













碾壓99.8%人類對手,星際AI登上Nature,技術首次完整披露
僅剩0.2%的星際2玩家,還沒有被AI碾壓。
這是匿名混入天梯的AlphaStar,交出的最新成績單。
同時,DeepMind也在Nature上完整披露了AlphaStar的當前戰力和全套技術:
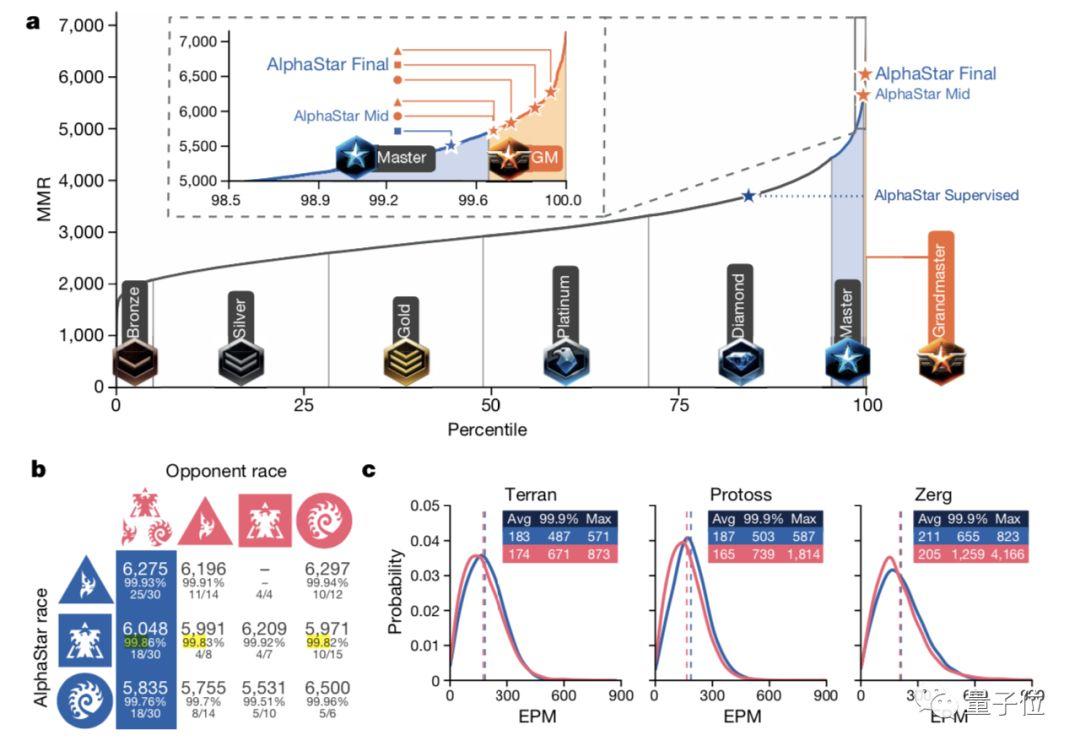
AlphaStar,已經超越了99.8%的人類玩家,在神族、人族和蟲族三個種族上都達到了宗師(Grandmaster)級別。
在論文里,我們還發現了特別的訓練姿勢:
不是所有智能體都為了贏
DeepMind在博客里說,發表在Nature上的AlphaStar有四大主要更新:
一是約束:現在AI視角和人類一樣,動作頻率的限制也更嚴了。
二是人族神族蟲族都能1v1了,每個種族都是一個自己的神經網絡。
三是聯賽訓練完全是自動的,是從監督學習的智能體開始訓練的,不是從已經強化學習過的智能體開始的。
四是戰網成績,AlphaStar在三個種族中都達到了宗師水平,用的是和人類選手一樣的地圖,所有比賽都有回放可看。
具體到AI的學習過程,DeepMind強調了特別的訓練目標設定:
不是每個智能體都追求贏面的最大化。
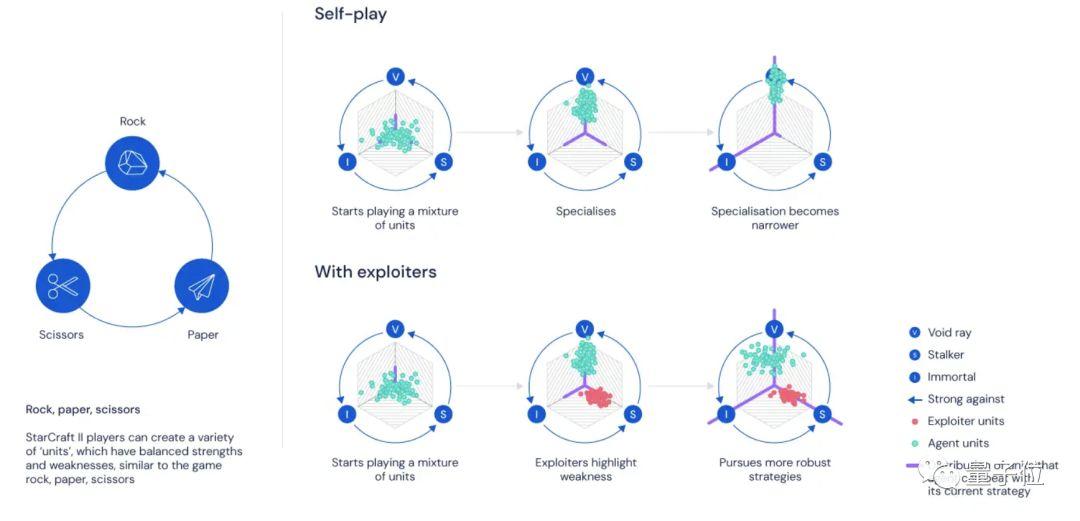
因為那樣智能體在自我對戰 (Self-Play) 過程中,很容易陷入某種特定的策略,只在特定的情況下有效,那面對復雜的游戲環境時,表現就會不穩定了。
于是,團隊參考了人類選手的訓練方法,就是和其他玩家一起做針對性訓練:一只智能體可以通過自身的操作,把另一只智能體的缺陷暴露出來,這樣便能幫對方練出某些想要的技能。
這樣便有了目標不同的智能體:第一種是主要智能體,目標就是贏,第二種負責挖掘主要智能體的不足,幫它們變得更強,而不專注于提升自己的贏率。DeepMind把第二種稱作“剝削者 (Exploiter) ”,我們索性叫它“陪練”。
AlphaStar學到的各種復雜策略,都是在這樣的過程中修煉得來的。
比如,藍色是主要玩家,負責贏,紅色是幫它成長的陪練。小紅發現了一種cannon rush技能,小藍沒能抵擋住:
