牛津中國小哥提出“3D-BoNet”,比3D點云實例分割算法快10倍!
本文提出了一種基于邊界框回歸的高效點云實例分割算法,通過最小化關聯代價函數來實現大致的邊界框回歸,并通過point mask預測來實現最終的實例分割。3D-BoNet不僅在ScanNet和S3DIS數據集上達到了state-of-the-art的效果,比當前大多數算法快了10倍以上。

Introduction
實現有效的三維場景理解(3D scene understanding)是計算機視覺和人工智能領域的關鍵問題之一。近年來,針對三維點云理解的研究取得了顯著的進展,在諸如點云目標檢測,語義分割等任務上都展現出了很不錯的效果。然而,針對于點云實例分割的研究還處于較為初級的階段。
Motivation
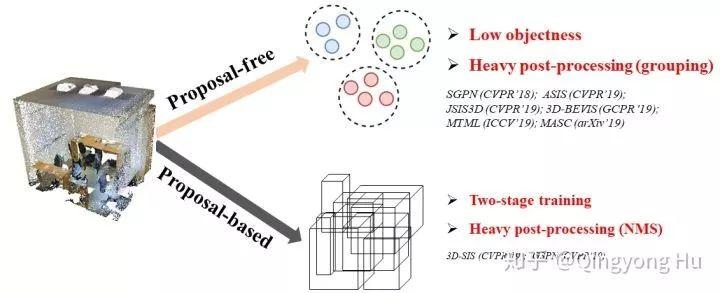
如下圖所示,當前主流的點云實例分割算法可以分為以下兩類:1)基于候選目標框(Proposal-based methods)的算法,例如3D-SIS[1],GSPN[2],這類方法通常依賴于兩階段的訓練(two-stage training)和昂貴的非極大值抑制(non-maximum suppression, NMS)等操作來對密集的proposal進行選擇。2)無候選目標框的算法(Proposal-free methods),例如SGPN[3], ASIS[4], JSIS3D[5], MASC[6], 3D-BEVIS[7]等。這類算法的核心思想是為每個點學習一個discriminative feature embedding,然后再通過諸如mean-shift等聚類(clustering)方法來將同一個instance的點聚集(group)到一起。這類方法的問題在于最終聚類到一起的instance目標性(objectness)比較差。此外,此類方法后處理步驟(post-processing)的時間成本通常較高。
圖1. 當前主流的點云實例分割算法對比
不同于上述兩類方法,我們提出了一個single stage, anchor free并且end-to-end的基于邊界框回歸的實例分割算法(3D-BoNet)。該算法具有如下優勢
- 相比于proposal-free的方法,3D-BoNet顯式地去預測目標的邊界框,因此最終學到的instance具有更好的目標性(high objectness).
- 相比于proposal-based的方法,3D-BoNet并不需要復雜耗時的region proposal network以及ROIAlign等操作,因此也不需要NMS等post-processing步驟。
- 3D-BoNet由非常高效的shared MLP組成,并且不需要諸如非極大值抑制,特征采樣(feature sampling),聚類(clustering)或者投票(voting)等后處理步驟,因此非常高效。
Overview
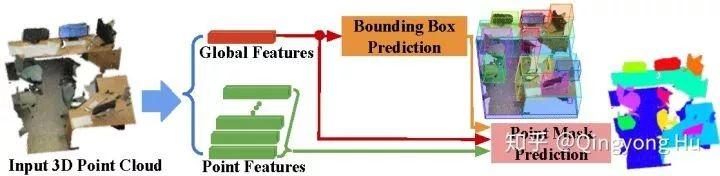
3D-BoNet的總體框架如下圖所示,它主要由Instance-level bounding box prediction和Point-level mask prediction兩個分支組成。顧名思義,bounding box prediction分支用于預測點云中每個實例的邊界框,mask prediction分支用于為邊界框內的點預測一個mask,進一步區分邊界框內的點是屬于instance還是背景。
圖2. 3D-BoNet的總體框架
看到這里,你可能會產生疑惑:這個看起來跟proposal-based的框架好像也沒什么區別?
先說結論:區別很大。但問題是區別到底在哪里呢?
首先,我們可以回顧下proposal-based方法是怎么產生邊界框的呢?沒錯,就是根據anchor用region proposal network (RPN)來產生大量密集的邊界框然后再進一步refine,但這個顯然不夠高效,而且是否真的有必要產生這么多密集的邊界框呢?針對這個問題,我們可以來一個大膽的假設:要不不用RPN,直接讓為每一個instance回歸(regress)一個唯一的,但可能不是那么準確的邊界框呢(如圖3所示)?
