讀了十本書丨Hadoop大數(shù)據(jù)分析及數(shù)據(jù)挖掘讀書筆記,一文總結(jié)

數(shù)據(jù)挖掘基礎(chǔ)
數(shù)據(jù)挖掘的概念:
- 從數(shù)據(jù)中“淘金”,從大量數(shù)據(jù)(文本)中挖掘出隱含的、未知的、對(duì)決策有潛在的關(guān)系、模型和趨勢(shì),并用這些知識(shí)和規(guī)則建立用于決策支持的模型,提供預(yù)測(cè)性決策支持的方法、工具和過程,這就是數(shù)據(jù)挖掘。
它是利用各種分析工具在大量數(shù)據(jù)中尋找其規(guī)律和發(fā)現(xiàn)模型與數(shù)據(jù)之間關(guān)系的過程,是統(tǒng)計(jì)學(xué)、數(shù)據(jù)技術(shù)和人智能智能技術(shù)的綜合。
數(shù)據(jù)挖掘的基本任務(wù):
- 包括利用分類與預(yù)測(cè)、聚類分析、關(guān)聯(lián)規(guī)則、時(shí)序模式、偏差檢測(cè)、職能推薦等方法,幫助企業(yè)提取數(shù)據(jù)中蘊(yùn)含的商業(yè)價(jià)值,提高企業(yè)的競(jìng)爭(zhēng)力。
1 目標(biāo)定義
- 任務(wù)理解
- 指標(biāo)確認(rèn)
針對(duì)具體的挖掘應(yīng)用需求明確本次挖掘目標(biāo)是什么?系統(tǒng)完成后能達(dá)到什么樣的效果?
2 數(shù)據(jù)采集
建模抽樣
抽樣數(shù)據(jù)的標(biāo)準(zhǔn),一是相關(guān)性、二是可靠性、三是有效性。
抽樣的方式
- 隨機(jī)抽樣:比如按10%比例隨機(jī)抽樣
- 等距抽樣:比如按5%比例,一共100組,取20、40、60、80、100
- 分層抽樣:將樣本分若干層次,每個(gè)層次設(shè)定不同的概率。
- 從起始順序抽樣:從輸入數(shù)據(jù)集的起始處開始。
- 分類抽樣:依據(jù)某種屬性的取值來選擇數(shù)據(jù)子集。如按客戶名稱分類、按地址區(qū)域分類等。分類抽樣的選取方式就是前面所述的幾種方式,只是抽樣以類為單位。
質(zhì)量把控
實(shí)時(shí)采集
3 數(shù)據(jù)整理
數(shù)據(jù)探索
對(duì)所抽樣的樣本數(shù)據(jù)進(jìn)行探索、審核和必要的加工處理,是保證最終的挖掘模型的質(zhì)量所必須的。
常用的數(shù)據(jù)探索方法主要包括兩方面:數(shù)據(jù)質(zhì)量分析,數(shù)據(jù)特征分析。
- 數(shù)據(jù)質(zhì)量分析:得主要任務(wù)是檢查原始數(shù)據(jù)中是否存在臟數(shù)據(jù)。包括缺失值分析、異常值分析、數(shù)據(jù)一致性分析。
- 數(shù)據(jù)特征分析:在質(zhì)量分析后可通過繪制圖標(biāo)、計(jì)算某種特征量等手段進(jìn)行特征分析,
主要包括
- 分布分析:能揭示數(shù)據(jù)的分布特征和分布類型。可用直方圖、餅圖、條形圖等展示
- 對(duì)比分析:將兩個(gè)相互聯(lián)系的指標(biāo)進(jìn)行比較,從數(shù)據(jù)量上展示和說明研究對(duì)象規(guī)模的大小,水平的高低,速度的快慢,以及各種關(guān)系是否協(xié)調(diào)。比如,各部門的銷售金額的比較、各年度的銷售額對(duì)比。
- 統(tǒng)計(jì)量分析:用統(tǒng)計(jì)指標(biāo)對(duì)定量數(shù)據(jù)進(jìn)行統(tǒng)計(jì)描述,常從集中和離中趨勢(shì)兩個(gè)方面進(jìn)行分析。平均水平的指標(biāo)是對(duì)個(gè)體集中趨勢(shì)的度量,最廣泛是均值和中位數(shù);反映變異程度的指標(biāo)則是對(duì)個(gè)體離開平均水平的度量,使用較廣泛的是標(biāo)準(zhǔn)差(方差)、四分衛(wèi)間距。
