云+社區(qū)聯(lián)合快手 深度解讀五大熱門大數(shù)據(jù)技術(shù)
原創(chuàng)【51CTO.com原創(chuàng)稿件】數(shù)據(jù)已經(jīng)成為企業(yè)寶貴的資產(chǎn),如何利用數(shù)據(jù)的分析挖掘,從而輔助企業(yè)進行商業(yè)決策,成為企業(yè)所關(guān)注的。
8月24日,由云+社區(qū)(騰訊云官方開發(fā)者社區(qū))聯(lián)合快手舉辦的《大數(shù)據(jù)技術(shù)實踐與應(yīng)用》沙龍活動成功舉行,沙龍聚焦于大數(shù)據(jù)的技術(shù)實踐與應(yīng)用,為到場的用戶奉上了一場大數(shù)據(jù)技術(shù)盛宴。來自騰訊云的專家和快手的工程師重點介紹了Spark、ElasticSearch,yarn、MapReduce、Flink等大數(shù)據(jù)技術(shù)的發(fā)展歷程、架構(gòu)優(yōu)化以及實踐應(yīng)用。
基于Spark構(gòu)建PB級別云數(shù)據(jù)倉庫
首位分享的嘉賓是來自騰訊專家工程師丁曉坤,他從AI與大數(shù)據(jù)的關(guān)系,大數(shù)據(jù)技術(shù)的發(fā)展趨勢,以及基于Spark計算引擎構(gòu)建云數(shù)倉的技術(shù)實踐三個方面展開進行分享。
2006年,Apache社區(qū)的Hadoop項目正式成立,作為三駕馬車的開源實踐,開啟了大數(shù)據(jù)時代;之后的2009年,AWS推出了EMR( Elastic MapReduce)彈性計算云平臺,開啟大數(shù)據(jù)的云計算時代;2012年隨著Yarn的孵化,2013年Spark項目正式成立,大數(shù)據(jù)進入加速發(fā)展階段;隨著2016年AlphaGo戰(zhàn)勝李世石,2018年Hadoop3.0的到來,AI和大數(shù)據(jù)關(guān)系越來越緊密,大數(shù)據(jù)也向云化和容器化方向加速進化。
那么AI和大數(shù)據(jù)具體是什么關(guān)系呢?丁曉坤解釋道,一、AI離不開數(shù)據(jù),人工智能的計算特別是深度模型,與數(shù)據(jù)的相關(guān)性非常高,數(shù)據(jù)越好模型也會越準(zhǔn)確。二、在標(biāo)準(zhǔn)的推薦場景中,有環(huán)形迭代的計算過程,從數(shù)據(jù)的抽取、準(zhǔn)備,到模型訓(xùn)練、數(shù)據(jù)模型發(fā)布,再到進一步抽取數(shù)據(jù),在迭代過程中進行優(yōu)化模型。
而基于以上這兩大關(guān)系,對AI和大數(shù)據(jù)兩大技術(shù)的融合提出新的需求。首先,數(shù)據(jù)在數(shù)據(jù)處理和AI訓(xùn)練框架之間的交互效率要求越來越高,就會產(chǎn)生tf.data、tf.transform等數(shù)據(jù)結(jié)構(gòu),而騰訊推出的Angel和Intel推出的BigDL這些計算框架可以快速地將Spark計算框架與機器模型訓(xùn)練框架結(jié)合的更好,TensorFlowOnSpark也可以快速提高環(huán)形迭代效率。其次,隨著AI的快速發(fā)展,大家對GPU的要求越來越高,通過優(yōu)化GPU與CPU之間任務(wù)隊列的調(diào)度從而提高效率,而GPU的調(diào)度則可以通過K8s和Hadoop3.0的發(fā)展也越來越高效。
