架構(gòu)師詳解:從0到1構(gòu)建大數(shù)據(jù)平臺(tái)
如今大數(shù)據(jù)在各行業(yè)的應(yīng)用越來(lái)越廣泛:運(yùn)營(yíng)基于數(shù)據(jù)關(guān)注運(yùn)營(yíng)效果,產(chǎn)品基于數(shù)據(jù)分析關(guān)注轉(zhuǎn)化率情況,開(kāi)發(fā)基于數(shù)據(jù)衡量系統(tǒng)優(yōu)化效果等。
美圖公司有美拍、美圖秀秀、美顏相機(jī)等十幾個(gè) app,每個(gè) app 都會(huì)基于數(shù)據(jù)做個(gè)性化推薦、搜索、報(bào)表分析、反作弊、廣告等,整體對(duì)數(shù)據(jù)的業(yè)務(wù)需求比較多、應(yīng)用也比較廣泛。
因此美圖數(shù)據(jù)技術(shù)團(tuán)隊(duì)的業(yè)務(wù)背景主要體現(xiàn)在:業(yè)務(wù)線多以及應(yīng)用比較廣泛。這也是促使我們搭建數(shù)據(jù)平臺(tái)的一個(gè)最主要的原因,由業(yè)務(wù)驅(qū)動(dòng)。
美圖數(shù)據(jù)平臺(tái)整體架構(gòu)
如圖所示是我們數(shù)據(jù)平臺(tái)的整體架構(gòu)。在數(shù)據(jù)收集這部分,我們構(gòu)建一套采集服務(wù)端日志系統(tǒng) Arachnia,支持各 app 集成的客戶端 SDK,負(fù)責(zé)收集 app 客戶端數(shù)據(jù);同時(shí)也有基于 DataX 實(shí)現(xiàn)的數(shù)據(jù)集成(導(dǎo)入導(dǎo)出);Mor 爬蟲平臺(tái)支持可配置的爬取公網(wǎng)數(shù)據(jù)的任務(wù)開(kāi)發(fā)。
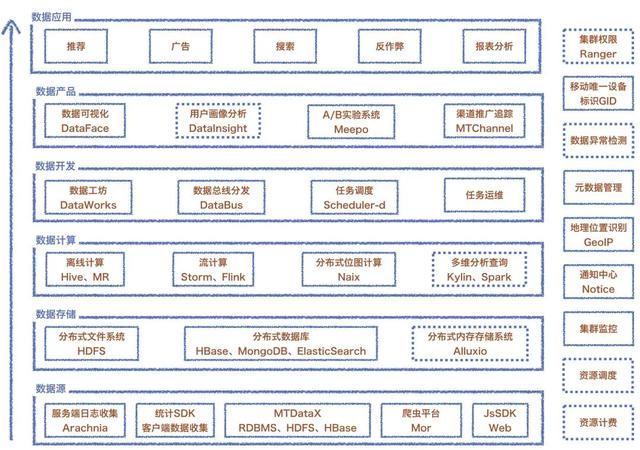
數(shù)據(jù)存儲(chǔ)層主要是根據(jù)業(yè)務(wù)特點(diǎn)來(lái)選擇不同的存儲(chǔ)方案,目前主要有用到 HDFS、MongoDB、Hbase、ES 等。在數(shù)據(jù)計(jì)算部分,當(dāng)前離線計(jì)算主要還是基于 Hive&MR、實(shí)時(shí)流計(jì)算是 Storm 、 Flink 以及還有另外一個(gè)自研的 bitmap 系統(tǒng) Naix。
在數(shù)據(jù)開(kāi)發(fā)這塊我們構(gòu)建了一套數(shù)據(jù)工坊、數(shù)據(jù)總線分發(fā)、任務(wù)調(diào)度等平臺(tái)。數(shù)據(jù)可視化與應(yīng)用部分主要是基于用戶需求構(gòu)建一系列數(shù)據(jù)應(yīng)用平臺(tái),包括:A/B 實(shí)驗(yàn)平臺(tái)、渠道推廣跟蹤平臺(tái)、數(shù)據(jù)可視化平臺(tái)、用戶畫像等等。
右側(cè)展示的是一些各組件都可能依賴的基礎(chǔ)服務(wù),包括地理位置、元數(shù)據(jù)管理、唯一設(shè)備標(biāo)識(shí)等。