- 周期性分析:分析某個(gè)變量是否跟著時(shí)間變化而呈現(xiàn)出某種周期變化趨勢(shì)。
- 貢獻(xiàn)度分析:原理是帕累托法則(又稱20/80定律)
- 相關(guān)性分析:分析連續(xù)變量之間線性相關(guān)程度的強(qiáng)弱,并用適當(dāng)?shù)慕y(tǒng)計(jì)指標(biāo)表示出來的過程稱為相關(guān)分析。判斷兩個(gè)變量是否具有線性相關(guān)關(guān)系的最直觀的方法是直接繪制散點(diǎn)圖。多元線性回歸。
數(shù)據(jù)清洗
數(shù)據(jù)清洗主要是刪除原始數(shù)據(jù)集中的無關(guān)數(shù)據(jù)、重復(fù)數(shù)據(jù)、平滑噪音數(shù)據(jù),刷選調(diào)與挖掘主題無關(guān)的數(shù)據(jù),處理缺失值,異常值等。
缺失值處理:刪除記錄、數(shù)據(jù)插補(bǔ)和不處理。
異常值處理:直接刪除、提油現(xiàn)有變量,進(jìn)行填補(bǔ)。
數(shù)據(jù)變換
數(shù)據(jù)變換主要是對(duì)數(shù)據(jù)進(jìn)行規(guī)范化處理,將數(shù)據(jù)轉(zhuǎn)換成“適當(dāng)”形勢(shì),以適用與挖掘任務(wù)與算法的需要。
常見的數(shù)據(jù)變換方法,簡(jiǎn)單函數(shù)變換、規(guī)范化、連續(xù)屬性離散化,屬性構(gòu)造,小波變換。
數(shù)據(jù)規(guī)約
數(shù)據(jù)規(guī)約產(chǎn)生更小但保持元數(shù)據(jù)完整性的新數(shù)據(jù)集。提高效率。主要包括屬性規(guī)約和數(shù)值規(guī)約。
數(shù)據(jù)集成
數(shù)據(jù)來源往往分布在不同的數(shù)據(jù)源中,數(shù)據(jù)集成就是將數(shù)據(jù)源合并存在一個(gè)一致性的數(shù)據(jù)存儲(chǔ)。
4 構(gòu)建模型
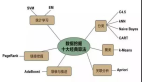
樣本抽取完并經(jīng)預(yù)處理,對(duì)本次建模進(jìn)行確認(rèn),是分類、聚合、關(guān)聯(lián)規(guī)則、時(shí)序模式或者職能推薦,以便后續(xù)選用哪種算法進(jìn)行模型構(gòu)建。這一步是核心環(huán)節(jié)。
針對(duì)餐飲行業(yè)的數(shù)據(jù)挖掘應(yīng)用,挖掘建模主要基于關(guān)聯(lián)規(guī)則算法的動(dòng)態(tài)菜品智能推薦、基于聚類算法的餐飲客戶價(jià)值分析、基于分類與預(yù)測(cè)算法的菜品銷售預(yù)測(cè)、基于整體優(yōu)化的新店選址。
- 模型發(fā)現(xiàn)
- 構(gòu)建模型
- 驗(yàn)證模型
5 模型評(píng)價(jià)
為了確保模型有效,需要對(duì)其進(jìn)行測(cè)試評(píng)價(jià),目的找出一個(gè)最好的模型。
為了有效判斷一個(gè)預(yù)測(cè)模型的性能表現(xiàn),需要一組沒有參與預(yù)測(cè)模型建立的數(shù)據(jù)集,并在該數(shù)據(jù)集上評(píng)價(jià)預(yù)測(cè)模型的精準(zhǔn)率。
- 設(shè)定評(píng)價(jià)標(biāo)準(zhǔn)
- 多模型對(duì)比
- 模型優(yōu)化
6 模型發(fā)布
- 模型部署
- 模型重構(gòu)
小結(jié)
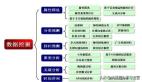