大數(shù)據(jù)的發(fā)展離不開數(shù)據(jù)倉庫體系。數(shù)據(jù)倉庫從1989年提出后經(jīng)過了三個發(fā)展階段,第一個階段是數(shù)倉一體機時代,通過數(shù)據(jù)倉庫一體機企業(yè)可以進行報表分析、財務(wù)分析。隨后由于一體機在數(shù)據(jù)處理和性能上無法滿足企業(yè)需求,于是出現(xiàn)了分布式MPP數(shù)據(jù)庫,企業(yè)可以進行簡單的模型推測和預(yù)測計算。之后,企業(yè)更加關(guān)注IT成本,因此更多企業(yè)開始選擇云原生數(shù)據(jù)倉庫。
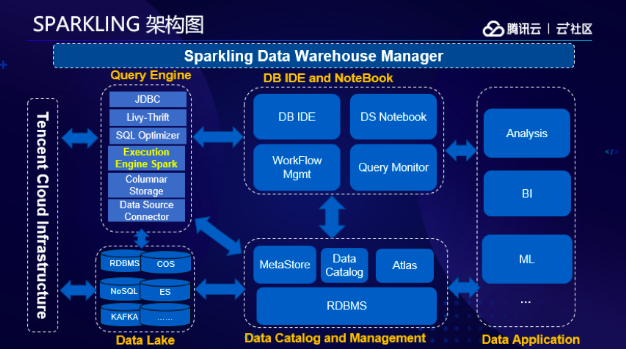
SPARKLING 架構(gòu)圖
最后,丁曉坤分享了基于Spark計算引擎構(gòu)建云數(shù)倉的技術(shù)實踐。為何騰訊云會選擇Spark來作為核心計算的支撐呢?丁曉坤歸納為四大原因,Spark生態(tài)豐富,支持場景比較全面,也是大數(shù)據(jù)領(lǐng)域比較熱門的開源項目;第二,Spark支持Python,SQL,R,Scala, Java 等語言提交計算任務(wù),比較容易上手;第三,依托開源社區(qū),盡可能使用開源項目,用戶可以熟知技術(shù)細節(jié);第四,由于Spark擁有DAG模型、RDD內(nèi)存計算和更細粒度的調(diào)度、鎢絲計劃等,使得性能更加優(yōu)越。
在騰訊云構(gòu)建數(shù)據(jù)倉庫時,也表現(xiàn)出一定的云特性。在彈性伸縮方面,可以支持三種類型的節(jié)點:主節(jié)點,核心計算節(jié)點和彈性計算節(jié)點,并且支持核心計算節(jié)點的橫向擴容,支持彈性計算節(jié)點的橫向擴縮容,這樣通過臨時的彈性計算節(jié)點達到存算的分離,彈性節(jié)點可以隨時擴縮容,快速回收計算資源從而降低成本。此外,通過平滑摘除機制,在所有的容器都執(zhí)行完畢,或執(zhí)行超時后移除,保證任務(wù)平滑穩(wěn)定的運行。第二個云特性就是虛擬環(huán)境優(yōu)化,增加NO Group層,讀取策略采用 node > node group > rack > off-rack的方式,通過跨Rack的機制,滿足云上虛擬環(huán)境的需求。第三是性能方面,可以通過Parquet將Bloom過濾器數(shù)據(jù)存儲到列元數(shù)據(jù),執(zhí)行選擇性查詢時啟用行組過濾。
對于Spark來說,應(yīng)用場景中更多的問題就是Shuffle的問題,Shuffle的效率會影響到數(shù)據(jù)計算性能的延遲和效率,隨著Spark的發(fā)展,通過性能優(yōu)越的內(nèi)存存儲技術(shù),提升Shuffle效率,從而提升Spark的效率。
未來,騰訊云構(gòu)建的基于Spark的數(shù)據(jù)倉庫還會支持Update和delete機制,以及增加對Serverless -K8S的支持,ACID的支持。
騰訊云ElasticSearch產(chǎn)品架構(gòu)與實踐
ElasticSearch在2010年左右出現(xiàn),是目前搜索領(lǐng)域知名度較高的產(chǎn)品。騰訊云大數(shù)據(jù)技術(shù)總監(jiān)鄒建平分享了騰訊云ElasticSearch產(chǎn)品在云原生架構(gòu)設(shè)計、高可用、自動化運維等方面的思考,以及如何利用ElasticSearch來實現(xiàn)企業(yè)智能化轉(zhuǎn)型。