如下圖所示是基本的數(shù)據(jù)架構(gòu)流圖,典型的 lamda 架構(gòu),從左端數(shù)據(jù)源收集開(kāi)始,Arachnia、AppSDK 分別將服務(wù)端、客戶端數(shù)據(jù)上報(bào)到代理服務(wù) collector,通過(guò)解析數(shù)據(jù)協(xié)議,把數(shù)據(jù)寫到 kafka,然后實(shí)時(shí)流會(huì)經(jīng)過(guò)一層數(shù)據(jù)分發(fā),最終業(yè)務(wù)消費(fèi) kafka 數(shù)據(jù)進(jìn)行實(shí)時(shí)計(jì)算。
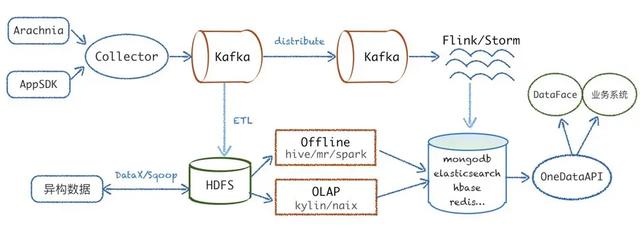
離線會(huì)由 ETL 服務(wù)負(fù)責(zé)從 Kafka dump 數(shù)據(jù)到 HDFS,然后異構(gòu)數(shù)據(jù)源(比如 MySQL、Hbase 等)主要基于 DataX 以及 Sqoop 進(jìn)行數(shù)據(jù)的導(dǎo)入導(dǎo)出,最終通過(guò) hive、kylin、spark 等計(jì)算把數(shù)據(jù)寫入到各類的存儲(chǔ)層,最后通過(guò)統(tǒng)一的對(duì)外 API 對(duì)接業(yè)務(wù)系統(tǒng)以及我們自己的可視化平臺(tái)等。
數(shù)據(jù)平臺(tái)的階段性發(fā)展
企業(yè)級(jí)數(shù)據(jù)平臺(tái)建設(shè)主要分三個(gè)階段:
- 剛開(kāi)始是基本使用免費(fèi)的第三方平臺(tái),這個(gè)階段的特點(diǎn)是能快速集成并看到 app 的一些統(tǒng)計(jì)指標(biāo),但是缺點(diǎn)也很明顯,沒(méi)有原始數(shù)據(jù)除了那些第三方提供的基本指標(biāo)其他分析、推薦等都無(wú)法實(shí)現(xiàn)。所以有從 0 到 1 的過(guò)程,讓我們自己有數(shù)據(jù)可以用;
- 在有數(shù)據(jù)可用后,因?yàn)闃I(yè)務(wù)線、需求量的爆發(fā),需要提高開(kāi)發(fā)效率,讓更多的人參與數(shù)據(jù)開(kāi)發(fā)、使用到數(shù)據(jù),而不僅僅局限于數(shù)據(jù)研發(fā)人員使用,所以就涉及到把數(shù)據(jù)、計(jì)算存儲(chǔ)能力開(kāi)放給各個(gè)業(yè)務(wù)線,而不是握在自己手上;
- 在當(dāng)數(shù)據(jù)開(kāi)放了以后,業(yè)務(wù)方會(huì)要求數(shù)據(jù)任務(wù)能否跑得更快,能否秒出,能否更實(shí)時(shí);另外一方面,為了滿足業(yè)務(wù)需求集群的規(guī)模越來(lái)越大,因此會(huì)開(kāi)始考慮滿足業(yè)務(wù)的同時(shí),如何實(shí)現(xiàn)更節(jié)省資源。