本章從一個(gè)知名餐飲企業(yè)經(jīng)營(yíng)過程中存在的困惑出發(fā),引出數(shù)據(jù)挖掘的概念、基本任務(wù)、建模過程。
針對(duì)建模過程,簡(jiǎn)要分析了定義挖掘目標(biāo)、數(shù)據(jù)取樣、數(shù)據(jù)塔索、數(shù)據(jù)預(yù)處理以及挖掘建模的各個(gè)算法概述和模型評(píng)價(jià)。
如何幫助企業(yè)從數(shù)據(jù)中洞察商機(jī)、提取價(jià)值,這是現(xiàn)階段幾乎所有企業(yè)都關(guān)心的問題。通過發(fā)生在身邊的案例,由淺入深引出深?yuàn)W的數(shù)據(jù)挖掘理論,讓讀者感悟數(shù)據(jù)挖掘的非凡魅力。點(diǎn)贊
個(gè)人看完這一章,對(duì)于數(shù)據(jù)挖掘的落地有了一個(gè)大概得了解,我們選擇、使用、學(xué)習(xí)這些大數(shù)據(jù)的技術(shù)應(yīng)該是結(jié)果導(dǎo)向的,這里會(huì)讓人更清晰去選擇技術(shù),使用技術(shù)。
Hadoop基礎(chǔ)
大數(shù)據(jù)技術(shù),是指從各種類型的數(shù)據(jù)中,快速獲得由價(jià)值信息的能力。適用大技術(shù)的技術(shù),包括大規(guī)模并行處理(MPP)數(shù)據(jù)庫(kù),數(shù)據(jù)挖掘,分布式文件系統(tǒng),分布式數(shù)據(jù)庫(kù),云計(jì)算平臺(tái),互聯(lián)網(wǎng)和可擴(kuò)展的存儲(chǔ)系統(tǒng)。
大數(shù)據(jù)特點(diǎn)4V
- 數(shù)據(jù)量大(Volume)
- 數(shù)據(jù)類型復(fù)雜(Variety)
- 數(shù)據(jù)處理速度快(Velocity)
- 數(shù)據(jù)真實(shí)性高(Veracity)
當(dāng)前,Hadoop已經(jīng)成為了事實(shí)上的標(biāo)準(zhǔn)。
Hadoop除了社區(qū)版,還有其他廠商發(fā)行的版本。
- Cloudera:最成型的發(fā)行版本,擁有最多的部署案例;
- Hortonworks:100%開源的Apache Hadoop唯一提供商。
- MapR:
- Amazon Elastic Map Reduce(EMR):這是一個(gè)托管的解決方案。
生態(tài)系統(tǒng)
Hadooop生態(tài)系統(tǒng)主要包括:Hive、HBase、Pig、Sqoop、Flume、Zookeeper、Mahout、Spark、Storm、Shark、Phoenix、Tex、Ambari
Hive[haɪv]:數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng)
用于Hadoop的一個(gè)數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng),它提供了類似SQL的查詢語言,通過使用該語言, 可以方便地進(jìn)行數(shù)據(jù)匯總,特定查詢以及分析存放在Hadoop兼容文件系統(tǒng)中的大數(shù)據(jù)。
hive基于hdfs構(gòu)建了數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng),它以hdfs作為存儲(chǔ),依賴于數(shù)據(jù)庫(kù)(嵌入式的數(shù)據(jù)庫(kù)derby或者獨(dú)立的數(shù)據(jù)mysql或oracle)存儲(chǔ)表schema信息,并完成基于sql自動(dòng)解析創(chuàng)建mapreduce任務(wù)(由于mapreduce計(jì)算效率比較差,目前官方推薦的是底層計(jì)算模型采用tez或者spark)。