然后,一只新的主要玩家 (小綠) 就學到了,怎樣才能成功抵御小紅的cannon rush技能:
同時,小綠也能打敗之前的主要玩家小藍了,是通過經濟優勢,以及單位組合與控制來達成的:
后面,又來了另一只新的陪練 (小棕) ,找到了主要玩家小綠的新弱點,用隱刀打敗了它:
循環往復,AlphaStar變得越來越強大。
至于算法細節,這次也完整展現了出來。
AlphaStar技術,最完整披露
許多現實生活中的AI應用,都涉及到多個智能體在復雜環境中的相互競爭和協調合作。
而針對星際爭霸這樣的即時戰略(RTS)游戲的研究,就是解決這個大問題過程中的一個小目標。
也就是說,星際爭霸的挑戰,實際上就是一種多智能體強化學習算法的挑戰。
AlphaStar學會打星際,還是靠深度神經網絡,這個網絡從原始游戲界面接收數據 (輸入) ,然后輸出一系列指令,組成游戲中的某一個動作。
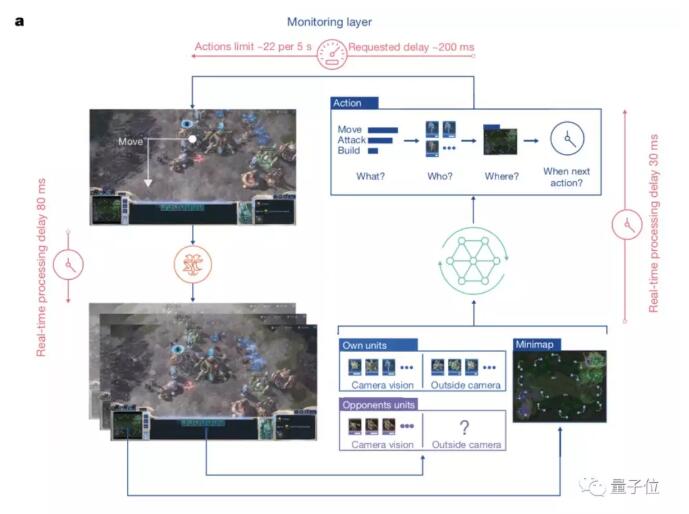
AlphaStar會通過概覽地圖和單位列表觀察游戲。
采取行動前,智能體會輸出要發出的行動類型(例如,建造),將該動作應用于誰,目標是什么,以及何時發出下一個行動。
動作會通過限制動作速率的監視層發送到游戲中。
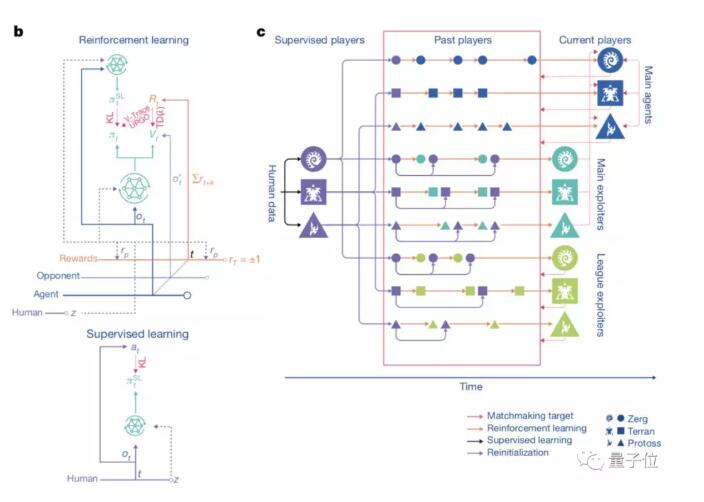
而訓練,則是通過監督學習和強化學習來完成的。
最開始,訓練用的是監督學習,素材來自暴雪發布的匿名人類玩家的游戲實況。
這些資料可以讓AlphaStar通過模仿星際天梯選手的操作,來學習游戲的宏觀和微觀策略。
最初的智能體,游戲內置的精英級 (Elite) AI就能擊敗,相當于人類的黃金段位 (95%) 。
而這個早期的智能體,就是強化學習的種子。
在它的基礎之上,一個連續聯賽 (Continuous League) 被創建出來,相當于為智能體準備了一個競技場,里面的智能體互為競爭對手,就好像人類在天梯上互相較量一樣:
從現有的智能體上造出新的分支,就會有越來越多的選手不斷加入比賽。新的智能體再從與對手的競爭中學習。
這種新的訓練形式,是把從前基于種群 (Population-Based) 的強化學習思路又深化了一些,制造出一種可以對巨大的策略空間進行持續探索的過程。
