【大咖來了 第12期】AI和大數據系統在電子競技數據處理平臺中的應用
原創【51CTO.com原創稿件】電子競技作為近年來競技體育項目中發展最迅猛的一個獨特分支,正在引起大量的社會關注和重視。和其他競技體育項目一樣,電子競技對于數據的分析和應用有著獨特的要求。電子競技項目中,由于職業玩家和業余玩家的距離更近、業余玩家對于項目的參與度更高,使得其比賽數據的體量和數據分析的技術要求較之傳統體育有著幾何級數的增長。
本期《大咖·來了》欄目邀請了VPGame CTO 俞圓圓(Y3),進行了主題為《從游戲到科學:AI和電子競技》的分享,圍繞如何利用前沿技術對海量電競數據進行處理、存儲與分析展開。
FunData大數據系統
電競數據的量級遠遠大于傳統競技體育,所以VPGame是采用什么技術框架進行處理的呢?下面介紹一下FunData大數據系統以及其ETL層、接口層、數據處理層等部分的具體細節。如下圖,為通用FunData大數據系統架構
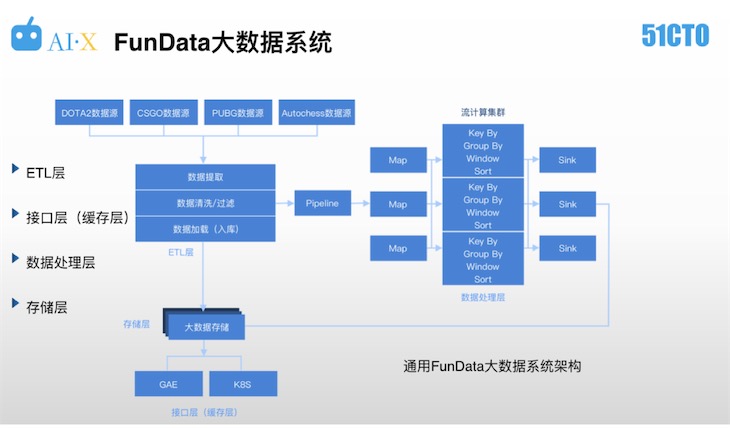
FunData大數據系統分為四層:ETL層的作用是數據提取、清洗過濾和加載,接口層的作用是為前端產品應用提供服務,數據處理層的作用是運用流計算、批計算等方式、對原始數據進行提取,最終得到可用性較高的總結性、概覽性數據,存儲層作用是對數據進行分級,選取不同的技術方案進行存儲。
FunData大數據系統之ETL范式
如下圖,為FunData ETL整體范式。
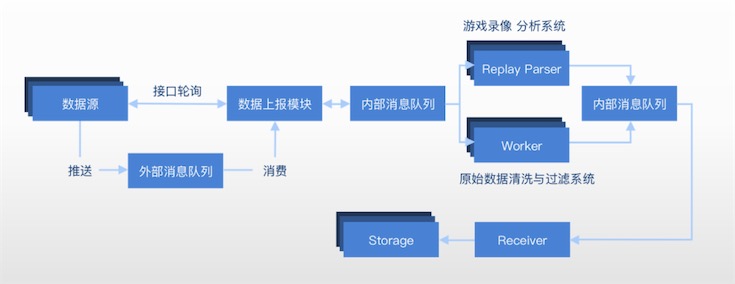
從廠商數據接口、直播視頻或錄像文件等渠道獲取到的數據源,通過外部消息隊列推送到據上報模塊,由內部消息列隊通知不同的數據清洗和分析系統,將原始數據進行分門別類的歸檔和存儲,再次通過內部消息隊列一步步將這些數據加載或存入到不同的底層存儲服務中。
FunData大數據系統之接口層
如下圖,為基于Kubernetes的彈性API系統架構。
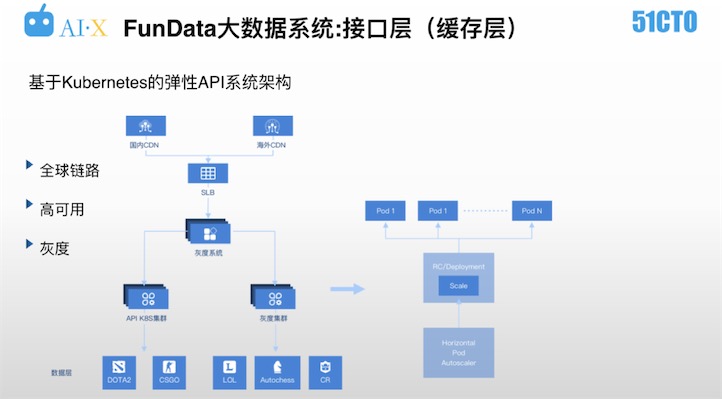
數據要如何運用呢?不管是服務于VPGame應用,還是第三方應用,都是通過基于Kubernetes搭建的API集群實現的。API系統架構不是一成不變的,當不斷深入或拓展到其他游戲IP時,會同步進行很多優化,同一個游戲在不同階段會提供豐富度不同的API,當然整個擴容的過程一定是平滑的。API系統架構一定要具備彈性擴容能力,以便可以很好的應對比賽過程中出現的API請求激增的情況。
FunData大數據系統之數據處理層