所以hive可以理解為:hdfs原始存儲(chǔ)+DB Schema信息存儲(chǔ)+SQL解析引擎+底層計(jì)算框架組成的數(shù)據(jù)倉(cāng)庫(kù)。
Hbase:分布式數(shù)據(jù)庫(kù)
一種分布式、可伸縮的、大數(shù)據(jù)庫(kù)存儲(chǔ)庫(kù),支持隨機(jī)、實(shí)施讀/寫訪問。
Pig:工作流引擎
Pig是一種編程語言,它簡(jiǎn)化了Hadoop常見的工作任務(wù)。Pig可加載數(shù)據(jù)、表達(dá)轉(zhuǎn)換數(shù)據(jù)以及存儲(chǔ)最終結(jié)果。Pig內(nèi)置的操作使得半結(jié)構(gòu)化數(shù)據(jù)變得有意義(如日志文件)。同時(shí)Pig可擴(kuò)展使用Java中添加的自定義數(shù)據(jù)類型并支持?jǐn)?shù)據(jù)轉(zhuǎn)換。
sqoop[skup]:數(shù)據(jù)庫(kù)ETL工具
為高效傳輸批量數(shù)據(jù)而設(shè)計(jì)的一種工具,其用于Apache Hadoop和結(jié)構(gòu)化數(shù)據(jù)存儲(chǔ)庫(kù)如關(guān)系數(shù)據(jù)庫(kù)之間的數(shù)據(jù)傳輸。
Flume:日志收集
一種分布式、可靠的、可用的服務(wù),其用于高效搜集、匯總、移動(dòng)大量日志數(shù)據(jù)
ZooKeeper[ˈzu:ki:pə(r)]:協(xié)同服務(wù)管理
一種集中服務(wù)、其用于維護(hù)配置信息,命名,提供分布式同步,以及提供分組服務(wù)。
HDFS:分布式數(shù)據(jù)存儲(chǔ)系統(tǒng)
hdfs是大數(shù)據(jù)系統(tǒng)的基礎(chǔ),它提供了基本的存儲(chǔ)功能,由于底層數(shù)據(jù)的分布式存儲(chǔ),上層任務(wù)也可以利用數(shù)據(jù)的本地性進(jìn)行分布式計(jì)算。hdfs思想上很簡(jiǎn)單,就是namenode負(fù)責(zé)數(shù)據(jù)存儲(chǔ)位置的記錄,datanode負(fù)責(zé)數(shù)據(jù)的存儲(chǔ)。使用者client會(huì)先訪問namenode詢問數(shù)據(jù)存在哪,然后去datanode存儲(chǔ);寫流程也基本類似,會(huì)先在namenode上詢問寫到哪,然后把數(shù)據(jù)存儲(chǔ)到對(duì)應(yīng)的datanode上。所以namenode作為整個(gè)系統(tǒng)的靈魂,一旦它掛掉了,整個(gè)系統(tǒng)也就無法使用了。在運(yùn)維中,針對(duì)namenode的高可用變得十分關(guān)鍵。
Mahout[məˈhaʊt]:算法集
一種基于Hadoop的機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘的分布式計(jì)算框架算法集,實(shí)現(xiàn)了多重MapReduce模式的數(shù)據(jù)挖掘算法。
spark:計(jì)算模型
一種開源的數(shù)據(jù)分析集群計(jì)算框架,建立于HDFS紙上。于Hadoop一樣,用于構(gòu)建大規(guī)模、低延時(shí)的數(shù)據(jù)分析應(yīng)用。它采用Scala語言實(shí)現(xiàn),使用Scala作為應(yīng)用框架。
spark是現(xiàn)在大數(shù)據(jù)中應(yīng)用最多的計(jì)算模型,它與java8的stream編程有相同的風(fēng)格。封裝了很多的計(jì)算方法和模型,以延遲執(zhí)行的方式,在真正需要執(zhí)行的時(shí)候才進(jìn)行運(yùn)算。既可以有效的做計(jì)算過程的容錯(cuò),也可以改善我們的編程模型。
