













一份藍圖:量子計算機該如何走向實用時代?
通用型量子計算機的開發之路雖然艱難,但并非不可能。

經典魔方擁有43252003274489856000種可能的組合。大家可能會好奇,人類是如何將這樣一個經過加擾的多維數據集恢復至初始狀態,即每側僅排布同一種顏色的。更夸張的是,有些人在看過一遍打亂后的狀態后,蒙上眼睛也能把魔方快速復原。之所以可行,是因為魔方的排列背后存在一套基本規則,因此操作者總是能夠在20步或者更少的操作量之內將其還原至初始狀態。
控制量子計算機,在原理上有點像蒙住眼睛破解魔方:初始狀態一目了然,而且基本元素(量子比特)也是明確且有限的,可以通過一且簡單的規則進行操作及表達(表示量子態的旋轉向量)。但問題在于,操作過程中一旦行觀察,就會給系統的運轉結果造成嚴重影響:如果查看過早,則計算將受到干擾。換言之,我們只能查看計算給出的最終狀態。
量子計算機的強大之處在于,這套系統可能同時處于多種組合狀態當中。不少專家認為這種特性意味著量子計算機根本不可能被創造出來——即使被創造出來,也無法有效操控。他們的理由也明確,描述狀態組合所需要的參數實在太多。沒錯,控制量子計算機并確保其狀態不受各類錯誤源干擾本身,確實是一項極為困難的工程學挑戰。但是,真正的難點并不在于復雜的量子態,而更多體現在保證基礎控制信號集正常起產方面——如果保證不了這一點,我們根本無法驗證量子比特的行為是否與預期相符。
如果工程師們能夠找出答案,那么量子計算機終有一天會解決當前經典計算機搞不定的難題,包括破解傳統意義上無法破解的密碼、加快新藥的發現、改善機器學習系統并解決極為復雜的物流優化問題等等。
人們的期望高漲,科技企業與各國政府也將數十億美元砸向量子計算機研究領域。但這仍是一場賭博,因為成就這一切巨大潛力的量子力學效應,同時也導致這類設備極為敏感且難以控制。
但結果必然如此嗎?經典超級計算機與量子計算機之間的核心差異,在于后者會利用某些量子力學效應以反直覺的方式進行數據操控。這里我們只能簡單聊聊純技術內容,但相信這樣的表述應該足夠幫助大家理解量子計算機在工程設計層面的難度,以及克服這些障礙的某些可行策略。
傳統經典計算機面對的是二進制比特,每一位必須為0或1;量子計算機面對的則是qubits,即量子比特。與經典比特不同,量子比特可利用疊加態這一量子力學效應,使得單一量子比特同時處于0與1的疊加狀態。在描述某個量子比特的狀態時,我們實際上是在描述其處于1與0所對應的概率系數——這將是一個復數,由實部與虛部共同構成。
經典超級計算機與量子計算機之間的核心差異,在于后者會利用某些量子力學效應以反直覺的方式進行數據操控。
在一臺多量子比特計算機當中,我們可以通過非常特殊的方式創建量子比特,確保某一量子比特的狀態無法以脫離另一量子比特狀態的前提下進行描述。這種現象被稱為糾纏態——多個量子比特的糾纏態,要比單一量子比特的狀態更加復雜。
二比特經典二進制組合只能表達00、01、10及11這四種狀態,但兩個相互糾纏的量子比特卻能夠處于這四種基礎狀態的疊加態中。換言之,兩個相互糾纏的量子比特可能包含一定的00度、一定的01度、一定的10度以及一定的11度。三個量子比特相互糾纏將代表八種基本狀態的疊加。因此,n個量子比特將處于2n個狀態的疊加態。在對這n個相互糾纏的量子比特執行操作時,將等同于同時處理2n位信息。