首先,鄒建平介紹了ElasticSearch存儲分析的平臺的特點,支持全文檢索的搜索引擎,同時ElasticSearch也是NoSQL數(shù)據(jù)庫,支持?jǐn)?shù)據(jù)做保存和讀取,支持OLAP數(shù)據(jù)分析。此外,ElasticSearch是基于Java開發(fā)的,可以基于Lucene搜索庫通過倒排索引來直接通過關(guān)鍵字命中文檔,快速實現(xiàn)用戶檢索的請求。此外,通過在ElasticSearch外層開發(fā)RESTful接口,方便用戶平臺進行集群管理。而ElasticSearch產(chǎn)品成功的關(guān)鍵在于ELK Stack,擁有統(tǒng)一的生態(tài),目前開發(fā)者超過10萬人。
在進入到移動互聯(lián)網(wǎng)時代,APP爆炸式增長,但APP中的數(shù)據(jù)并不能像網(wǎng)頁一樣很容易被爬蟲到,這對ElasticSearch搜索引擎框架來說,帶來了新的發(fā)展機遇。ElasticSearch數(shù)據(jù)都存在存儲引擎中,用戶對這些數(shù)據(jù)進行新的價值挖掘時,對ElasticSearch提出了新的要求,這也是ElasticSearch從搜索逐漸向分析演進的原因。
從搜索到分析的演進過程中,共經(jīng)歷了五次變化。2010年,ElasticSearch剛推出時,主要支持搜索場景,使用倒排索引,在ElasticSearch中加入FieldData,將term到docid的映射逆轉(zhuǎn),變成docid到term。但是在檢索構(gòu)建過程中,對于數(shù)據(jù)量較大的檢索是非常災(zāi)難性的,加載速度較慢。因此到了2012年提出了DocValus,是通過Docld到Value的列式存儲。FieldData是在檢索時實時構(gòu)建,而DocValues是在索引時構(gòu)建的,因此更容易壓縮,此外,DocValues是寫在磁盤中而不是內(nèi)存,因此可以利用文件系統(tǒng)緩存來加速訪問。對比FieldData,DocValues的加速速度快2個數(shù)量級,并且檢索速度性能保持一致,緩存親和度更好。2014年以后,分析的復(fù)雜度越來越多,因此ElasticSearch做了去除框架的改進,后來提出的Aggregation可以支持嵌套聚合,Pipeline Aggregation能夠?qū)酆虾蟮慕Y(jié)果集再進行加工計算,例如求最大值、排序等等操作。2016年ElasticSearch算法進行優(yōu)化,其中涉及全局序數(shù)、DocValues、BKD tree等。2018年提出的Rollup,可以提升查詢的效率,降低存儲指標(biāo)。此外,ElasticSearch也支持SQL,支持多種訪問方式,例如CLI、Restful、Kibana Canvas、JDBC、ODBC等。
ElasticSearch增強了分析能力以外,還能做什么呢?首先是商業(yè)智能分析,通過各種手段對數(shù)據(jù)進行整合、統(tǒng)計和結(jié)果輸出。第二是日志、指標(biāo)和APM這也是ElasticSearch主推的功能之一,在業(yè)務(wù)日志、指標(biāo)都保存在存儲平臺后,將業(yè)務(wù)邏輯進行串聯(lián)實現(xiàn)APM,這樣就可以打通前端到后端的所有數(shù)據(jù),當(dāng)應(yīng)用出現(xiàn)問題后,可以快速的分析出問題所在。第三是基于機器學(xué)習(xí)的安全分析,能對日志、指標(biāo)進行異常檢測。