這個方法,在保證智能體在策略強大的對手面前表現優秀的同時,也不忘怎樣應對不那么強大的早期對手。
隨著智能體聯賽不斷進行,新智能體的出生,就會出現新的反擊策略 (Counter Strategies) ,來應對早期的游戲策略。
一部分新智能體執行的策略,只是早期策略稍稍改進后的版本;而另一部分智能體,可以探索出全新的策略,完全不同的建造順序,完全不同的單位組合,完全不同的微觀微操方法。
除此之外,要鼓勵聯賽中智能體的多樣性,所以每個智能體都有不同的學習目標:比如一個智能體的目標應該設定成打擊哪些對手,比如該用哪些內部動機來影響一個智能體的偏好。
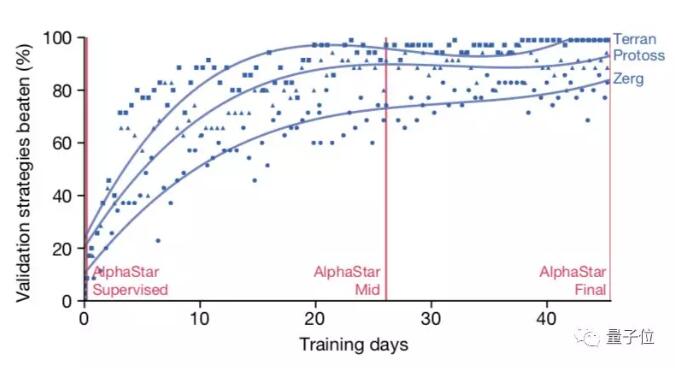
△聯盟訓練的魯棒性
而且,智能體的學習目標會適應環境不斷改變。
神經網絡給每一個智能體的權重,也是隨著強化學習過程不斷變化的。而不斷變化的權重,就是學習目標演化的依據。
權重更新的規則,是一個新的off-policy強化學習算法,里面包含了經驗重播 (Experience Replay) ,自我模仿學習 (Self-Imitation Learning) 以及策略蒸餾 (Policy Distillation) 等等機制。
歷時15年,AI制霸星際
《星際爭霸》作為最有挑戰的即時戰略(RTS)游戲之一,游戲中不僅需要協調短期和長期目標,還要應對意外情況,很早就成為了AI研究的“試金石”。
因為其面臨的是不完美信息博弈局面,挑戰難度巨大,研究人員需要花費大量的時間,去克服其中的問題。
DeepMind在Twitter中表示,AlphaStar能夠取得當前的成績,研究人員已經在《星際爭霸》系列游戲上工作了15年。
但DeepMind的工作真正為人所知,也就是這兩年的事情。
2017年,AlphaGo打敗李世石的第二年后,DeepMind與暴雪合作發布了一套名為PySC2的開源工具,在此基礎上,結合工程和算法突破,進一步加速對星際游戲的研究。
之后,也有不少學者圍繞星際爭霸進行了不少研究。比如南京大學的俞揚團隊、騰訊AI Lab、加州大學伯克利分校等等。
到今年1月,AlphaStar迎來了AlphaGo時刻。