我們對量子比特執行的操作,類似于旋轉魔方。但最大的區別在于,量子旋轉永遠不可能完美。由于信號質量控制能力的限制以及量子比特極高的敏感度,我們對量子比特旋轉90度的操作很可能最終帶來了90.1或者89.9度的結果。這樣的錯誤看似不大,但其影響會快速疊加起來,最終輸出完全錯誤的結果。
提高實現門檻的另一個因素是退相干:量子比特會逐漸失去其承載的信息,即脫離糾纏態。引發這種情況的原因,在于量子比特與環境之間存在一定程度的相互作用,即使存儲量子比特的物理基質經過精心設計、高度隔離,仍無法徹底消除這種作用。雖然我們可以使用所謂量子誤差校正來補償誤差控制與退相干造成的影響,但這同時要求我們引入更多物理量子比特,而它們同樣需要受到相應的校正保護。
不過一旦克服了上述技術難題,量子計算機將在某些特殊類型的計算中發揮出無可比擬的價值。在量子算法執行完畢后,設備將測量其最終狀態,并在理論上解決眾多經典計算機無法在合理時間內解決的數學問題。
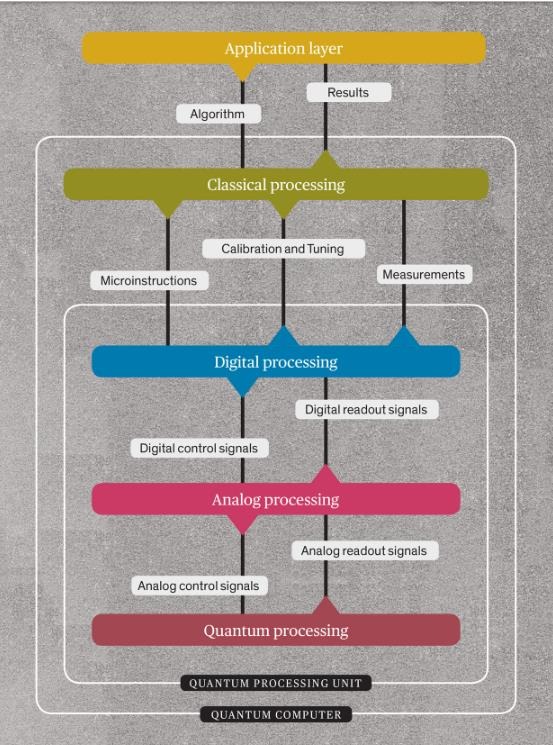
那么,我們要如何設計一臺量子計算機?在工程層面,目前的最佳作法是將機器的主要功能拆分成多個包含相似性質或者所需性能的子功能組。這些功能組能夠更輕松地與硬件映射起來。我和我的同事們發現,量子計算機所需要的功能可以天然劃分為五類,即概念意義上的五種控制層。IBM、谷歌、英特爾以及其他各類企業機構的研究人員都在遵循類似的策略。當然,這只是可能性較高的一種,目前還存在其他一些量子計算機構建方法。
下面,我們來具體了解這塊五層“大蛋糕”。首先從最頂層起步,民就是硬件內部結構中位置最高的抽象層。
最重要的部分自然是頂部的應用層,它并不是量子計算機的物理組成部分,但在整個系統中扮演著核心角色。它代表著組成相關算法所需要的全部要素:編程環境、量子計算機操作系統、用戶界面等等。由這一層構成的算法可以是純量子形式,也可以是經典計算加量子計算的混合體。應用層應該獨立于其下各層中使用的硬件類型之外。
Cake分層大蛋糕: 實用型量子計算機的全部組件可以分為五個部分,每一部分負責執行不同類型的處理任務。
應用層下方的是經典處理層,其具備三項基本功能。首先,它負責優化當前運行中的量子算法,將算法編譯為微指令。整個過程與傳統計算機中的CPU執行方式類似,CPU需要將每條待執行的機器代碼指令編譯為多條微指令。另外,該層還將處理以下各層內硬件返回的量子態測量結果,將這些結果反饋至經典算法中以產生最終結果。最后,經典處理層還負責為以下各層提供必要的校準與調整。
經典層下方為數字、模擬與量子處理層,它們共同構成一個量子處理單元(QPU)。QPU 這三層之間緊密相連,每層的具體設計都在很大程度上取決于另外兩層。接下來,我將更全面地自上而下描述構成QPU的這三個層。
數字處理層負責將微指令轉換為脈沖,即操作量子比特所需要的信號類型,進而將量子比特轉換為量子邏輯門。更準確地說,此層提供了模擬脈沖所對應的數字定義。模擬脈沖本身在QPU的模擬處理層內生成。數字層還負責將量子計算的測量結果反饋至上方的經典處理層,確保后者將量子解與經典計算結果整合起來。
目前,個人計算機或現場可編輯門陣列已經足以應對這些任務。但在對量子計算機進行量子糾錯時,數字處理層會變得更加復雜。
接下來是模擬處理層,負責創建發送至量子比特的各種信號。這些信號主要表現為電壓階躍、微波脈沖的掃描與猝發等,其經過調相與調幅以保證正確執行必要的量子比特操作。這些操作直接指向相互連接為量子邏輯門的量子比特,而量子邏輯門又將進一步相互協同,根據當前運行的特定量子算法執行整體計算。