從2010年到如今,ElasticSearch從最初只用在搜索領(lǐng)域,到如今已經(jīng)是分析領(lǐng)域的熱門技術(shù),ElasticSearch發(fā)展的過程可以總結(jié)為“高”、“精”、“尖”。“高”指的是ElasticSearch在分布式計算方面有很多的設(shè)計,例如alias、index、shard、segment。“精”指的是ElasticSearch擁有多種高效的索引,包括倒排表、Docvalues、BKD tree、Global Ordinals等等。“尖”指的是LSM存儲結(jié)構(gòu),數(shù)據(jù)不可變,對緩存更有親和度。
第二大部分鄒建平重點介紹了騰訊云ElasticSearch架構(gòu)的優(yōu)化。
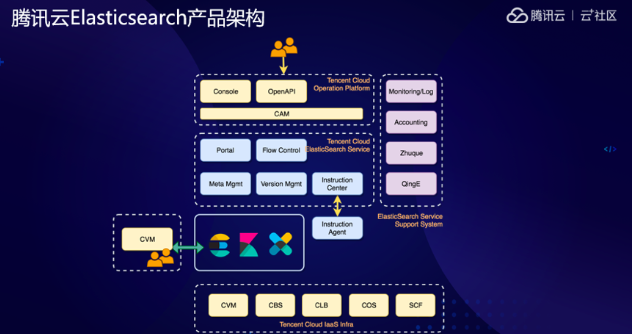
騰訊云ElasticSearch產(chǎn)品架構(gòu)圖
用戶使用騰訊云ElasticSearch產(chǎn)品時,經(jīng)常會有些擔(dān)心,數(shù)據(jù)是安全,可用性是否高,沒有專門的人員出了問題怎么辦。在數(shù)據(jù)安全方面,騰訊云ElasticSearch支持高級商業(yè)特性( X-Pack插件)數(shù)據(jù)權(quán)限管理,支持角色管理,集群、索引、文檔、字段各個級別的權(quán)限控制,外網(wǎng)HTTPS、黑白名單,客戶端、集群內(nèi)節(jié)點SSL傳輸加密;在CAM方面,設(shè)置了騰訊云賬號權(quán)限管理;在Audit方面,加入了集群操作審計日志和XPACK安全審計日志。在數(shù)據(jù)可靠性方面,在VPC中可以做到完全邏輯隔離,多維度網(wǎng)絡(luò)安全管控;在Backup方面,支持?jǐn)?shù)據(jù)定時備份和COS低成本備份;在Recycle-Bin,設(shè)置垃圾回收站,避免數(shù)據(jù)因人為原因丟失。在高可用方面,騰訊云進行了三方面的設(shè)置,實現(xiàn)跨可用區(qū)容災(zāi)。基于ElasticSearch數(shù)據(jù)分布感知框架實現(xiàn),主從副本放置到不同機房;三個專用主節(jié)點分布在三個可用區(qū),避免無法選主;必選專用主節(jié)點,避免腦裂。此外,通過調(diào)整分配算法,使得在不同節(jié)點之間打散,避免熱點不均的情況發(fā)生,從而達到分片均衡優(yōu)化。在高可運維方面,騰訊云也做了很多工作,通過自動監(jiān)控告警系統(tǒng)來支撐ElasticSearch日常運維。
最后,分享了騰訊云ES產(chǎn)品未來發(fā)展的三個方向,第一,在水平方面,是更好的將上下游產(chǎn)品聯(lián)動起來,例如如何做好各種數(shù)據(jù)導(dǎo)入,和hadoop產(chǎn)品、對象存儲產(chǎn)品的數(shù)據(jù)聯(lián)動做得更加易用;第二,在垂直方面,加強將ES里的解決方案例如APM、安全分析、垂直搜索等功能更好落地到云;第三,在矩陣方面,我們會將騰訊的一些能力融入到ES產(chǎn)品中,例如如何將微信通知、或者我們的一些NLP插件,和ES結(jié)合起來。
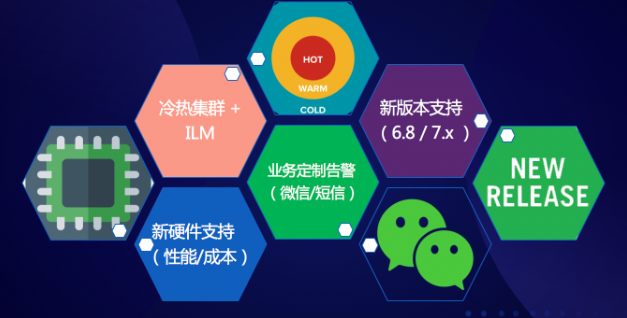
