大數(shù)據(jù)處理的關(guān)鍵技術(shù)及應(yīng)用
數(shù)據(jù)處理是對紛繁復(fù)雜的海量數(shù)據(jù)價值的提煉,而其中最有價值的地方在于預(yù)測性分析,即可以通過數(shù)據(jù)可視化、統(tǒng)計模式識別、數(shù)據(jù)描述等數(shù)據(jù)挖掘形式幫助數(shù)據(jù)科學(xué)家更好的理解數(shù)據(jù),根據(jù)數(shù)據(jù)挖掘的結(jié)果得出預(yù)測性決策。
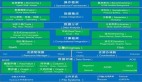
一、大數(shù)據(jù)采集技術(shù)
數(shù)據(jù)是指通過RFID射頻數(shù)據(jù)、傳感器數(shù)據(jù)、社交網(wǎng)絡(luò)交互數(shù)據(jù)及移動互聯(lián)網(wǎng)數(shù)據(jù)等方式獲得的各種類型的結(jié)構(gòu)化、半結(jié)構(gòu)化(或稱之為弱結(jié)構(gòu)化)及非結(jié)構(gòu)化的海量數(shù)據(jù),是大數(shù)據(jù)知識服務(wù)模型的根本。重點(diǎn)要突破分布式高速高可靠數(shù)據(jù)爬取或采集、高速數(shù)據(jù)全映像等大數(shù)據(jù)收集技術(shù);突破高速數(shù)據(jù)解析、轉(zhuǎn)換與裝載等大數(shù)據(jù)整合技術(shù);設(shè)計質(zhì)量評估模型,開發(fā)數(shù)據(jù)質(zhì)量技術(shù)。
大數(shù)據(jù)采集一般分為:
- 1)大數(shù)據(jù)智能感知層:主要包括數(shù)據(jù)傳感體系、網(wǎng)絡(luò)通信體系、傳感適配體系、智能識別體系及軟硬件資源接入系統(tǒng),實(shí)現(xiàn)對結(jié)構(gòu)化、半結(jié)構(gòu)化、非結(jié)構(gòu)化的海量數(shù)據(jù)的智能化識別、定位、跟蹤、接入、傳輸、信號轉(zhuǎn)換、監(jiān)控、初步處理和管理等。必須著重攻克針對大數(shù)據(jù)源的智能識別、感知、適配、傳輸、接入等技術(shù)。
- 2)基礎(chǔ)支撐層:提供大數(shù)據(jù)服務(wù)平臺所需的虛擬服務(wù)器,結(jié)構(gòu)化、半結(jié)構(gòu)化及非結(jié)構(gòu)化數(shù)據(jù)的數(shù)據(jù)庫及物聯(lián)網(wǎng)絡(luò)資源等基礎(chǔ)支撐環(huán)境。重點(diǎn)攻克分布式虛擬存儲技術(shù),大數(shù)據(jù)獲取、存儲、組織、分析和決策操作的可視化接口技術(shù),大數(shù)據(jù)的網(wǎng)絡(luò)傳輸與壓縮技術(shù),大數(shù)據(jù)隱私保護(hù)技術(shù)等。
二、大數(shù)據(jù)預(yù)處理技術(shù)
完成對已接收數(shù)據(jù)的辨析、抽取、清洗等操作。
- 1)抽取:因獲取的數(shù)據(jù)可能具有多種結(jié)構(gòu)和類型,數(shù)據(jù)抽取過程可以幫助我們將這些復(fù)雜的數(shù)據(jù)轉(zhuǎn)化為單一的或者便于處理的構(gòu)型,以達(dá)到快速分析處理的目的。
- 2)清洗:對于大數(shù)據(jù),并不全是有價值的,有些數(shù)據(jù)并不是我們所關(guān)心的內(nèi)容,而另一些數(shù)據(jù)則是完全錯誤的干擾項,因此要對數(shù)據(jù)通過過濾“去噪”從而提取出有效數(shù)據(jù)。
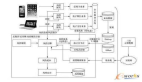
三、大數(shù)據(jù)存儲及管理技術(shù)
大數(shù)據(jù)存儲與管理要用存儲器把采集到的數(shù)據(jù)存儲起來,建立相應(yīng)的數(shù)據(jù)庫,并進(jìn)行管理和調(diào)用。重點(diǎn)解決復(fù)雜結(jié)構(gòu)化、半結(jié)構(gòu)化和非結(jié)構(gòu)化大數(shù)據(jù)管理與處理技術(shù)。主要解決大數(shù)據(jù)的可存儲、可表示、可處理、可靠性及有效傳輸?shù)葞讉€關(guān)鍵問題。開發(fā)可靠的分布式文件系統(tǒng)(DFS)、能效優(yōu)化的存儲、計算融入存儲、大數(shù)據(jù)的去冗余及高效低成本的大數(shù)據(jù)存儲技術(shù);突破分布式非關(guān)系型大數(shù)據(jù)管理與處理技術(shù),異構(gòu)數(shù)據(jù)的數(shù)據(jù)融合技術(shù),數(shù)據(jù)組織技術(shù),研究大數(shù)據(jù)建模技術(shù);突破大數(shù)據(jù)索引技術(shù);突破大數(shù)據(jù)移動、備份、復(fù)制等技術(shù);開發(fā)大數(shù)據(jù)可視化技術(shù)。
