def __init__(self):
- super().__init__()
- self.w = tf.Variable(tf.random.uniform(shape=[1], -0.1, 0.1))
- self.b = tf.Variable(tf.random.uniform(shape=[1], -0.1, 0.1))
- def __call__(self,x):
- return x * self.w + self.b
Pytorch動態模型
- class LinearRegressionPyTorch(torch.nn.Module):
- def __init__(self):
- super().__init__()
- self.w = torch.nn.Parameter(torch.Tensor(1, 1).uniform_(-0.1, 0.1))
- self.b = torch.nn.Parameter(torch.Tensor(1).uniform_(-0.1, 0.1))
- def forward(self, x):
- return x @ self.w + self.b
構建訓練循環,backpropagation和優化器
使用這些簡單的Tensorflow和Bytorch模型建立,下一步是實現損失函數,在這種情況下只是意味著平方錯誤。然后,我們可以實例化模型類并運行訓練循環以實現幾個周期。
同樣,由于我們專注于核心自動差分/自動求導功能,這里的目的是使用TensorFlow和特定于Pytorch特定的自動Diff實現構建自定義訓練循環。這些實施方式計算簡單的線性函數的梯度,并用天真梯度下降優化器手動優化權重和偏置參數,基本上最小化了在每個點處使用可微差函數之間計算的實際點和預測之間計算的損失。
對于TensorFlow訓練循環,我明確地使用GradientTape API來跟蹤模型的前向執行和逐步損耗計算。我使用GradientTape的漸變來優化權重和偏置參數。Pytorch提供了一種更“神奇的”自動求導方法,隱式地捕獲參數張量的任何操作,并提供用于優化權重和偏置參數的梯度,而無需調用另一API。一旦我具有權重和偏置梯度,在Pytorch和Tensorflow上實現自定義梯度下降方法就像從這些梯度中減去權重和偏置參數一樣簡單,乘以恒定的學習速率。
請注意,由于Pytorch自動實現自動差分/自動求導,因此在計算后向傳播之后,有必要明確調用no_grad api。這指示Pytorch不計算權重和偏置參數的更新操作的梯度。我們還需要明確釋放在前向操作中計算的先前自動計算的漸變,以阻止Pytorch自動累積較批次和循環迭代中的漸變。
Tensorflow訓練循環
- def squared_error(y_pred, y_true):
- return tf.reduce_mean(tf.square(y_pred - y_true))
- tf_model = LinearRegressionKeras()
- [w, b] = tf_model.trainable_variables
- for epoch in range(epochs):
- with tf.GradientTape() as tape:
- predictions = tf_model(x)
- loss = squared_error(predictions, y)
- w_grad, b_grad = tape.gradient(loss, tf_model.trainable_variables)
- w.assign(w - w_grad * learning_rate)
- b.assign(b - b_grad * learning_rate)
- if epoch % 20 == 0:
- print(f"Epoch {epoch} : Loss {loss.numpy()}")
Pytorch訓練循環
- def squared_error(y_pred, y_true):
- return torch.mean(torch.square(y_pred - y_true))
- torch_model = LinearRegressionPyTorch()
- [w, b] = torch_model.parameters()
- for epoch in range(epochs):
- y_pred = torch_model(inputs)
- loss = squared_error(y_pred, labels)
- loss.backward()
- with torch.no_grad():
- w -= w.grad * learning_rate
- b -= b.grad * learning_rate
- w.grad.zero_()
- b.grad.zero_()