雖然從技術角度看,生成這樣的信號并不是非常困難,但在管理量子計算機內的實際信號時,我們仍要面對不少障礙。一方面,發送至不同量子比特的信號需要在皮秒級時間尺度上保持同步。我們必須以某種方式將這些不同信號傳遞至對應的不同量子比特,確保它們正確執行不同操作。這事聽著困難,做起來更困難。
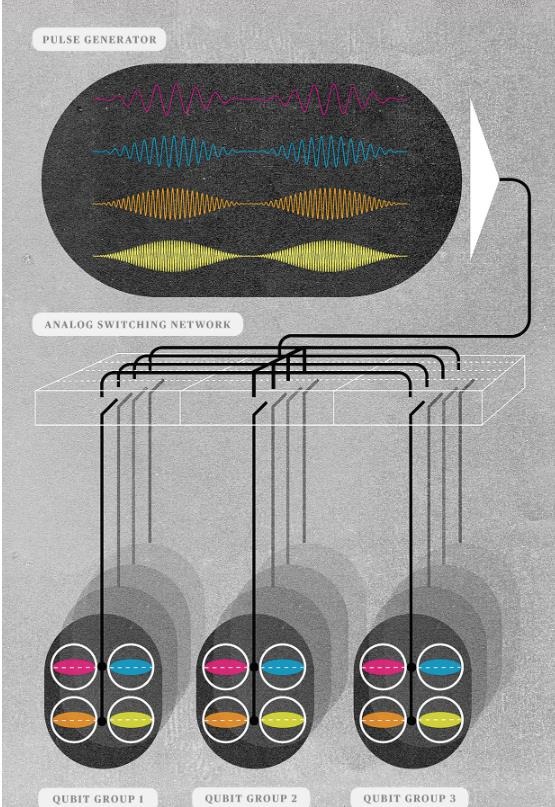
分而治之: 在實用型量子計算機中,由于量子比特太多,我們無法獨立將信號線附加至每個量子比特上。相反,我們只能使用空間與頻率的復用組合。量子比特將被成組制造出來,并附加至同一條公共信號線上,其中每個量子比特被調整為僅響應一種信號頻率(圖中顯示為不同顏色)。以此為基礎,計算機即可生成特定頻率的脈沖并通過模擬交換網絡將脈沖僅發送至特定量子比特組,從而操縱量子比特中的目標子集。
在目前只包含幾十個量子比特的小型系統當中,每個量子比特都被調諧至不同頻率——大家可以將其理解為鎖定在某一頻道上的無線電接收機。我們在公共信號線上通過特殊頻率選定要建起的量子比特。雖然可行,但這種方式擴展性較差。可以想見,發送至量子比特的信號必須具備合理的帶寬,例如10兆赫。如果計算機內包含100萬個量子比特,那么這樣的信號系統將需要10太赫的帶寬,這顯然不可能實現。此外,我們也不可能建立100萬條單獨的信號線,用來直接將每信信號單獨發送至每一個量子比特。
可行的解決方案,可能需要將頻率與空間整理成復用組合。量子比特將被成組制造出來,各個組全部接入模擬通信網絡,該網絡負責將模擬層中生成的信號單純接入選定的組子集處。只要正確安排信號頻率與網絡連接,我們就能夠操縱單一或者一組目標量子比特,同時保證不影響其他量子比特。
雖然在理論上可行,但這種多路復用結構也有其代價:控制精度不足。如何解決這種精度不足問題,目前仍有待商榷。
在現有系統中,數字與模擬處理層主要運行在室溫環境下。但下方的量子處理層(保存量子比特的層)則需要運行在絕對零度條件當中。不過隨著未來系統中量子比特數量的持續增長,構建這三個層的電子設備必須集成到同一塊經過封裝的低溫芯片內。
部分企業目前正著手構建基于超導量子比特的所謂預原型系統。這類設備最多包含幾十個量子比特,能夠執行數十至數百項相干量子操作。遵循這一思路的企業包括科技巨頭谷歌、IBM以及英特爾。通過擴展控制線的數量,工程師們能夠將現有架構擴展至數百量子比特,但也就僅此而已。量子比特之間保持相干性的時間很短(目前大約為50微秒),系統必須在退相干發生之前盡可能多地執行量子指令。
考慮到這些限制,預計未來一段時間,這類包含數百個量子比特的系統將主要作為常規超級計算機的加速器方案。量子計算機在處理特定任務時速度更快,能夠將結果返回給超級計算機以供進一步處理。從某種意義上講,這樣的量子計算機類似于筆記本電腦中的GPU,專門用于完成矩陣求逆或者初始條件優化等CPU不太適合處理的任務。
在量子計算機的下一發展階段,應用層的構建將越來越輕松。數字處理層同樣相對簡單。但是,構建QPU的三個層才是真正的核心難題,現有制造技術也無法產生完全一致的量子比特。因此,不同的量子比特之間必然存在略有差異的屬性。這種異質性又要求QPU中的模塊層做出針對性的適應。這就帶來了定制化需求,并導致構建QPU的流程難以大規模擴展。要想開發出規模更大的量子比特系統,首先需要消除模擬層的定制化需求,同時找到可行的控制信號與測量信號多路復用方法。
