【大咖來了 第4期】數據驅動的產品決策和智能化
數據與產品的結合
話題一是數據與產品的結合,以 Stitch Fix 作為例子,闡述數據科學是如何滲透到產品的不同環節的。
Stitch Fix 是一家數據驅動的服裝新零售的電商公司,致力幫助用戶發現適合他自己的風格款式,主要服務于沒時間逛街、對穿搭不在行、想追逐時尚等特征的用戶群體。
Stitch Fix 所有的銷售都來源于推薦,推薦采用的是盲盒模式,用戶在收到商品之前是沒有預覽過的,這樣就意味著需要猜用戶會喜歡哪些衣服。如果一旦猜錯,消耗的將是造型師服務和雙向物流的這些真金白銀的成本,所以對準確度的要求非常之高。
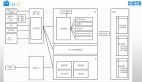
如下圖,從普通的用戶角度看,使用Stitch Fix 主要分為三步驟。
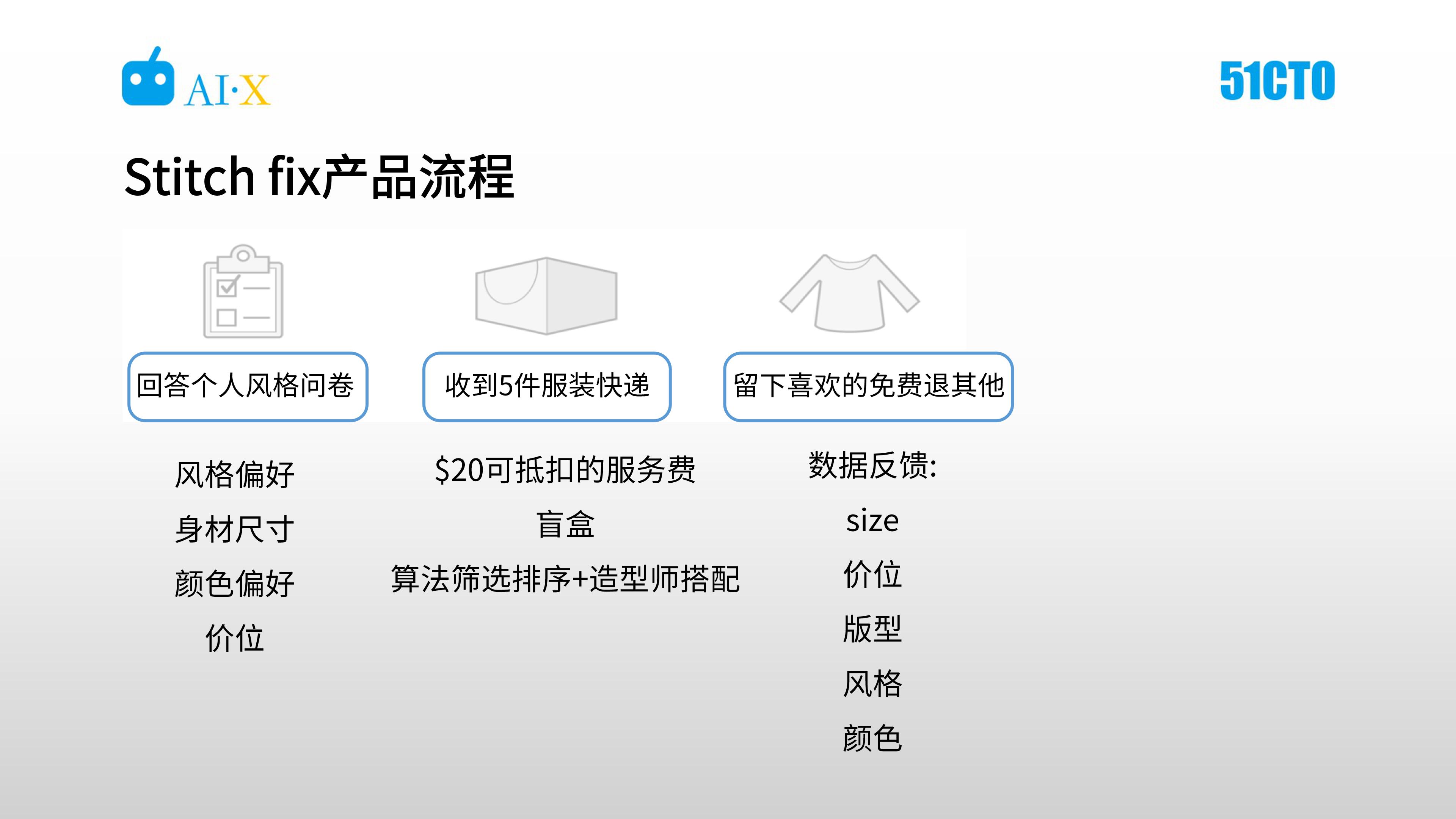
Set.1是回答個人的風格問卷,之后會收到搭配好的五件衣服,試穿后留下喜歡的,免費退回其他不喜歡的。
Stitch Fix 鼓勵用戶對每一件衣服從尺寸、價位、版型、風格和顏色等維度進行反饋,這些數據將助力數據科學團隊更好的了解用戶與服裝的匹配情況。
數據科學團隊人員占員工總數的 1/4,同時也意味著數據科學滲透到產品的很多環節,發揮著應有的價值,例如倉庫分配、用戶與造型師匹配、用戶畫像、人貨匹配、庫存管理等環節。