美圖現(xiàn)在是處于第二與第三階段的過(guò)渡期,在不斷完善數(shù)據(jù)開(kāi)放的同時(shí),也逐步提升查詢分析效率,以及開(kāi)始考慮如何進(jìn)行優(yōu)化成本。接下來(lái)會(huì)重點(diǎn)介紹 0 到 1 以及數(shù)據(jù)開(kāi)放這兩個(gè)階段我們平臺(tái)的實(shí)踐以及優(yōu)化思路。
從 0 到 1
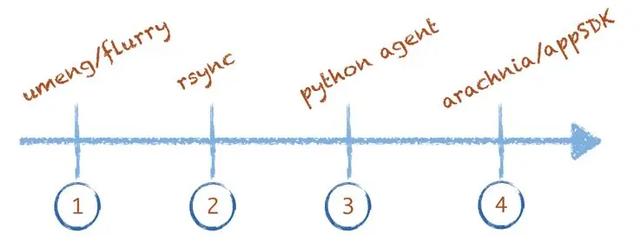
從 0 到 1 解決從數(shù)據(jù)采集到最終可以使用數(shù)據(jù)。如圖 4 所示是數(shù)據(jù)收集的演進(jìn)過(guò)程,從剛開(kāi)始使用類似 umeng、flurry 這類的免費(fèi)第三方平臺(tái),到后面快速使用 rsync 同步日志到一臺(tái)服務(wù)器上存儲(chǔ)、計(jì)算,再到后面快速開(kāi)發(fā)了一個(gè)簡(jiǎn)單的python腳本支持業(yè)務(wù)服務(wù)器上報(bào)日志,最終我們開(kāi)發(fā)了服務(wù)端日志采集系統(tǒng) Arachnia 以及客戶端 AppSDK。
數(shù)據(jù)采集是數(shù)據(jù)的源頭,在整個(gè)數(shù)據(jù)鏈路中是相對(duì)重要的環(huán)節(jié),需要更多關(guān)注:數(shù)據(jù)是否完整、數(shù)據(jù)是否支持實(shí)時(shí)上報(bào)、數(shù)據(jù)埋點(diǎn)是否規(guī)范準(zhǔn)確、以及維護(hù)管理成本。因此我們的日志采集系統(tǒng)需要滿足以下需求:
- 能集成管理維護(hù),包括 Agent 能自動(dòng)化部署安裝升級(jí)卸載、配置熱更、延遲方面的監(jiān)控;
- 在可靠性方面至少需要保證 at least once;
- 美圖現(xiàn)在有多 IDC 的情況,需要能支持多個(gè) IDC 數(shù)據(jù)采集匯總到數(shù)據(jù)中心;
- 在資源消耗方面盡量小,盡量做到不影響業(yè)務(wù)。
基于以上需求我們沒(méi)有使用 flume、scribe、fluentd,最終選擇自己開(kāi)發(fā)一套采集系統(tǒng) Arachnia。
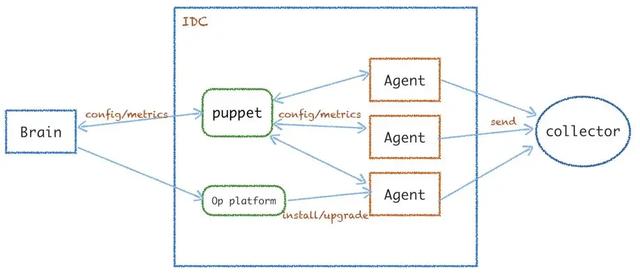
上圖是 Arachnia 的簡(jiǎn)易架構(gòu)圖,它通過(guò)系統(tǒng)大腦進(jìn)行集中式管理。puppet 模塊主要作為單個(gè) IDC 內(nèi)統(tǒng)一匯總 Agent 的 metrics,中轉(zhuǎn)轉(zhuǎn)發(fā)的 metrics 或者配置熱更命令。采集器 Agent 主要是運(yùn)維平臺(tái)負(fù)責(zé)安裝、啟動(dòng)后從 brain 拉取到配置,并開(kāi)始采集上報(bào)數(shù)據(jù)到 collector。