Spark是一款很棒的執(zhí)行引擎,我們可以看到大部分的Spark應(yīng)用,是作為Hadoop分布式文件系統(tǒng)HDFS的上層應(yīng)用。
( Spark 典型的取代了已經(jīng)過時(shí)的MapReduce引擎,與Hadoop YARN (Yet Another Resource Negotiator,另一種資源協(xié)調(diào)者)或者分布式計(jì)算框架Mesos一起工作,有時(shí)候同時(shí)與兩者一起作為一個(gè)計(jì)劃進(jìn)行)
但是Cutting強(qiáng)調(diào):“還有許多事情Spark是做不到的。”比如:它不是一個(gè)全文本搜索引擎;是Solr在Hadoop里扮演著這個(gè)角色。它可以運(yùn)行SQL查詢對(duì)抗Spark,但是它沒有被設(shè)計(jì)成一個(gè)交互式查詢系統(tǒng),對(duì)此,Cutting提出,Impala可以實(shí)現(xiàn)交互查詢。
如果你只是要需要進(jìn)行streaming 編程或者batch 編程,那么你需要一個(gè)執(zhí)行引擎,Spark就是很棒的一個(gè)。但是人們想做的事情遠(yuǎn)不止于此,他們想實(shí)現(xiàn)交互式SQL(結(jié)構(gòu)化查詢語言),他們想實(shí)現(xiàn)搜索,他們想做各種涉及系統(tǒng)的實(shí)時(shí)處理,如Kafka(一種高吞吐量的分布式發(fā)布訂閱消息系統(tǒng))…我認(rèn)為那些認(rèn)為Spark就是整個(gè)堆的人是確實(shí)存在的少數(shù)情況。
Storm:
一個(gè)分布式、容錯(cuò)的實(shí)時(shí)計(jì)算系統(tǒng)。
Shark[ʃɑ:k]:SQL查詢引擎
Hive on Spark,一個(gè)專門為Spark打造的大規(guī)模數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng),兼容Apache Hive。無需修改現(xiàn)有的數(shù)據(jù)或者查詢,就可以用100倍的速度執(zhí)行Hive SQL。Shark支持Hive查詢語言、元存儲(chǔ)、序列化格式及自定義函數(shù),與現(xiàn)有Hive部署無縫集成,是一個(gè)更快、更強(qiáng)大的替代方案。
Phoenix:
一個(gè)構(gòu)建在Apache HBase之上的一個(gè)SQL中間層,完全使用Java編寫,提供了一個(gè)客戶端可嵌入的JDBC驅(qū)動(dòng)。
Tez:
一個(gè)機(jī)遇Hadoop YARN之上的DAG計(jì)算框架。它把Map/Reduce過程拆分成若干個(gè)子過程。同時(shí)可以把多個(gè)Map/Reduce任務(wù)組合成一個(gè)較大的DAG任務(wù),減少M(fèi)ap/Reduce之間的文件存儲(chǔ)。同時(shí)合理組合其子過程,減少任務(wù)的運(yùn)行時(shí)間。
Amari:安裝部署工具
一個(gè)供應(yīng)、管理和監(jiān)視Apache Hadoop集群的開源框架,它提供一個(gè)直觀的操作工具和一個(gè)健壯的Hadoop Api,
MapReduce:
說穿了就是函數(shù)式編程,把所有的操作都分成兩類,map與reduce,map用來將數(shù)據(jù)分成多份,分開處理,reduce將處理后的結(jié)果進(jìn)行歸并,得到最終的結(jié)果。
ChuKwa:
YARN[jɑ:n]:Hadoop 資源管理器
Hadoop HDFS
HDFS被設(shè)計(jì)成適合在通用硬件上的分布式文件系統(tǒng)。具有如下特點(diǎn)