圖3. 為每一個instance回歸一個大致的邊界框示例
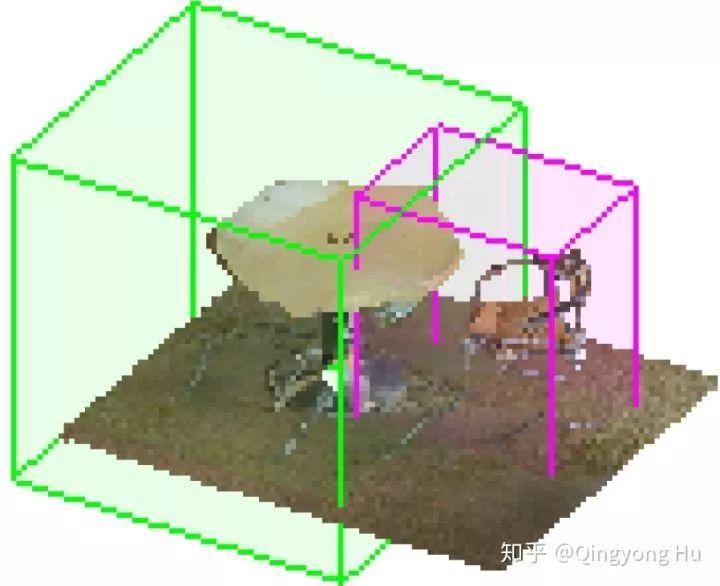
考慮到3D點云本身就顯式地包含了每個物體的幾何信息,我們認為這個目標是可行的。然后再更大膽一點,要不直接用global feature來regress每個instance的邊界框試試?如果能做到這點,那問題不就解決一半了嗎?
但新的問題馬上又來了。。首先,每個三維場景中所包含的實例數目是不一樣的(如何讓網絡自適應的輸出不同個數的邊界框?),而且每個點云中的實例還是無順序的。這就意味著我們即便用網絡regress了一系列邊界框,也難以將這些邊界框和ground truth的邊界框一一對應的聯系起來,進一步帶來的問題就是:我們無法實現對網絡的有監督的訓練和優化。
到這里,核心的問題就變成了:我們應該怎么去訓練這種網絡呢?
針對這個問題,我們提出了邊界框關聯層(bounding box association layer)以及multi-criteria loss 函數來實現對網絡的訓練。換句話說,我們要把這個預測邊界框和ground truth邊界框關聯(配對)的問題建模為一個最優分配問題。
圖4. 邊界框預測分支的結構圖

如何關聯?
為了將網絡預測出來的每一個邊界框與ground truth 中的邊界框唯一對應地關聯起來,我們將其建模為一個最優分配問題。假定 是一個二值(binary)關聯索引矩陣,當且僅當第 個預測的邊界框分配給ground truth的邊界框時。 是關聯代價矩陣, 代表將第 個預測的邊界框分配給ground truth的邊界框的關聯代價。一般來說,代表兩個邊界框的匹配程度,兩個邊界框越匹配也即代價越小。因此,邊界框的最優關聯問題也就轉變成為尋找總代價最小的最優分配索引矩陣 的問題,用公式表示如下:
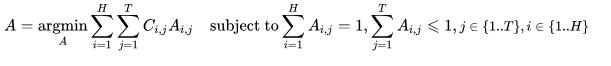
下一步,如何計算關聯代價矩陣?