開發(fā)新型數(shù)據(jù)庫技術(shù),數(shù)據(jù)庫分為關(guān)系型數(shù)據(jù)庫、非關(guān)系型數(shù)據(jù)庫以及數(shù)據(jù)庫緩存系統(tǒng)。其中,非關(guān)系型數(shù)據(jù)庫主要指的是NoSQL數(shù)據(jù)庫,分為:鍵值數(shù)據(jù)庫、列存數(shù)據(jù)庫、圖存數(shù)據(jù)庫以及文檔數(shù)據(jù)庫等類型。關(guān)系型數(shù)據(jù)庫包含了傳統(tǒng)關(guān)系數(shù)據(jù)庫系統(tǒng)以及NewSQL數(shù)據(jù)庫。
開發(fā)大數(shù)據(jù)安全技術(shù):改進(jìn)數(shù)據(jù)銷毀、透明加解密、分布式訪問控制、數(shù)據(jù)審計等技術(shù);突破隱私保護(hù)和推理控制、數(shù)據(jù)真?zhèn)巫R別和取證、數(shù)據(jù)持有完整性驗證等技術(shù)。
四、大數(shù)據(jù)分析及挖掘技術(shù)
大數(shù)據(jù)分析技術(shù):改進(jìn)已有數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)技術(shù);開發(fā)數(shù)據(jù)網(wǎng)絡(luò)挖掘、特異群組挖掘、圖挖掘等新型數(shù)據(jù)挖掘技術(shù);突破基于對象的數(shù)據(jù)連接、相似性連接等大數(shù)據(jù)融合技術(shù);突破用戶興趣分析、網(wǎng)絡(luò)行為分析、情感語義分析等面向領(lǐng)域的大數(shù)據(jù)挖掘技術(shù)。
數(shù)據(jù)挖掘就是從大量的、不完全的、有噪聲的、模糊的、隨機(jī)的實(shí)際應(yīng)用數(shù)據(jù)中,提取隱含在其中的、人們事先不知道的、但又是潛在有用的信息和知識的過程。
數(shù)據(jù)挖掘涉及的技術(shù)方法很多,有多種分類法。根據(jù)挖掘任務(wù)可分為分類或預(yù)測模型發(fā)現(xiàn)、數(shù)據(jù)總結(jié)、聚類、關(guān)聯(lián)規(guī)則發(fā)現(xiàn)、序列模式發(fā)現(xiàn)、依賴關(guān)系或依賴模型發(fā)現(xiàn)、異常和趨勢發(fā)現(xiàn)等等;根據(jù)挖掘?qū)ο罂煞譃殛P(guān)系數(shù)據(jù)庫、面向?qū)ο髷?shù)據(jù)庫、空間數(shù)據(jù)庫、時態(tài)數(shù)據(jù)庫、文本數(shù)據(jù)源、多媒體數(shù)據(jù)庫、異質(zhì)數(shù)據(jù)庫、遺產(chǎn)數(shù)據(jù)庫以及環(huán)球網(wǎng)Web;根據(jù)挖掘方法分,可粗分為:機(jī)器學(xué)習(xí)方法、統(tǒng)計方法、神經(jīng)網(wǎng)絡(luò)方法和數(shù)據(jù)庫方法。
機(jī)器學(xué)習(xí)中,可細(xì)分為歸納學(xué)習(xí)方法(決策樹、規(guī)則歸納等)、基于范例學(xué)習(xí)、遺傳算法等。統(tǒng)計方法中,可細(xì)分為:回歸分析(多元回歸、自回歸等)、判別分析(貝葉斯判別、費(fèi)歇爾判別、非參數(shù)判別等)、聚類分析(系統(tǒng)聚類、動態(tài)聚類等)、探索性分析(主元分析法、相關(guān)分析法等)等。神經(jīng)網(wǎng)絡(luò)方法中,可細(xì)分為:前向神經(jīng)網(wǎng)絡(luò)(BP算法等)、自組織神經(jīng)網(wǎng)絡(luò)(自組織特征映射、競爭學(xué)習(xí)等)等。數(shù)據(jù)庫方法主要是多維數(shù)據(jù)分析或OLAP方法,另外還有面向?qū)傩缘臍w納方法。
數(shù)據(jù)挖掘主要過程是:根據(jù)分析挖掘目標(biāo),從數(shù)據(jù)庫中把數(shù)據(jù)提取出來,然后經(jīng)過ETL組織成適合分析挖掘算法使用寬表,然后利用數(shù)據(jù)挖掘軟件進(jìn)行挖掘。傳統(tǒng)的數(shù)據(jù)挖掘軟件,一般只能支持在單機(jī)上進(jìn)行小規(guī)模數(shù)據(jù)處理,受此限制傳統(tǒng)數(shù)據(jù)分析挖掘一般會采用抽樣方式來減少數(shù)據(jù)分析規(guī)模。
數(shù)據(jù)挖掘的計算復(fù)雜度和靈活度遠(yuǎn)遠(yuǎn)超過前兩類需求。一是由于數(shù)據(jù)挖掘問題開放性,導(dǎo)致數(shù)據(jù)挖掘會涉及大量衍生變量計算,衍生變量多變導(dǎo)致數(shù)據(jù)預(yù)處理計算復(fù)雜性;二是很多數(shù)據(jù)挖掘算法本身就比較復(fù)雜,計算量就很大,特別是大量機(jī)器學(xué)習(xí)算法,都是迭代計算,需要通過多次迭代來求***解,例如K-means聚類算法、PageRank算法等。