要在未來五到十年內顯著提升量子比特數量,研究人員必須首先找到成熟的多路復用方案,確保他們能夠在設備上提升糾錯功能。這種糾錯功能的基本思路很簡單:不再將數據保存在單一物理量子比特中,而是將多個物理量子比特組合為同一個經過糾錯的邏輯量子比特。
量子糾錯能夠從根本上解決退相干難題,但每個邏輯量子比特可能需要100到10000上物理量子比特。這還不是唯一的障礙——實現糾錯還需要一套低延遲、高吞吐量的反饋環路,且跨越QPU中的全部三個層。
目前正處于試驗階段的量子比特分為多種類型,包括超導電路、自旋量子比特、光子系統、離子阱、氮空位中心等等,我們還不清楚哪一種最適合用于創建大規模量子比特系統。無論哪種方法最有效,可以肯定的是要打造出通用型量子計算機,我們至少需要能夠封裝并控制數百萬個量子比特(甚至更多)。
這就引出了新的疑問:這一切真能實現嗎?數百萬個量子比特必須由連續的模擬信號精準控制。很難,但并非完全不可能。我和其他研究人員經過計算后發現,如果能夠將設備質量提升幾個數量級,即可實現對糾錯控制信號的多路復用,模擬層的設計將因此變得簡單明了,數字層則可直接管理這套多路復用方案。以此為基礎,未來的QPU將不再需要數以百萬計的數字連接——只需要數千甚至數百條即可,現有IC設計與制造工藝已經完全能夠實現。
更大的挑戰可能來自測量方面:在量子計算機上,芯片每秒需要執行數千次測量。這些測量操作在設計上不應干擾量子信息(直到計算結束,這些信息才會真正呈現),同時能夠發現并糾正期間出現的任何誤差。要以這樣的頻率測量數百萬個量子比特,無疑要求我們徹底升級現有測量原理。
現有量子比特的測量方法需要對模擬信號進行解調與數字化。在數千赫茲的測量速率下,如果一臺計算機內包含數百萬個量子比特,那么總數字吞吐量將高達每秒數PB。要求將室溫電子設備接入絕對零度環境下量子芯片的現有技術,根本無法應對如此恐怖的數據量。
很明顯,QPU的模擬層與數字層必須和同一芯片上的量子處理層集成起來,并引入某種精巧的設計方案以實現測量預處理以及多路復用。幸運的是,單純的糾錯操作并不需要將所有量子比特的測量結果上傳至數字層。只有在本地電路檢測到錯誤時,才需要實際執行上傳,這將大大減少所需的數字傳輸帶寬。
量子層的具體設計,將從根本上決定計算機的運行狀況。量子比特中如果存在缺陷,則意味著我們必須引入更多缺陷以執行糾錯。隨著缺陷的愈發嚴重,量子計算機本身終將無法正常運轉。但反之亦然:量子比特質量的提升雖然成本不菲,但卻能給工程師們留下更多發揮空間,并最終打開指向通用型量子計算機的大門。
不過在目前的量子計算原型開發階段,我們仍然不得不對各個量子比特進行單獨控制,從而充分利用少得可憐的現有量子比特。不過隨著可用量子比特數量的增長,研究人員們很快就得設計出用于實現控制信號復用與量子比特測量的新系統。
接下來的另一項重要工作,是引入某種基礎性糾錯形式。初步來看,將存在兩條并行的開發路徑——一條具備糾錯功能,一條沒有糾錯功能。但幾乎可以肯定,具備糾錯功能的量子計算機終將占據主導地位,而沒有糾錯功能的方案將無法執行任何具有現實意義的任務。
為了做好準備,芯片設計師、芯片制程工程師、低溫控制專家、海量數據處理專家、量子算法開發人員以及其他相關人士必須開展緊密合作。
如此復雜的合作,恐怕只能在國際量子工程路線圖的指引下才有可能實現。以此為基礎,各項任務將被有序分配給不同的專家小組,路線圖的發布方則負責管理各組間的往來溝通。將學術機構、研究機構以及商業企業的力量集中起來,我們有望成功構建起具備實用性的量子計算機,并真正開啟量子計算的新時代。

