例一:倉庫分配
當有用戶請求發出,需要決定從哪一個倉庫為用戶發貨。選倉發貨需要綜合考慮多個因素,包括運費,投運時間,倉庫風格和用戶風格匹配情況等,基于這些因素建立倉庫和用戶之間的匹配度指標。
例二:用戶和造型師的匹配
當用戶發出請求,依據用戶和造型師之間的交易歷史,用戶打分、以及資料匹配進行造型師匹配。
例三:用戶畫像
在 Stitch Fix 用戶畫像既服務于算法,也服務于造型師,故需要一些可解釋、可以為人讀懂的用戶畫像。

用戶畫像大部分來源于用戶填寫的個人問卷,其中包括基礎的緯度畫像,以及跟穿搭相關,如說用戶的身材尺寸、顏色、價格偏好等。
在處理用戶風格上,把穿搭的風格分成七個緯度:經典、浪漫、波希米亞風等,每個用戶在每個緯度上有 1 到 4 的打分,基于用戶打分可以大概看出來用戶的穿搭風格。
例四:人貨匹配
這里主要分享數據和模型兩個層面,數據層面有:用戶畫像、商品 ID、商品泛化特征(圖像、標簽),以及多維度的反饋。推薦算法的數據存在挑戰,如 item 的樣本不均衡、數據回流帶來的誤差、特征和反饋數據缺失、折扣帶來的偏差等。模型層面(2016 年)有混合效應模型、Factorization machine、DNN、word2vec,、LDA 等。
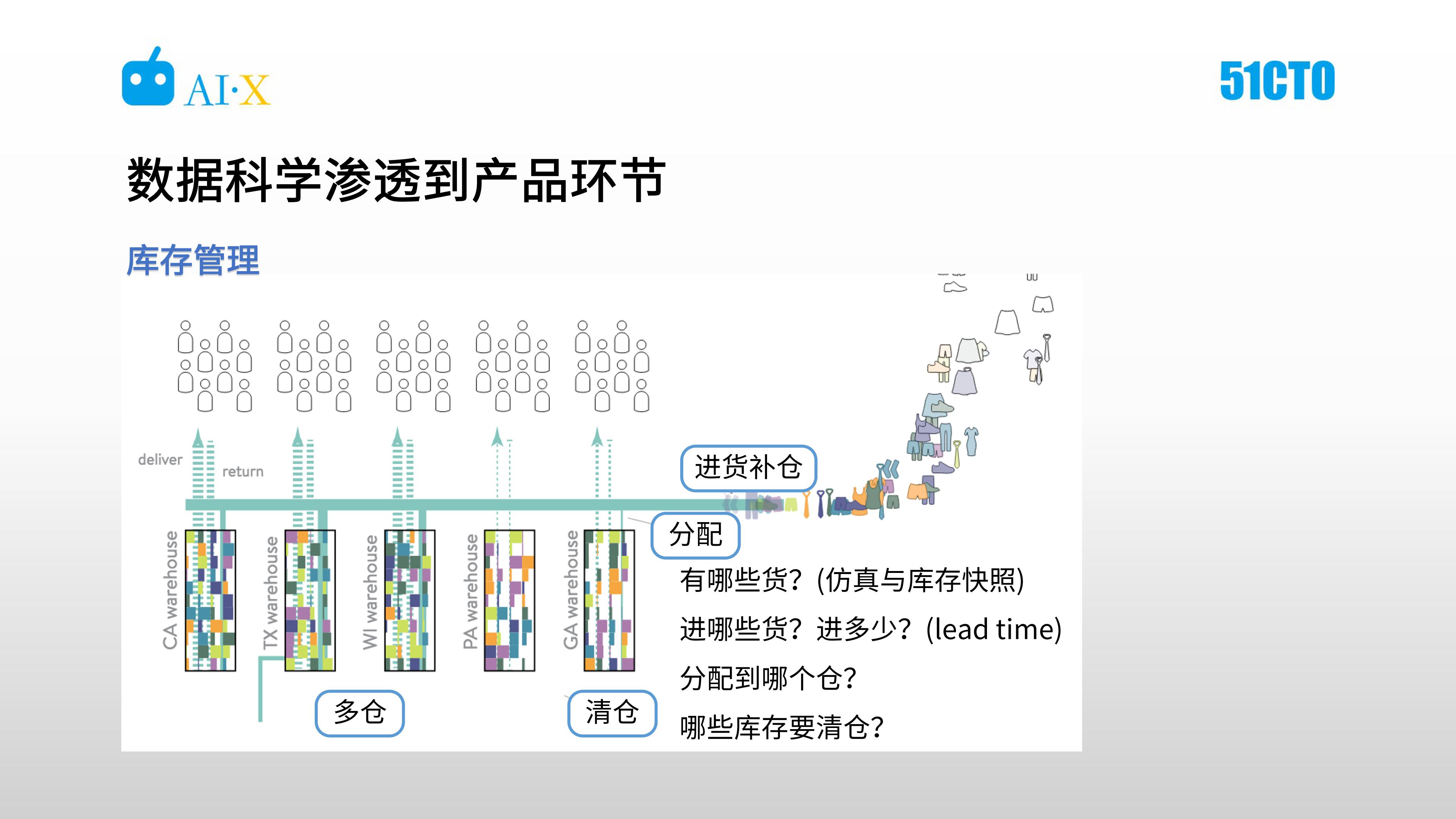
例五:庫存管理