具有高度容錯(cuò)性的系統(tǒng)。設(shè)計(jì)用來部署在低廉的硬件上,提供高吞吐量,適合那些有超大數(shù)據(jù)集的應(yīng)用程序,放寬了POSIX的要求這樣可以實(shí)現(xiàn)以流的形式(streaming access)訪問文件系統(tǒng)中的數(shù)據(jù)。
HDFS采用master/slave。一個(gè)集群由一個(gè)NameNode和多個(gè)DataNodes組成。
- Active Namenode:主 Master(只有一個(gè)),管理 HDFS 的名稱空間,管理數(shù)據(jù)塊映射信息;配置副本策略;處理客戶端讀寫請(qǐng)求。
- Secondary NameNode:NameNode 的熱備;定期合并 fsimage 和 fsedits,推送給 NameNode;當(dāng) Active NameNode 出現(xiàn)故障時(shí),快速切換為新的 Active NameNode。
- Datanode:Slave(有多個(gè));存儲(chǔ)實(shí)際的數(shù)據(jù)塊;執(zhí)行數(shù)據(jù)塊讀 / 寫。
- Client:與 NameNode 交互,獲取文件位置信息;與 DataNode 交互,讀取或者寫入數(shù)據(jù);管理 HDFS、訪問 HDFS。
Hive
概念
Hive最初是Facebook面對(duì)海量數(shù)據(jù)和機(jī)器學(xué)習(xí)的需求而產(chǎn)生和發(fā)展的,是建立在Hadoop上數(shù)據(jù)倉(cāng)庫(kù)基礎(chǔ)架構(gòu),它可以將結(jié)構(gòu)化的數(shù)據(jù)文件映射為一張數(shù)據(jù)庫(kù)表,并提供簡(jiǎn)單的SQL查詢功能。
Hive作為數(shù)據(jù)倉(cāng)庫(kù),提供一系列工具,可以用來進(jìn)行數(shù)據(jù)提取轉(zhuǎn)化加載(ETL),這是一種可以存儲(chǔ)、查詢和分析存儲(chǔ)在Hadoop中的大規(guī)模數(shù)據(jù)的機(jī)制。
Hive定義了簡(jiǎn)單的類SQL查詢語言,成為HQL,它允許熟悉SQL用戶查詢數(shù)據(jù)。
特點(diǎn)
- 支持索引,加快數(shù)據(jù)查詢。
- 不同的存儲(chǔ)類型,如純文本文件、HBase中的文件。
- 將元數(shù)據(jù)保存在關(guān)系數(shù)據(jù)庫(kù)中,大大減少了在查詢過程中執(zhí)行語義檢查的時(shí)候。
- 可以直接使用存儲(chǔ)在Hadoop文件系統(tǒng)中的數(shù)據(jù)。
- 內(nèi)置大量用戶函數(shù)UDF來操作時(shí)間、字符串和其他的數(shù)據(jù)挖掘工具,支持用戶擴(kuò)展UDF函數(shù)來完成內(nèi)置函數(shù)無法實(shí)現(xiàn)的操作。
- 類SQL的查詢方式,將SQL查詢轉(zhuǎn)換為MapReduce的Job在Hadoop集群上執(zhí)行
Hive并不能夠在大規(guī)模數(shù)據(jù)集上實(shí)現(xiàn)低延遲快速的查詢,不能提供實(shí)時(shí)的查詢和基于行級(jí)的數(shù)據(jù)更新操作。比如幾百M(fèi)B的數(shù)據(jù)集上執(zhí)行查詢一般有分鐘級(jí)的時(shí)間延遲。所以它不適合低延遲的應(yīng)用。最佳應(yīng)用在大數(shù)據(jù)集的批處理作業(yè),如網(wǎng)絡(luò)日志分析。
Hive支持的數(shù)據(jù)模型
- 表:存在在HDFS目錄底下,固定目錄
- 外部表:跟表差不多,指定目錄
分區(qū):
- 桶:對(duì)指定的列計(jì)算其哈希值,根絕哈希值切分?jǐn)?shù)據(jù),目的是并行,每個(gè)桶對(duì)應(yīng)一個(gè)文件。