接著看 Arachnia 的實(shí)踐優(yōu)化,首先是 at least once 的可靠性保證。不少的系統(tǒng)都是采用把上報(bào)失敗的數(shù)據(jù)通過(guò) WAL 的方式記錄下來(lái),重試再上報(bào),以免上報(bào)失敗丟失。我們的實(shí)踐是去掉 WAL,增加了 coordinator 來(lái)統(tǒng)一的分發(fā)管理 tx 狀態(tài)。
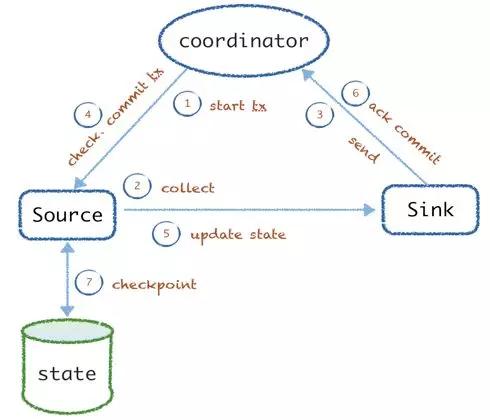
開(kāi)始采集前會(huì)從 coordinator 發(fā)出 txid,source 接收到信號(hào)后開(kāi)始采集,并交由 sink 發(fā)送數(shù)據(jù),發(fā)送后會(huì)ack tx,告訴 coordinator 已經(jīng) commit。coordinator 會(huì)進(jìn)行校驗(yàn)確認(rèn),然后再發(fā)送 commit 的信號(hào)給 source、sink 更新?tīng)顟B(tài),最終 tx 完 source 會(huì)更新采集進(jìn)度到持久層(默認(rèn)是本地 file)。該方式如果在前面 3 步有問(wèn)題,則數(shù)據(jù)沒(méi)有發(fā)送成功,不會(huì)重復(fù)執(zhí)行;如果后面 4 個(gè)步驟失敗,則數(shù)據(jù)會(huì)重復(fù),該 tx 會(huì)被重放。
基于上文的 at least once 可靠性保證,有些業(yè)務(wù)方是需要唯一性的,我們這邊支持為每條日志生成唯一 ID 標(biāo)識(shí)。另外一個(gè)數(shù)據(jù)采集系統(tǒng)的主要實(shí)踐是:唯一定位一個(gè)文件以及給每條日志做唯一的 MsgID,方便業(yè)務(wù)方可以基于 MsgID 在發(fā)生日志重復(fù)時(shí)能在后面做清洗。
我們一開(kāi)始是使用 filename,后面發(fā)現(xiàn) filename 很多業(yè)務(wù)方都會(huì)變更,所以改為 inode,但是 inode linux 會(huì)回收重復(fù)利用,最后是以 inode & 文件頭部?jī)?nèi)容做 hash 來(lái)作為fileID。而 MsgID 是通過(guò) agentID & fileID & offset 來(lái)唯一確認(rèn)。
數(shù)據(jù)上報(bào)之后由 collector 負(fù)責(zé)解析協(xié)議推送數(shù)據(jù)到 Kafka,那么 Kafka 如何落地到 HDFS 呢? 首先看美圖的訴求:
- 支持分布式處理;
- 涉及到較多業(yè)務(wù)線因此有多種數(shù)據(jù)格式,所以需要支持多種數(shù)據(jù)格式的序列化,包括 json、avro、特殊分隔符等;
- 支持因?yàn)闄C(jī)器故障、服務(wù)問(wèn)題等導(dǎo)致的數(shù)據(jù)落地失敗重跑,而且需要能有比較快速的重跑能力,因?yàn)橐坏┻@塊故障,會(huì)影響到后續(xù)各個(gè)業(yè)務(wù)線的數(shù)據(jù)使用;
- 支持可配置的 HDFS 分區(qū)策略,能支持各個(gè)業(yè)務(wù)線相對(duì)靈活的、不一樣的分區(qū)配置;