在庫存管理上,需要解決的問題有很多,如有哪些貨、要進哪些貨、進多少、分配到哪個倉、及哪些庫存需要清倉等。有哪些貨看似是一個簡單的問題,但在 Stitch Fix 比較特殊,因為庫存商品其實僅占所有商品的 40%,有大量的商品存在用戶寄回到倉庫的路上,或是從倉庫寄到用戶的路上,這里就需要做仿真與庫存快照來應對。
透過上述這些產品的環節發現可以用數據提升效率的機會,定義并解決問題,那么是通過哪些技術實現的呢?這里主要分享普遍關心的三大問題,度量指標的選擇及分析,AB 測試和用戶畫像。
度量指標的選擇及分析

在 Stitch Fix 專注轉化率、GMV、留存這三大核心指標,對于選擇度量指標可參考三點:數據源的可靠性、指標與結果的相關度以及信號質量和敏感度。
Stitch Fix 常用分析主要有漏斗、群組、多緯等,如下圖以群組分析示例。

如可以把用戶按照獲客時間、首單時間分成等標簽并分成群組,然后觀測在一定時間范圍內某些指標的變動,對于時間的跨度可以選擇相對比較短的,也可以選擇相對比較長的。
如下圖,為不同的獲客時間的用戶留存對比。
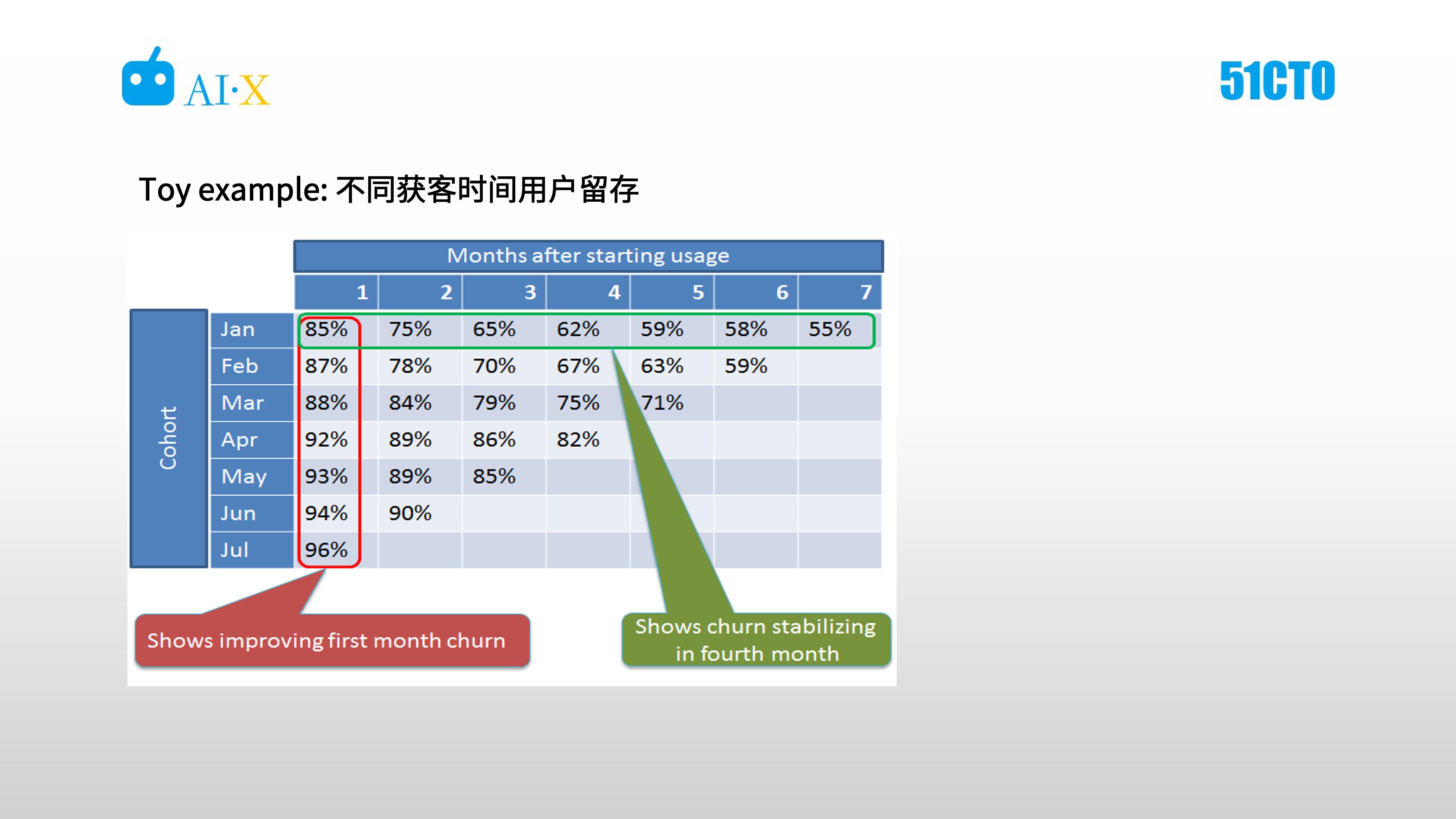
綜合看,從 1 月到 7 月,首月的留存在提升,這意味著在渠道獲取上,獲取的用戶質量有待提升。另外也可以看到隨著時間的推移,用戶留存會有一個平臺效應,頭四個月,月到月的用戶流失是比較顯著的,后續的用戶留存趨于穩態。