衡量兩個三維邊界框的匹配程度,最簡單直觀的評價指標就是比較兩個邊界框的最小-最大頂點之間的歐式距離。然而,考慮到點云通常都非常稀疏且不均勻地分布在3D空間中,如圖4所示,盡管候選框#2(紅色)與候選框#1(黑色)與ground truth邊界框#0(藍色)都具有相同的歐式距離,但框#2顯然具有更多有效點(overlap更多)。因此,在計算代價矩陣時,有效點的覆蓋率也應該要考慮進來。
圖5. 預測邊界框與真實邊界框點云覆蓋率示意圖

為此,我們考慮以下三個方面的指標:
(1) 頂點之間的歐式距離。舉例來說,第個預測的邊界框 分配給ground truth的邊界框 的代價為:
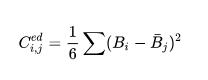
(2) Soft IoU。給定輸入點云 以及第 ground truth的實例邊界框 ,我們可以直接得到一個hard的二值(binary)矢量 來表征每個點是否在邊界框內。然而,對于相同輸入點云的第 預測框,直接獲得類似的hard的二值矢量將導致框架不可微(non-differentiable)。因此,我們引入了一個可微但簡單的算法來獲得類似但soft的二值矢量,稱為point-in-pred-box-probability,詳情見paper Algorithm 1。 所有值都在 范圍內,這個值越高代表點在框內可能性越大,值越小則對應點可能離框越遠。因此,我們定義第個預測的邊界框以及第ground truth的邊界框的sIoU如下:
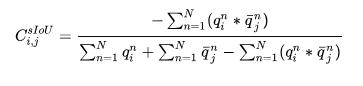
(3) 此外,我們還考慮了 和
和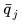 之間的交叉熵。交叉熵傾向于得到更大且具有更高覆蓋率的邊界框:
之間的交叉熵。交叉熵傾向于得到更大且具有更高覆蓋率的邊界框:
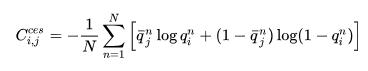
總結一下,指標(1)盡可能地使學到的框與ground truth的邊界框盡可能地重合,(2)(3)用于盡可能地覆蓋更多的點并克服如圖5所示的不均勻性。第 個預測的邊界框與第ground truth的邊界框的最終關聯代價為:
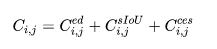
Loss function如何定義?
在通過邊界框關聯層之后,我們使用關聯索引矩陣 對預測邊界框 及其對應分數 與groundtruth進行匹配,使得靠前的 個邊界框(ground truth的總邊界框數)及與ground truth的邊界框能匹配上。
針對邊界框預測我們采用了多準則損失函數,也即三者求和:
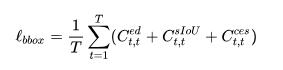
針對邊界框分數預測我們采用了另外一個損失函數。預測框分數旨在表征相應預測框的有效性。在通過關聯索引矩陣 重新排序以后,我們設定前 個真實的邊界框對應的分數為1,剩余的無效的 個邊界框對應的分數為 0。我們對這個二元分類任務使用交叉熵損失
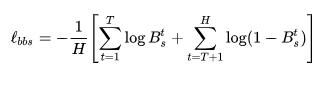
作為另外一個并行的分支,我們的方法可以采用任意現有的點云語義分割算法(比如Sparseconv, Pointnet++等等)作為對應的語義分割模塊,整個網絡最終的loss function定義為
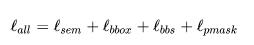
代表語義分割分支的loss,這里我們采用標準的交叉熵。網絡具體的優化和求解過程我們采用Hungarian算法,詳情請見[8],[9]。