- 支持一些特殊的業(yè)務(wù)邏輯處理,包括:數(shù)據(jù)校驗(yàn)、過(guò)期過(guò)濾、測(cè)試數(shù)據(jù)過(guò)濾、注入等;
基于上述訴求痛點(diǎn),美圖從 Kafka 落地到 HDFS 的數(shù)據(jù)服務(wù)實(shí)現(xiàn)方式如圖 7 所示。
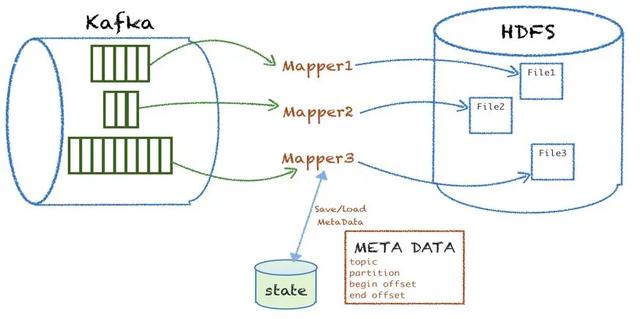
基于 Kafka 和 MR 的特點(diǎn),針對(duì)每個(gè) kafka topic 的 partition,組裝 mapper 的 inputsplit,然后起一個(gè) mapper 進(jìn)程處理消費(fèi)這個(gè)批次的 kafka 數(shù)據(jù),經(jīng)過(guò)數(shù)據(jù)解析、業(yè)務(wù)邏輯處理、校驗(yàn)過(guò)濾、最終根據(jù)分區(qū)規(guī)則落地寫到目標(biāo) HDFS 文件。
落地成功后會(huì)把這次處理的 meta 信息(包括 topic、partition、開(kāi)始的 offset、結(jié)束的offset)存儲(chǔ)到 MySQL。下次再處理的時(shí)候,會(huì)從上次處理的結(jié)束的 offset 開(kāi)始讀取消息,開(kāi)始新一批的數(shù)據(jù)消費(fèi)落地。
實(shí)現(xiàn)了基本功能后難免會(huì)遇到一些問(wèn)題,比如不同的業(yè)務(wù) topic 的數(shù)據(jù)量級(jí)是不一樣的,這樣會(huì)導(dǎo)致一次任務(wù)需要等待 partition 數(shù)據(jù)量最多以及處理時(shí)間最長(zhǎng)的 mapper 結(jié)束,才能結(jié)束整個(gè)任務(wù)。那我們?cè)趺唇鉀Q這個(gè)問(wèn)題呢?系統(tǒng)設(shè)計(jì)中有個(gè)不成文原則是:分久必合、合久必分,針對(duì)數(shù)據(jù)傾斜的問(wèn)題我們采用了類似的思路。
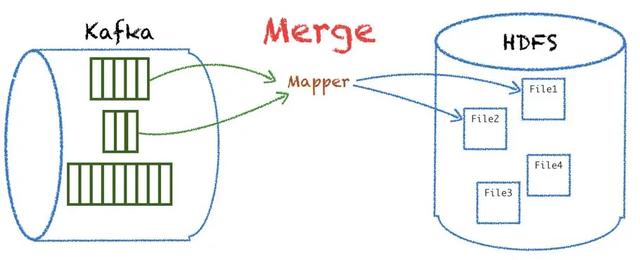
首先對(duì)數(shù)據(jù)量級(jí)較小的 partition 合并到一個(gè) inputsplit,達(dá)到一個(gè) mapper 可以處理多個(gè)業(yè)務(wù)的 partition 數(shù)據(jù),最終落地寫多份文件。
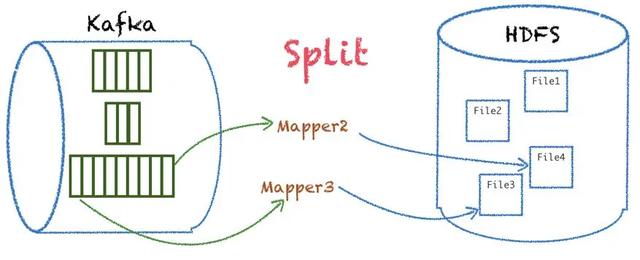
另外對(duì)數(shù)據(jù)量級(jí)較大的 partition 支持分段拆分,平分到多個(gè) mapper 處理同一個(gè) partition,這樣就實(shí)現(xiàn)了更均衡的 mapper 處理,能更好地應(yīng)對(duì)業(yè)務(wù)量級(jí)的突增。