AB 測試
在 Stitch Fix,AB 測試主要面臨兩個挑戰,分別是線下交易帶來的延時和造型師人為因素。
當線上算法發生改變時,需要造型師針對每一個用戶做出匹配,再加上物流,會產生七到十天的延時。
造型師的人為因素主要是由于造型師的慣性帶來的,舉一個比較極端的例子,如果算法想重推高單價產品,但造型師卻希望給用戶推薦一些價格適中的商品,這樣就會對結果產生影響。
這里需要提醒的是 AB 測試需謹慎,如下四點要注意:
實驗正交設計:實驗 1: uid 尾號為奇數 vs 偶數 實驗 2: uid 尾號 (0,1) vs 2
用戶適應曲線
小流量實驗與全流量上線的區別
實驗效果疊加:季度上線了 6 個+1% 的實驗,但整體提升只有 3%
用戶畫像
用戶畫像是在公司范圍內基礎數據的搭建,也就是大家現在經常提到的數據中臺,畫像對于推薦業務、用戶運營、渠道畫像都會有相當的指導意義。
這就意味著畫像在公司是需要多部門協作的事情,也會因為多部門協作帶來挑戰,主要體現在數和應用脫節、多業務需求近似兩種情況。實際在生成畫像時需要三步走,依次是收集畫像需求、構建標簽框架和填充數據。
在實用過程中,如果希望破局,有下面三個建議:
放棄大而全的框架,業務場景倒推 (價值)
自動化生成標簽 (手段):規則或算法
有效的標簽管理機制 (可持續性)
數據與人的結合