- if epoch % 20 == 0:
- print(f"Epoch {epoch} : Loss {loss.data}")
Pytorch和Tensorflow模型重用可用層
既然我展示了如何從Pytorch和Tensorflow中的原始代碼實現線性回歸模型,我們可以查看如何使用密集和線性層,從TensorFlow和Pytorch庫中重新實現相同的型號。
帶現有圖層的TensoRFlow和Pytorch動態模型
您將在模型初始化方法中注意到,我們正在用TensorFlow中的密集層替換W和B參數的顯式聲明和Pytorch中的線性層。這兩個層都實現了線性回歸,并且我們將指示它們使用單個權重和偏置參數來代替以前使用的顯式W和B參數。密集和線性實現將在內部使用我們之前使用的相同的張解聲明(分別為tf.variable和nn.parameter)來分配這些張量并將它們與模型參數列表相關聯。
我們還將更新這些新模型類的呼叫/前進方法,以替換具有密度/線性層的手動線性回歸計算。
- class LinearRegressionKeras(tf.keras.Model):
- def __init__(self):
- super().__init__()
- self.linear = tf.keras.layers.Dense(1, activation=None) # , input_shape=[1]
- def call(self, x):
- return self.linear(x)
- class LinearRegressionPyTorch(torch.nn.Module):
- def __init__(self):
- super(LinearRegressionPyTorch, self).__init__()
- self.linear = torch.nn.Linear(1, 1)
- def forward(self, x):
- return self.linear(x)
具有可用優化器和損耗函數的訓練
既然我們已經使用現有圖層重新實現了我們的Tensorflow和Pytorch型號,我們可以專注于如何構建更優化的訓練循環。我們不是使用我們以前的Naïve實現,我們將使用這些庫可用的本機優化器和損失函數。
我們將繼續使用之前觀察到的自動差分/自動求導功能,但此時具有標準漸變下降(SGD)優化實現以及標準損耗功能。
Tensorflow訓練循環,易于擬合方法
在Tensorflow中,FIT()是一種非常強大,高級別的訓練模型方法。它允許我們用單個方法替換手動訓練循環,該方法指定超級調整參數。在調用fit()之前,我們將使用Compile()方法編譯模型類,然后通過梯度后代優化器和用于訓練的損失函數。
您會注意到在這種情況下,我們將盡可能多地重用來自TensorFlow庫的方法。特別是,我們將通過標準隨機梯度下降(SGD)優化器和標準的平均絕對誤差函數實現(MEAL_ABSOLUTE_ERROR)到編譯方法。一旦模型進行編譯,我們最終可以撥打擬合方法來完全訓練我們的模型。我們將通過數據(x和y),epochs的數量以及每個時代使用的批量大小。
帶有自定義循環和SGD優化器的TensoRFLOF訓練循環
在以下代碼段中,我們將為我們的模型實施另一個自定義訓練循環,這次盡可能多地重用由Tensorflow庫提供的損失函數和優化器。您會注意到我們的前自定義Python損失函數替換為tf.losses.mse()方法。我們初始化了TF.keras.optimizers.sgd()優化程序而不是用漸變手動更新模型參數。調用Optimizer.apply_gradient()并傳遞權重和偏置元組列表將使用漸變更新模型參數。
- tf_model_train_loop = LinearRegressionKeras()
- optimizer = tf.keras.optimizers.SGD(learning_ratelearning_rate=learning_rate)
- for epoch in range(epochs * 3):
- x_batch = tf.reshape(x, [200, 1])
- with tf.GradientTape() as tape:
- y_pred = tf_model_train_loop(x_batch)
- y_pred = tf.reshape(y_pred, [200])
- loss = tf.losses.mse(y_pred, y)
- grads = tape.gradient(loss, tf_model_train_loop.variables)
- optimizer.apply_gradients(grads_and_vars=zip(grads, tf_model_train_loop.variables))