如何預測instance mask?
相比于bounding box prediction分支,這個分支就相對簡單很多了,因為只要邊界框預測的足夠好,這個分支就相當于做一個二值分類問題,即便瞎猜也能有50%正確率。在這個分支中,我們將點的特征點與每個邊界框和分數融合在一起,隨后為每一個實例預測一個點級別的二值mask。考慮到背景點與實例點數的不平衡,我們采用focal loss[10] 對這個分支進行優化。
圖 6. Point mask prediction分支結構圖。

Experiments
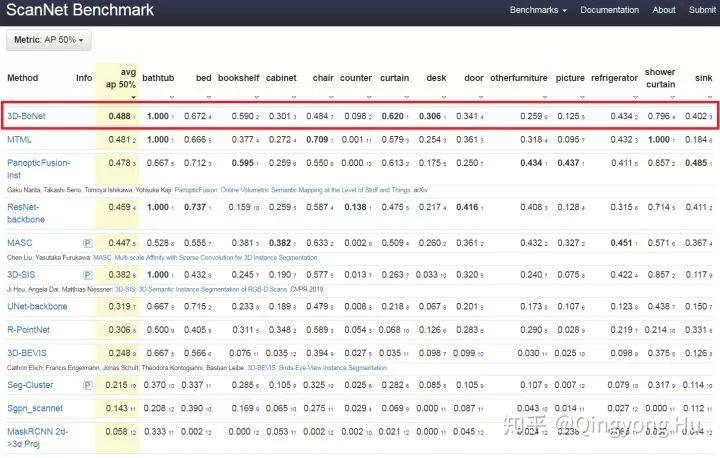
在ScanNet(v2) benchmark上,我們的方法達到了state-of-the-art的效果,相比于3D-SIS,MASC等方法都有顯著的提升。
圖7. 我們的方法在ScanNet(V2)的結果
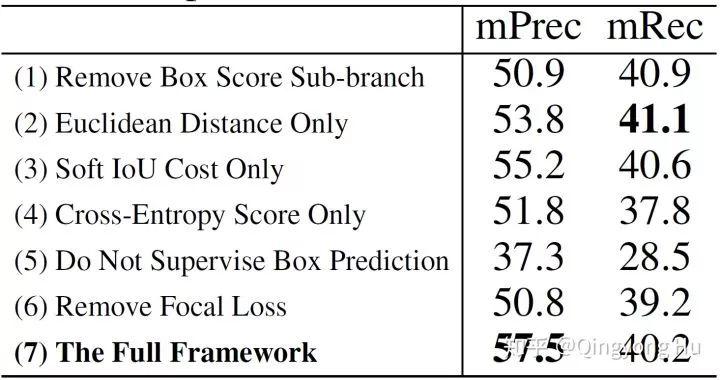
在Ablation study中,我們也進一步證實了各個分支以及loss function各個評估指標的作用。詳細的分析見paper。
圖 8. Ablation study結果 (S3DIS, Area5)
在計算效率方面,3D-BoNet是目前速度最快的方法,相比于SGPN, ASIS, 3D-SIS等方法,3D-BoNet快了十倍以上。
圖 9. 不同方法處理ScanNet validation set所需要的時間消耗。

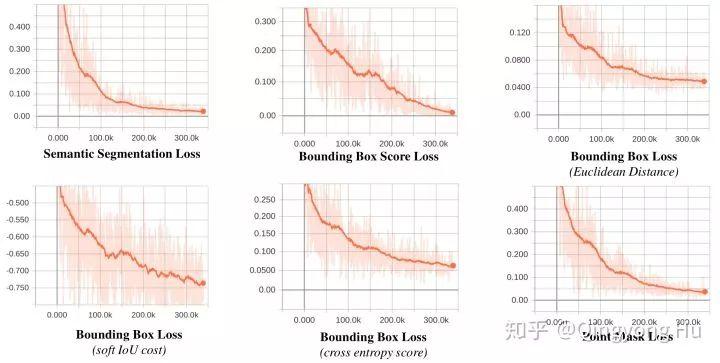
此外,我們還在圖10中進一步展示了我們提出的loss function在S3DIS數據集進行訓練時(Area1,2,3,4,6進行訓練,Area 5進行測試)的變化曲線。從圖中可以看到,我們提出的loss function能夠比較一致的收斂,從而實現對語義分割分支,邊界框預測分支以及point mask預測分支端到端方式的優化。
圖10. 我們的方法在S3DIS數據集上的training loss
在圖11中我們給出了預測邊界框和邊界框分數的可視化結果。可以看出,我們方法預測出來的框并不一定非常精準和緊湊。相反,它們相對比較松弛(inclusive)并且具有比較高的目標性(high objectness)。這也與本文一開始希望得到的大致邊界框的目標相一致。
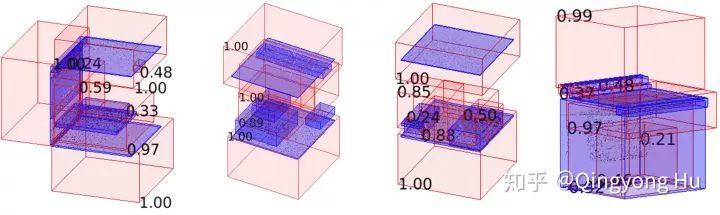
圖11. 我們的方法在S3DIS數據集Area 2上的預測邊界框和分數的可視化。紅色框表示預測的邊界框,藍色的邊界框代表ground truth。
當邊界框已經預測好以后,預測每個框內的point mask就容易很多了。最后我們可視化一下預測的instance mask,其中黑點代表屬于這個instance的概率接近為0,而帶顏色的點代表屬于這個instance的概率接近為1,顏色越深,概率越大。
圖12. 預測instance mask的可視化結果。輸入點云總共包含四個instance,也即兩個椅子,一個桌子以及地面。從左到右分別是椅子#1,椅子#2,桌子#1,地面#2的point mask.

最后總結一下,我們提出了一種基于邊界框回歸的高效點云實例分割算法,通過最小化匹配代價函數來實現大致的邊界框回歸,并通過point mask預測來實現最終的實例分割。我們提出的3D-BoNet不僅在ScanNet和S3DIS數據集上達到了state-of-the-art的效果,并且比現有其他算法更加高效。