第二個話題是數據與人的結合,在 Stitch Fix 是通過算法和造型師結合起來幫用戶做推薦搭配,可以認為這是一個人機耦合的系統,那么,人機耦合系統會有哪些挑戰呢?

在算法方面,Set.1要對大量的庫存進行 SKU 篩選和排序,第二分從大規模數據中找到規律。第三是降噪,因為造型師會存在相當大的個體差異,需要制定一個相對一致的標準,使得最終篩選的結果不會產生很大的偏差。
在人機耦合的系統,造型師承擔人的角色,對非結構化數據進行處理,進行 1v1 情感溝通、還具有創造性,這樣算法開發時候就可以免于考慮邊緣情況。
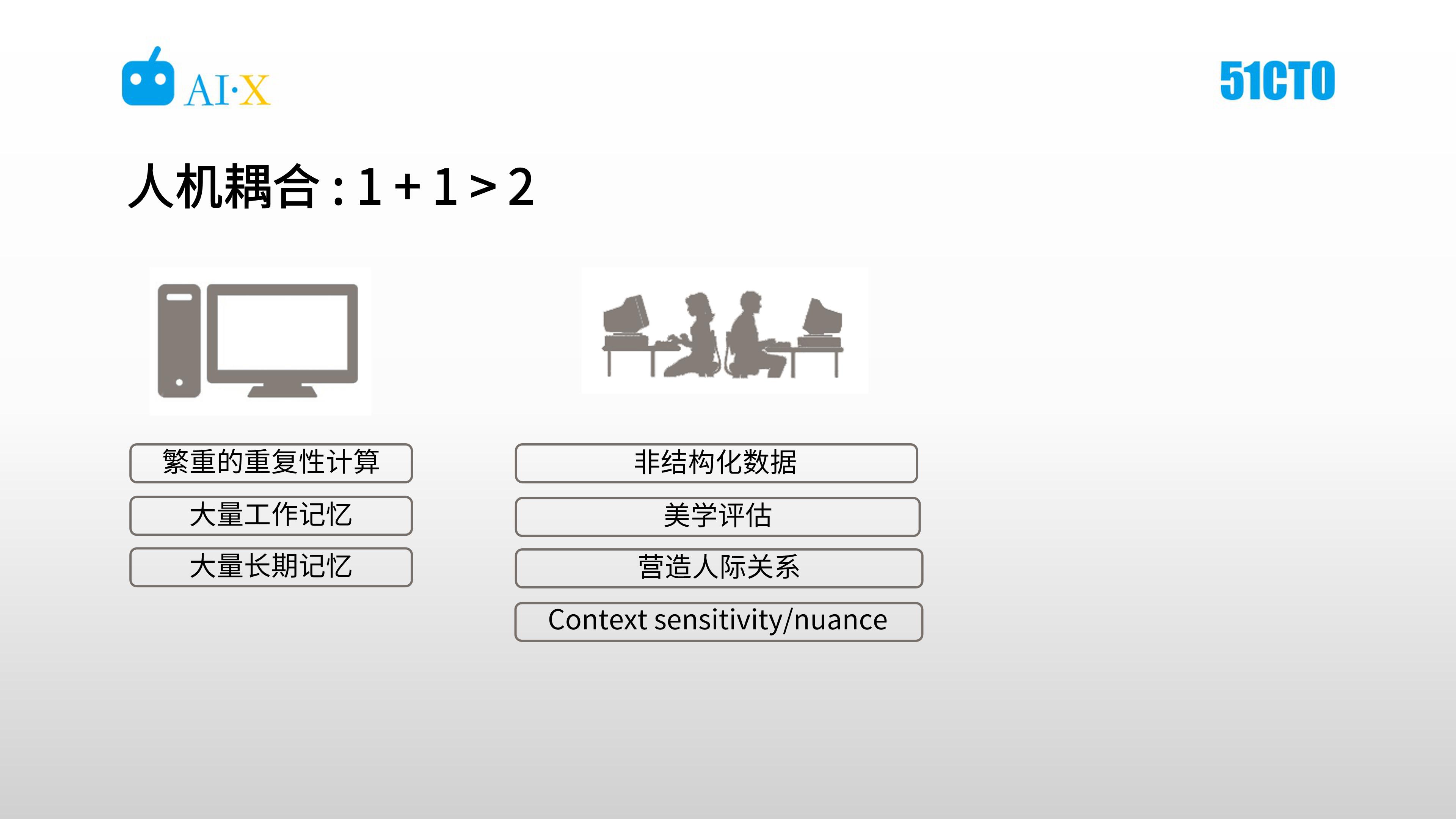
這種人機協同的方式,不是純粹靠機器算法,也不是純粹靠人工。機器可以承擔更多的繁重的重復性的勞動工作,還擁有大量的工作記憶、長期記憶,而人可以更好的處理非結構化數據,可以進行美學評估,也可以跟客戶建立良好的人機關系。
另外人對場景也會有比較強的敏感度,比如說秋天到了,在中西部的人適合穿什么樣的衣服,造型師對這個會有比較強的敏感度,進而做比較好的推薦。
在人機耦合中,雖然 1+1 是大于 2 的,但人機耦合也面臨如下問題:
人會成為速度和規模的瓶頸:訂單分布跟造型師工作時間不匹配
衡量人和機器彼此的價值
對算法多反饋渠道:用戶反饋與造型師挑選
算法的優化目標要慎重選擇
數據與團隊的結合