- if epoch % 20 == 0:
- print(f"Epoch {epoch} : Loss {loss.numpy()}")
具有自定義循環和SGD優化器的Pytorch訓練循環
與上面的上一個Tensorflow代碼段一樣,以下代碼片段通過重用Pytorch庫提供的丟失功能和優化器來實現新模型的Pytorch訓練循環。您會注意到我們將使用NN.Mseloss()方法替換我們以前的自定義Python丟失函數,并初始化標準Optim.sgd()優化程序,其中包含模型的學習參數列表。如前所述,我們將指示Pytorch從丟失向后傳播中獲取每個參數張量的關聯梯度(load.backward()),最后,我們可以通過調用來容易地更新新標準優化器與與梯度相關聯的所有參數更新新的標準優化器優化器.step()方法。Pytorch使張量和梯度之間自動關聯的方式允許優化器檢索張量和梯度以通過配置的學習速率更新它們。
- torch_model = LinearRegressionPyTorch()
- criterion = torch.nn.MSELoss(reduction='mean')
- optimizer = torch.optim.SGD(torch_model.parameters(), lr=learning_rate)
- for epoch in range(epochs * 3):
- y_pred = torch_model(inputs)
- loss = criterion(y_pred, labels)
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- if epoch % 20 == 0:
- print(f"Epoch {epoch} : Loss {loss.data}")
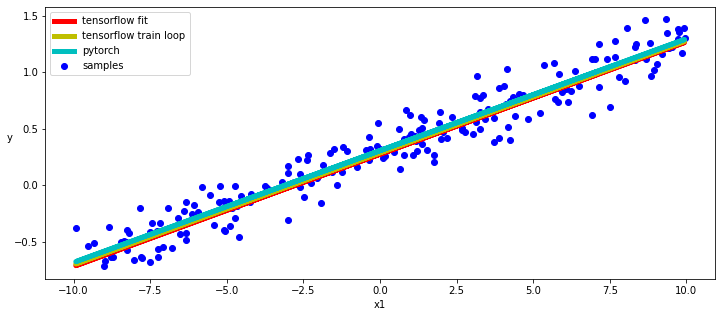
結果
正如我們所看到的那樣,TensoRFlow和Pytorch自動差分和動態子類API非常相似,即使它們使用標準SGD和MSE實現方式也是如此。當然,這兩個模型也給了我們非常相似的結果。
在下面的代碼片段中,我們使用Tensorflow的Training_variables和Pytorch的參數方法來獲得對模型的參數的訪問,并繪制我們學習的線性函數的圖表。
- [w_tf, b_tf] = tf_model_fit.trainable_variables
- [w2_tf, b2_tf] = tf_model_train_loop.trainable_variables
- [w_torch, b_torch] = torch_model.parameters()
- w_tf = tf.reshape(w_tf, [1])
- w2_tf = tf.reshape(w2_tf, [1])
- with torch.no_grad():
- plt.figure(figsize = (12,5))
- ax = plt.subplot(111)
- ax.scatter(x, y, c = "b", label="samples")
- ax.plot(x, w_tf * x + b_tf, "r", linewidth = 5.0, label = "tensorflow fit")
- ax.plot(x, w2_tf * x + b2_tf, "y", linewidth = 5.0, label = "tensorflow train loop")
- ax.plot(x, w_torch * inputs + b_torch, "c", linewidth = 5.0, label = "pytorch")
- ax.legend()
- plt.xlabel("x1")
- plt.ylabel("y",rotation = 0)
結論
Pytorch和新Tensorflow 2.x都支持動態圖形和自動差分核心功能,以提取圖表中使用的所有參數的漸變。您可以輕松地在Python中實現訓練循環,其中包含任何損失函數和漸變后代優化器。為了專注于兩個框架之間的真實核心差異,我們通過實施自己的簡單MSE和NaïveSGD來簡化上面的示例。
但是,我強烈建議您在實現任何Naïve代碼之前重用這些庫上可用的優化和專用代碼。
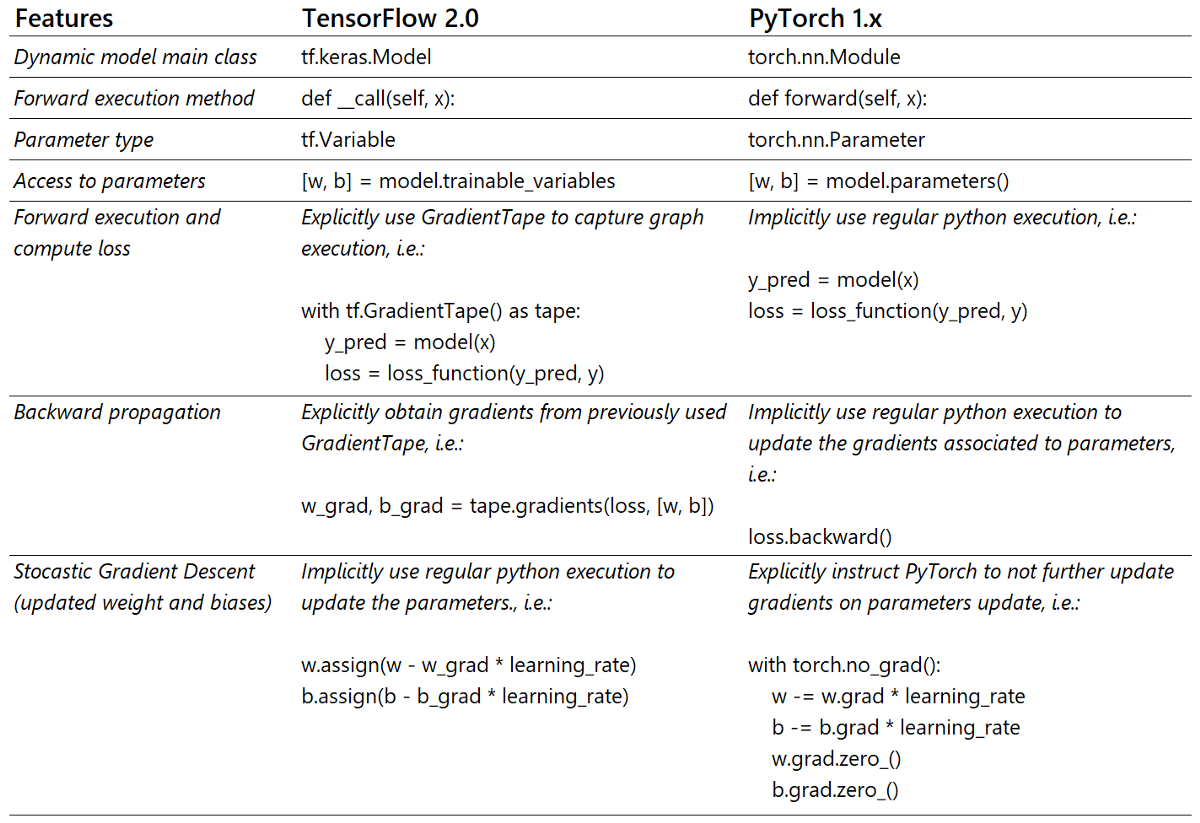
下表總結了上面示例代碼中所注明的所有差異。我希望它可以作為在這兩個框架之間切換時的有用參考。
> Source: Author
原文鏈接:
https://medium.com/data-science-at-microsoft/a-tale-of-two-frameworks-pytorch-vs-tensorflow-f73a975e733d
