Hbase
概念
Hbase是一個(gè)分布式、面向列的開源數(shù)據(jù)庫(kù),利用HBASE技術(shù)可以在廉價(jià)PC服務(wù)器搭建大規(guī)模結(jié)構(gòu)化存儲(chǔ)集群。它不是關(guān)系型數(shù)據(jù)庫(kù),是一個(gè)適合非結(jié)構(gòu)化的數(shù)據(jù)存儲(chǔ)數(shù)據(jù)庫(kù)。它利用Hadoop MapReduce來處理HBase中的海量數(shù)據(jù),同時(shí)利用Zookeeper作為其協(xié)同服務(wù)。
采購(gòu)LSM算法,后面繼續(xù)深入研究,這個(gè)算法,是在內(nèi)存中對(duì)未排序的值進(jìn)行,拆分排序,比如N個(gè)數(shù),每M個(gè)拆分一次做排序,那么每次尋找的計(jì)算量應(yīng)該是N/M*log2M
特點(diǎn)
- 線性和模塊化可擴(kuò)展性
- 嚴(yán)格一致的讀取和寫入
- 表的自動(dòng)配置和分片
- 支持RegionServers之間的自動(dòng)故障轉(zhuǎn)移
- 方便的基類支持Hadoop的MapReduce作業(yè)與Apache HBase的表
- 易于使用的Java API的客戶端訪問
- 塊緩存和布魯姆過濾器實(shí)時(shí)查詢
- Thrift網(wǎng)管和REST-FUL Web服務(wù)支持XML、protobuf和二進(jìn)制的數(shù)據(jù)編碼選項(xiàng);
- 可擴(kuò)展的基于JRuby(JIRB)的腳本;
- 支持監(jiān)控信息通過Hadoop子系統(tǒng)導(dǎo)出到文件或Ganglia
Pig和Hive還為HBase提供了高層語言支持,這使得HBase上進(jìn)行數(shù)據(jù)統(tǒng)計(jì)處理變得非常簡(jiǎn)單。Sqoop則為HBase提供了RDBMS數(shù)據(jù)導(dǎo)入功能,使用傳統(tǒng)數(shù)據(jù)庫(kù)向HBase遷移變得很方便。
原理
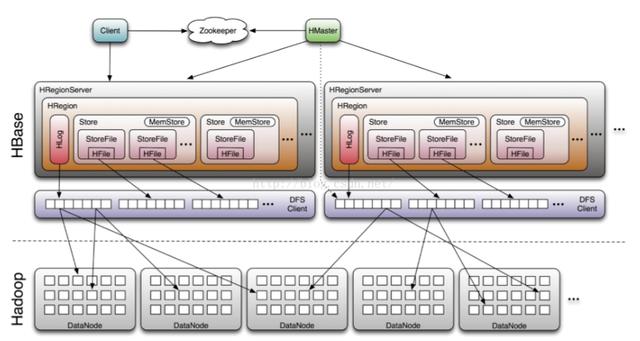
HBase構(gòu)建在HDFS之上,其組件包括 Client、zookeeper、HDFS、Hmaster以及HRegionServer。Client包含訪問HBase的接口,并維護(hù)cache來加快對(duì)HBase的訪問。Zookeeper用來保證任何時(shí)候,集群中只有一個(gè)master,存貯所有Region的尋址入口以及實(shí)時(shí)監(jiān)控Region server的上線和下線信息。并實(shí)時(shí)通知給Master存儲(chǔ)HBase的schema和table元數(shù)據(jù)。HMaster負(fù)責(zé)為Region server分配region和Region server的負(fù)載均衡。如果發(fā)現(xiàn)失效的Region server并重新分配其上的region。同時(shí),管理用戶對(duì)table的增刪改查操作。Region Server 負(fù)責(zé)維護(hù)region,處理對(duì)這些region的IO請(qǐng)求并且切分在運(yùn)行過程中變得過大的region。
Hbase底層使用還是Hadoop的HDFS。同時(shí)包含3個(gè)重要組件,
- Zookeeper:為整個(gè)HBase集群提供協(xié)助的服務(wù)(信息傳輸);
- HMaster:監(jiān)控和操作集群中所有的RegionServer;
- HregionServer:服務(wù)和管理分區(qū)(regions)。
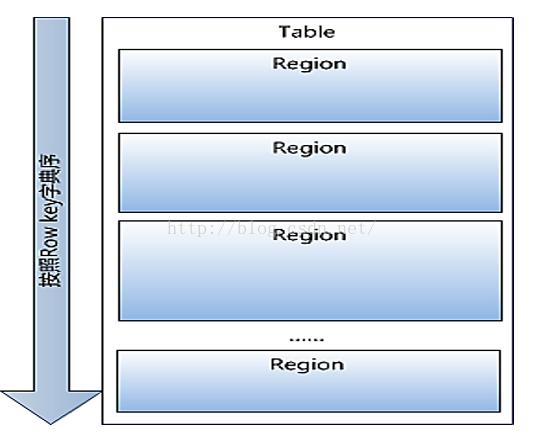