第三部分是數據和團隊的結合,這部分主要介紹在整個數據團隊里,包括分析、算法、數據開發是如何結合在一起,及整個數據團隊在公司的架構體系下,又是如何和業務團隊結合起來協作的。

數據和團隊的結合,其實在聊大數據時,聊了很多方法論、思維框架,但最終實施起來,還是要靠數據團隊的人來實現以及給公司提供價值。
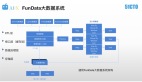
Stitch Fix 數據團隊主要分成四部分,底層數據開發團隊,可以搭建數據平臺、數據倉庫,數據科學家提升效率或者做部署工具。
上面三個團隊是跟業務一一對應的,客戶團隊、推薦團隊,還有庫存團隊。
數據團隊的搭建上,這里給出三個定位原則,供參考:
以業務與產品為核心。聚焦在產品和業務,使得數據產生實際價值
數據科學團隊要結合基礎設施部門與業務部門,尤其是業務跨度很大的公司
公司決策層的耐心支持,并與具體工程與產品團隊成為有機的一體, 目標對齊一致
在實際操作中,請注意還將面臨如下問題:
分析結果如何落地,如何做能夠落地的分析
分析處理數據需求與數據驅動業務,處理數據相當于是一個被動的事情,數據團隊經常會面臨要為業務部門拉數據的任務,但同時數據團隊也需要主動去驅動業務,可以認為是被動和主動之間如何做一個協調。
保障數據平臺穩定性的同時,數據平臺團隊也盡可能開發,盡可能幫數據科學家更好的做數據流程,部署代碼和線上化的工具。