除了數(shù)據(jù)傾斜的問(wèn)題,還出現(xiàn)各種原因?qū)е聰?shù)據(jù) dump 到 HDFS 失敗的情況,比如因?yàn)?kafka 磁盤問(wèn)題、hadoop 集群節(jié)點(diǎn)宕機(jī)、網(wǎng)絡(luò)故障、外部訪問(wèn)權(quán)限等導(dǎo)致該 ETL 程序出現(xiàn)異常,最終可能導(dǎo)致因?yàn)槲?close HDFS 文件導(dǎo)致文件損壞等,需要重跑數(shù)據(jù)。那我們的數(shù)據(jù)時(shí)間分區(qū)基本都是以天為單位,用原來(lái)的方式可能會(huì)導(dǎo)致一個(gè)天粒度的文件損壞,解析無(wú)法讀取。
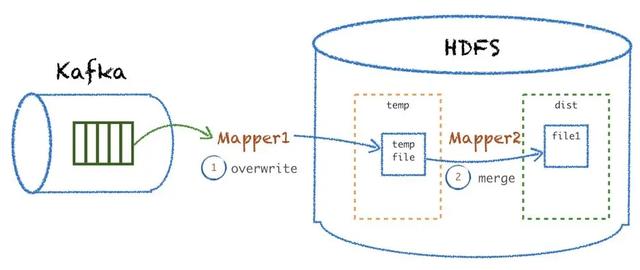
我們采用了分兩階段處理的方式:mapper 1 先把數(shù)據(jù)寫到一個(gè)臨時(shí)目錄,mapper 2 把 Hdfs 的臨時(shí)目錄的數(shù)據(jù) append 到目標(biāo)文件。這樣當(dāng) mapper1 失敗的時(shí)候可以直接重跑這個(gè)批次,而不用重跑整天的數(shù)據(jù);當(dāng) mapper2 失敗的時(shí)候能直接從臨時(shí)目錄 merge 數(shù)據(jù)替換最終文件,減少了重新 ETL 天粒度的過(guò)程。
在數(shù)據(jù)的實(shí)時(shí)分發(fā)訂閱寫入到 kafka1 的數(shù)據(jù)基本是每個(gè)業(yè)務(wù)的全量數(shù)據(jù),但是針對(duì)需求方大部分業(yè)務(wù)都只關(guān)注某個(gè)事件、某小類別的數(shù)據(jù),而不是任何業(yè)務(wù)都消費(fèi)全量數(shù)據(jù)做處理,所以我們?cè)黾恿艘粋€(gè)實(shí)時(shí)分發(fā) Databus 來(lái)解決這個(gè)問(wèn)題。
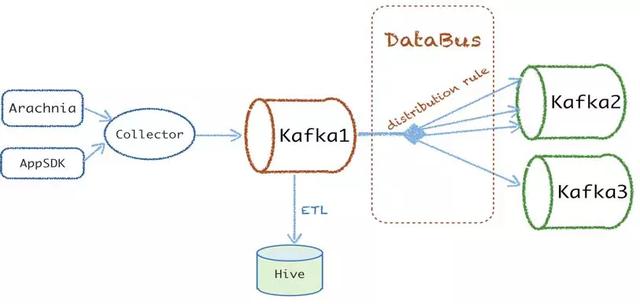
Databus 支持業(yè)務(wù)方自定義分發(fā) rules 往下游的 kafka 集群寫數(shù)據(jù),方便業(yè)務(wù)方訂閱處理自己想要的數(shù)據(jù),并且支持更小粒度的數(shù)據(jù)重復(fù)利用。
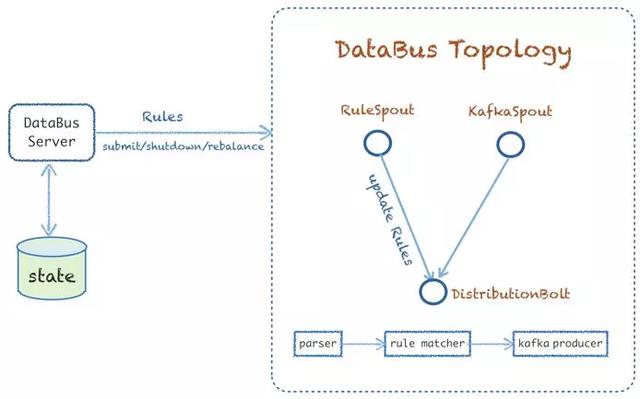
上圖可以看出 Databus 的實(shí)現(xiàn)方式,它的主體基于 Storm 實(shí)現(xiàn)了 databus topology。Databus 有兩個(gè) spout,一個(gè)支持拉取全量以及新增的 rules,然后更新到下游的分發(fā) bolt 更新緩存規(guī)則,另外一個(gè)是從 kafka 消費(fèi)的 spout。而 distributionbolt 主要是負(fù)責(zé)解析數(shù)據(jù)、規(guī)則 match,以及把數(shù)據(jù)往下游的 kafka 集群發(fā)送。
數(shù)據(jù)開(kāi)放