數據處理層的挑戰在于不同游戲,甚至同一個游戲的不同場景,數據邏輯都是不一樣的,所以如果是采用基于虛擬機的單體程序設計的話,對于彈性流量的適應會存在很大困難。如下圖,為數據處理層的工作邏輯。
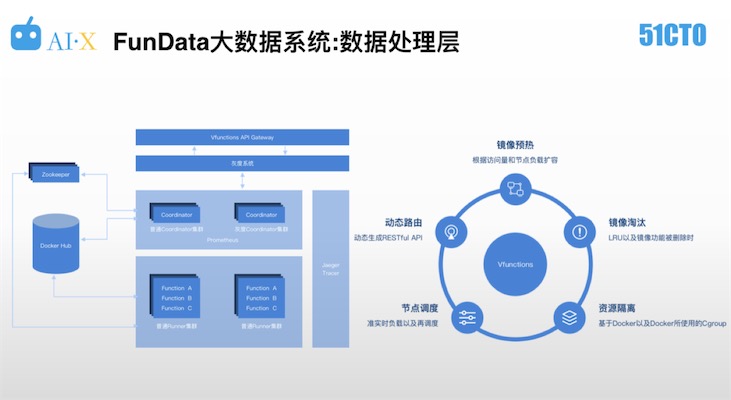
VPGame的數據處理邏輯構建基于Serverless的彈性框架,對實時激增的數據進行處理和計算。于整個框架而言,對業務方的要求僅僅是編寫好業務邏輯即可,不必操心容量規劃方面的問題。
如下為VM系統與Serverless架構對比圖。

VM系統與Serverless架構存在明顯差異,主要體現在資源利用率、資源的虛擬化和計算能力等方面。對于VM系統,當訪問量增加時需要聯系運維新增機器,恢復正常訪問量再聯系運維減少機器。對于Serverless架構,可以依據實際請求量和機器狀況動態分布,統一由Vfunctions管理,不需要運維和業務方的介入。還有就是隨時間推移,游戲數據量會存在突刺,熱門時間(大賽/節假日)比賽數量激增的情況,原來基于VM的方式處理數據會導致大量數據處理任務堆積,系統壓力飆升,部分處理任務超時,不得不人工接入進行擴容。改為Serverless架構,收到新的數據后,由Serverless調度器隨機分配一個Worker啟動對應的算法容器進行數據處理與提取。
數據處理層還要面對的問題是,不同維度和層面的數據,對于實時性的要求不同,對于資源和時間的計算、處理,其要求也是不同的。這里就需要把處理模塊大致分為Hadoop (數據批處理)和Flink (數據流處理)。
批處理的數據一般是全局性的統計數據,如這場比賽出現多少英雄,他們的裝備、技能選擇等數據,這些數據相對深入,訪問頻次相對較低,故對及時性的相對要求也不高。但像單局比賽的基礎數據,就屬于熱點數據,需要比賽結束后第一時間進行處理,這里就需要采用流處理框架,保障收到數據后,秒級產出數據結果。以DOTA2單局比賽個人數據處理為例,詳見下圖。
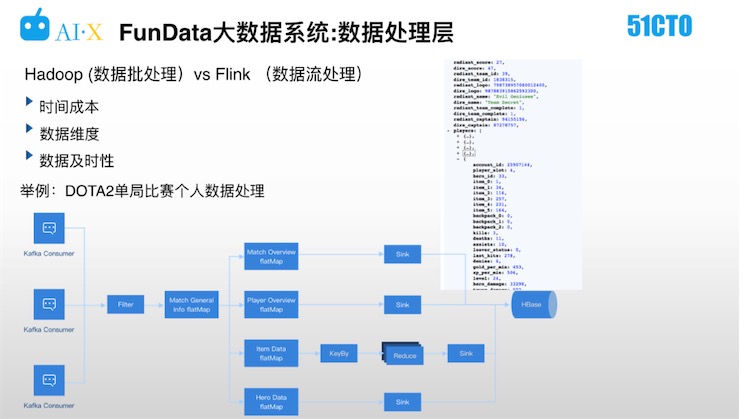
通過消息隊列進來的數據信號會知道這些ID有新的比賽產生,接著Filter會把無效的比賽ID過濾掉之后,進一步對數據結構做部分轉化,清理不需要的字段,將這些處理流寫入不同維度的算子,最后用Reduce算子做一些聚合。
綜上所述關于大數據系統的內容為本次分享的第一部分,后面還有對FunData海量存儲和基于OCR與機器學習的數據識別和挖掘兩部分精彩內容,請戳視頻:http://aix.51cto.com/activity/10021.html
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】