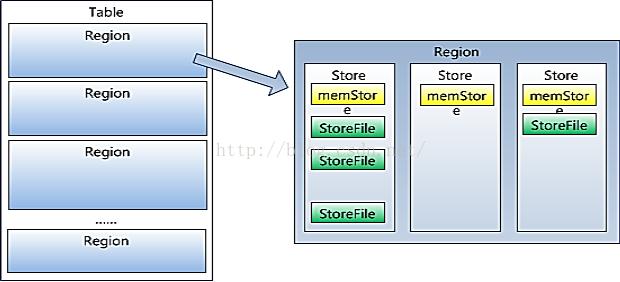
**Region:**Hbase的Table中的所有行都按照row key的字典序排列。Table 在行的方向上分割為多個(gè)Region。、Region按大小分割的,每個(gè)表開始只有一個(gè)region,隨 著數(shù)據(jù)增多,region不斷增大,當(dāng)增大到一個(gè)閥值的時(shí)候, region就會(huì)等分會(huì)兩個(gè)新的region,之后會(huì)有越來越多的 region。
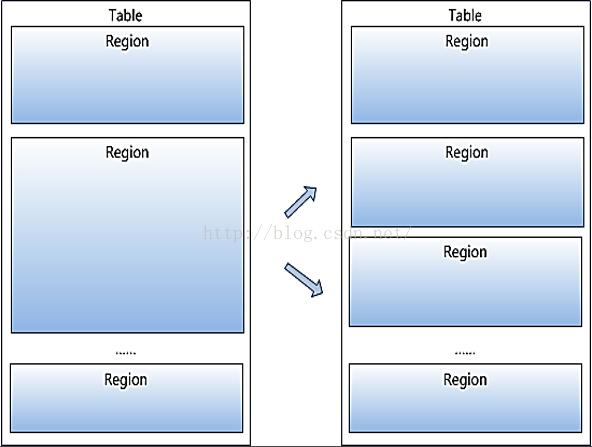
Region是HBase中分布式存儲(chǔ)和負(fù)載均衡的最小單元。 不同Region分布到不同RegionServer上。
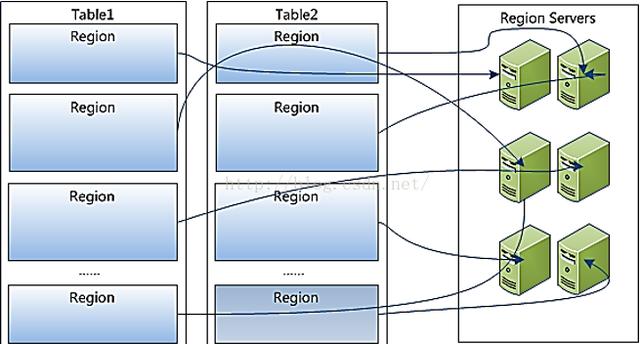
Region雖然是分布式存儲(chǔ)的最小單元,但并不是存儲(chǔ) 的最小單元。Region由一個(gè)或者多個(gè)Store組成,每個(gè)store保存一個(gè) columns family。每個(gè)Strore又由一個(gè)memStore和0至多個(gè)StoreFile組成。memStore存儲(chǔ)在內(nèi)存中,StoreFile存儲(chǔ)在HDFS上。
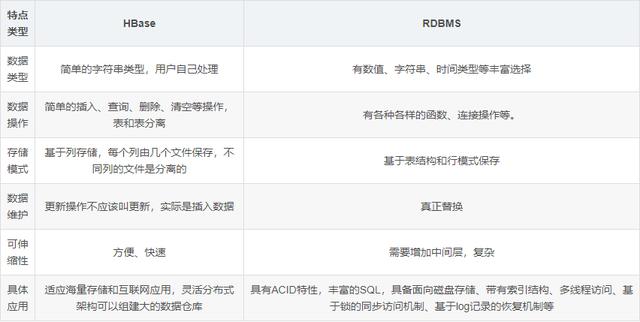
HBase和RDBMS的區(qū)別
HBASE設(shè)計(jì)的初衷是針對(duì)大數(shù)據(jù)進(jìn)行隨機(jī)地、實(shí)時(shí)地讀寫操作。區(qū)別
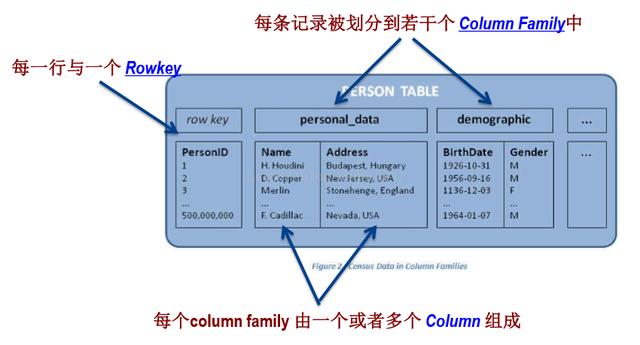
HBase數(shù)據(jù)模型
傳統(tǒng)型數(shù)據(jù)庫(kù)以行的形式存儲(chǔ)數(shù)據(jù),每行數(shù)據(jù)包含多列,每列只有單個(gè)值。在HBase中,數(shù)據(jù)實(shí)際存儲(chǔ)在一個(gè)“映射”中,并且“映射”的鍵(key)是被排序的。類似JavaScript Object(JSON)
HBase包含如下幾個(gè)概念:
1 Row key
一條記錄的唯一標(biāo)示
2 column family
一列數(shù)據(jù)的集合的存儲(chǔ)體,作為列簇
3 Column qualifier
在列簇中的每個(gè)列數(shù)據(jù)的限定符,用于指定數(shù)據(jù)的屬性
4 Cell
實(shí)際存儲(chǔ)的數(shù)據(jù),包含數(shù)據(jù)和時(shí)間戳
小結(jié)
這里介紹大數(shù)據(jù)數(shù)據(jù)庫(kù)HBASE的基礎(chǔ)概念,分析了HBase的原理,主要包括其與RDBMS的對(duì)比、訪問接口、數(shù)據(jù)模型等。最后結(jié)構(gòu)HBase的架構(gòu)圖介紹各個(gè)模塊組件,包括HMaster、HRegionServer、Zookeeper
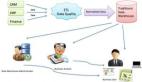
大數(shù)據(jù)挖掘建模平臺(tái)
本章首先介紹常用的大數(shù)據(jù)平臺(tái),采用開源的TipDM-HB大數(shù)據(jù)挖掘建模平臺(tái)。
SOA架構(gòu),面向服務(wù)架構(gòu),以為著服務(wù)接口、流程整合、資源可利用、管控。
挖掘建模
經(jīng)過數(shù)據(jù)探索與數(shù)據(jù)預(yù)處理,得到了可以建模的數(shù)據(jù)。
根據(jù)挖掘目標(biāo)和數(shù)據(jù)形式可以建立分類與預(yù)測(cè)、聚類分析、關(guān)聯(lián)規(guī)則、職能推薦等模型。