有了原始數(shù)據(jù)并且能做離線、實(shí)時(shí)的數(shù)據(jù)開(kāi)發(fā)以后,隨之而來(lái)的是數(shù)據(jù)開(kāi)發(fā)需求的井噴,數(shù)據(jù)研發(fā)團(tuán)隊(duì)?wèi)?yīng)接不暇。所以我們通過(guò)數(shù)據(jù)平臺(tái)的方式開(kāi)放數(shù)據(jù)計(jì)算、存儲(chǔ)能力,賦予業(yè)務(wù)方有數(shù)據(jù)開(kāi)發(fā)的能力。
對(duì)實(shí)現(xiàn)元數(shù)據(jù)管理、任務(wù)調(diào)度、數(shù)據(jù)集成、DAG 任務(wù)編排、可視化等不一一贅述,主要介紹數(shù)據(jù)開(kāi)放后,美圖對(duì)穩(wěn)定性方面的實(shí)踐心得。
數(shù)據(jù)開(kāi)放和系統(tǒng)穩(wěn)定性是相愛(ài)相殺的關(guān)系:一方面,開(kāi)放了之后不再是有數(shù)據(jù)基礎(chǔ)的研發(fā)人員來(lái)做,經(jīng)常會(huì)遇到提交非法、高資源消耗等問(wèn)題的數(shù)據(jù)任務(wù),給底層的計(jì)算、存儲(chǔ)集群的穩(wěn)定性造成了比較大的困擾;另外一方面,其實(shí)也是因?yàn)閿?shù)據(jù)開(kāi)放,才不斷推進(jìn)我們必須提高系統(tǒng)穩(wěn)定性。
針對(duì)不少的高資源、非法的任務(wù),我們首先考慮能否在 HiveSQL 層面能做一些校驗(yàn)、限制。如圖 13 所示是 HiveSQL 的整個(gè)解析編譯為可執(zhí)行的 MR 的過(guò)程:
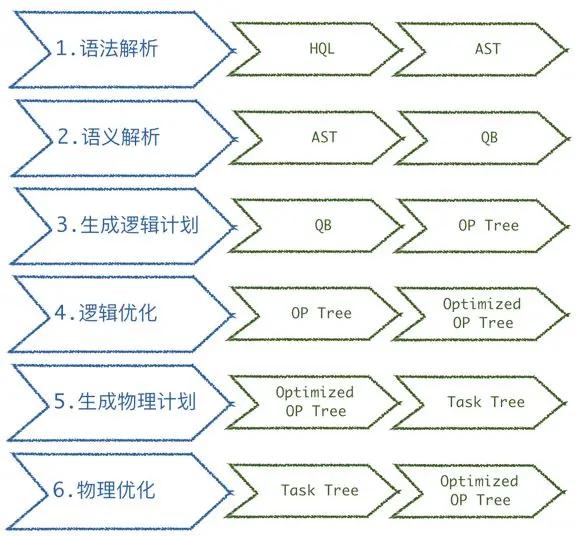
首先基于 Antlr 做語(yǔ)法的解析,生成 AST,接著做語(yǔ)義解析,基于AST 會(huì)生成 JAVA 對(duì)象 QueryBlock。基于 QueryBlock 生成邏輯計(jì)劃后做邏輯優(yōu)化,最后生成物理計(jì)劃,進(jìn)行物理優(yōu)化后,最終轉(zhuǎn)換為一個(gè)可執(zhí)行的 MR 任務(wù)。
我們主要在語(yǔ)義解析階段生成 QueryBlock 后,拿到它做了不少的語(yǔ)句校驗(yàn),包括:非法操作、查詢條件限制、高資源消耗校驗(yàn)判斷等。
第二個(gè)在穩(wěn)定性方面的實(shí)踐,主要是對(duì)集群的優(yōu)化,包括:
- 我們完整地對(duì) Hive、Hadoop 集群做了一次升級(jí)。主要是因?yàn)橹霸诘桶姹居?fix 一些問(wèn)題以及合并一些社區(qū)的 patch,在后面新版本都有修復(fù);另外一個(gè)原因是新版本的特性以及性能方面的優(yōu)化。我們把 Hive 從 0.13 版本升級(jí)到 2.1 版本,Hadoop 從 2.4 升級(jí)到 2.7;
- 對(duì) Hive 做了 HA 的部署優(yōu)化。我們把 HiveServer 和 MetaStoreServer 拆分開(kāi)來(lái)分別部署了多個(gè)節(jié)點(diǎn),避免合并在一個(gè)服務(wù)部署運(yùn)行相互影響;