在與星際2職業選手的比賽中,AlphaStar以總比分10-1的成績制霸全場,人類職業選手LiquidMaNa只在它面前堅持了5分36秒,就GG了。
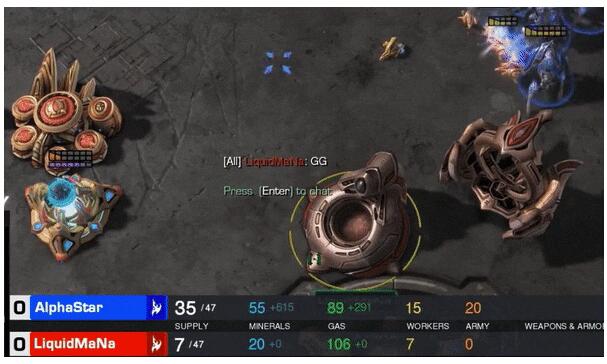
全能職業選手TLO在落敗后感嘆,和AlphaStar比賽很難,不像和人在打,有種手足無措的感覺。
半年后,AlphaStar再度迎來進化。
DeepMind將其APM (手速) 、視野都跟人類玩家保持一致的情況下,實現了對神族、人族、蟲族完全駕馭,還解鎖了許多地圖。

與此同時,并宣布了一個最新動態:AlphaStar將登錄游戲平臺戰網,匿名進行天梯匹配。
現在,伴隨著最新論文發布,AlphaStar的最新戰力也得到公布:擊敗了99.8%的選手,拿到了大師級稱號。
DeepMind在博客中表示,這些結果提供了強有力的證據,證明了通用學習技術可以擴展人工智能系統,使之在復雜動態的、涉及多個參與者的環境中工作。
而伴隨著星際2取得如此亮眼的成績,DeepMind也開始將目光投向更加復雜的任務上了。
CEO哈薩比斯說:
星際爭霸15年來一直是AI研究人員面臨的巨大挑戰,因此看到這項工作被《自然》雜志認可是非常令人興奮的。
這些令人印象深刻的成果,標志著我們朝目標——創造可加速科學發現的智能系統——邁出了重要的一步。
那么,DeepMind下一步要做什么?
哈薩比斯也多次說過,星際爭霸“只是”一個非常復雜的游戲,但他對AlphaStar背后的技術更感興趣。
但也有人認為,這一技術非常適合應用到軍事用途中。
不過,從谷歌與DeepMind 的態度中,這一技術更多的會聚焦在科學研究上。
其中包含的超長序列的預測,比如天氣預測、氣候建模。
或許對于這樣的方向,最近你不會陌生。
因為谷歌剛剛實現的量子優越性,應用方向最具潛力的也是氣候等大問題。
現在量子計算大突破,DeepMind AI更進一步。
未來更值得期待。你說呢?
One more thing
雖然AlphaStar戰績斐然,但有些人它還打不贏。
當時AlphaStar剛進天梯的時候,人類大魔王Serral就公開嘲諷,它就是來搞笑的。

但人家的確有實力,現在依舊能正面剛AI。
不過,敢這樣說話的高手,全球就只有一個。






