- 之前執(zhí)行引擎基本都是 On MapReduce 的,我們也在做 Hive On Spark 的遷移,逐步把線上任務(wù)從 Hive On MR 切換到 Hive On Spark;
- 拉一個(gè)內(nèi)部分支對(duì)平時(shí)遇到的一些問(wèn)題做 bugfix 或合并社區(qū) patch 的特性;
在平臺(tái)穩(wěn)定性方面的實(shí)踐最后一部分是提高權(quán)限、安全性,防止對(duì)集群、數(shù)據(jù)的非法訪問(wèn)、攻擊等。提高權(quán)限主要分兩塊:API 訪問(wèn)與集群。
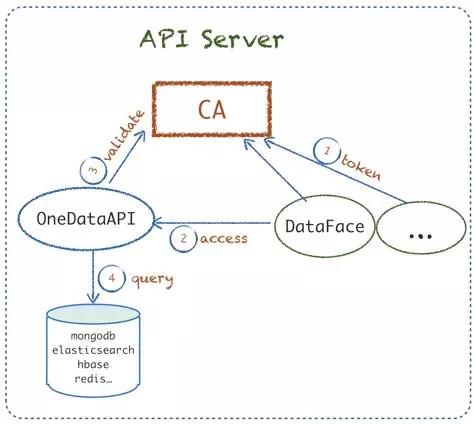
- API Server :上文提到我們有 OneDataAPI,提供給各個(gè)業(yè)務(wù)系統(tǒng)訪問(wèn)數(shù)據(jù)的統(tǒng)一 API。這方面主要是額外實(shí)現(xiàn)了一個(gè)統(tǒng)一認(rèn)證 CA 服務(wù),業(yè)務(wù)系統(tǒng)必須接入 CA 拿到 token 后來(lái)訪問(wèn)OneDataAPI,OneDataAPI 在 CA 驗(yàn)證過(guò)后,合法的才允許真正訪問(wèn)數(shù)據(jù),從而防止業(yè)務(wù)系統(tǒng)可以任意訪問(wèn)所有數(shù)據(jù)指標(biāo)。
- 集群:目前主要是基于 Apache Ranger 來(lái)統(tǒng)一各類集群,包括 Kafka、Hbase、Hadoop 等做集群的授權(quán)管理和維護(hù);
以上就是美圖在搭建完數(shù)據(jù)平臺(tái)并開(kāi)放給各個(gè)業(yè)務(wù)線使用后,對(duì)平臺(tái)穩(wěn)定性做的一些實(shí)踐和優(yōu)化。
總結(jié)
- 首先在搭建數(shù)據(jù)平臺(tái)之前,一定要先了解業(yè)務(wù),看業(yè)務(wù)的整體體量是否比較大、業(yè)務(wù)線是否比較廣、需求量是否多到嚴(yán)重影響我們的生產(chǎn)力。如果都是肯定答案,那可以考慮盡快搭建數(shù)據(jù)平臺(tái),以更高效、快速提高數(shù)據(jù)的開(kāi)發(fā)應(yīng)用效率。如果本身的業(yè)務(wù)量級(jí)、需求不多,不一定非得套大數(shù)據(jù)或者搭建多么完善的數(shù)據(jù)平臺(tái),以快速滿足支撐業(yè)務(wù)優(yōu)先。
- 在平臺(tái)建設(shè)過(guò)程中,需要重點(diǎn)關(guān)注數(shù)據(jù)質(zhì)量、平臺(tái)的穩(wěn)定性,比如關(guān)注數(shù)據(jù)源采集的完整性、時(shí)效性、設(shè)備的唯一標(biāo)識(shí),多在平臺(tái)的穩(wěn)定性方面做優(yōu)化和實(shí)踐,為業(yè)務(wù)方提供一個(gè)穩(wěn)定可靠的平臺(tái)。
- 在提高分析決策效率以及規(guī)模逐漸擴(kuò)大后需要對(duì)成本、資源做一些優(yōu)化和思考。