Elasticsearch近期新功能
yarn在快手應(yīng)用實踐與技術(shù)演進之路
來自快手?jǐn)?shù)據(jù)架構(gòu)工程師房孝敬,介紹yarn系統(tǒng)在快手的應(yīng)用實踐,遇到的問題以及相應(yīng)的技術(shù)演進過程。
Hadoop儼然已是業(yè)界認(rèn)可、成熟的數(shù)據(jù)存儲、處理框架。目前,Hadoop的發(fā)展已經(jīng)從1.0走到了2.0版本。在Hadoop v2.0的版本中引入Yarn,主要是解決了Hadoop v1.0中的擴展性問題。yarn主要分成三個模塊,一個是管理集群資源的RM,一個是管理機器資源情況的NM,還有管理APP資源和內(nèi)部邏輯的AM。
RM模塊內(nèi)部架構(gòu)分為兩部分,一個是管理集群中節(jié)點和APP的狀態(tài),分別有ResourceTrackerService和ApplicationMasterService進行管理。服務(wù)和RM通信后將消息送到RM內(nèi)部,生成相應(yīng)的事件,通過事件處理機制驅(qū)動APP和節(jié)點狀態(tài)機的更新,最后達成期望的狀態(tài)。yarn另一個主要功能是調(diào)度,早期yarn在NM心跳處理邏輯中觸發(fā)調(diào)度,因為調(diào)度比較耗時,會與其他事件處理過程競爭資源,導(dǎo)致雙方互相影響,之后社區(qū)進行優(yōu)化,將調(diào)度邏輯拆離到單獨的線程,但還是存在很大問題,后面會介紹具體的優(yōu)化。
快手在yarn方面的技術(shù)實踐主要分成四個方面:1、集群穩(wěn)定性方面的改動。2、對yarn的搶占機制做了優(yōu)化。3、yarn的調(diào)度性能做提升。4、計算集群小IO優(yōu)化。
集群規(guī)模變大后,節(jié)點變多,APP數(shù)量增多,導(dǎo)致事件處理壓力變大,調(diào)度壓力增大,機器故障變多。快手從RM優(yōu)化、避免單點問題兩方面進行穩(wěn)定性改進。
在RM優(yōu)化方面,快手曾經(jīng)升級集群導(dǎo)致RM掛掉,通過對冗余事件進行優(yōu)化,并且開發(fā)NM慢啟動策略,最終降低RM事件處理壓力,升級對RM的影響也就降低了。HDFS是yarn底層的設(shè)施,HDFS的卡頓會導(dǎo)致RM事件處理邏輯卡住,通過優(yōu)化事件處理邏輯中HDFS、DNS等IO操作,提升事件處理邏輯的穩(wěn)定性。優(yōu)化完后,發(fā)現(xiàn)事件處理占用的CPU較多,為了避免事件處理邏輯成為集群性能瓶頸,把NM事件處理從主事件處理流程中剝離到單獨的線程,提升了整個事件處理的速度。
在特定場景下,會出現(xiàn)奇怪的磁盤問題,比如磁盤是好的但是某個目錄是壞的,這種問題在現(xiàn)有機制下很難發(fā)現(xiàn),導(dǎo)致特定作業(yè)失敗。快手采用NM磁盤黑名單,通過task失敗信息進行規(guī)則匹配,發(fā)現(xiàn)磁盤問題,將有問題的磁盤放在黑名單中,不再向這個磁盤調(diào)度作業(yè)。yarn的一大問題是,一臺機器有問題調(diào)度失敗,會造成雪崩效應(yīng),造成作業(yè)大量失敗,快手通過集群層面黑名單機制解決這個問題。磁盤滿、fd泄露,線程泄露也是會造成故障的,快手通過對CPU,mem,磁盤文件大小,fd數(shù)目,線程數(shù)目的控制,增強底層隔離,避免相互影響。集群中的問題機器較多,在集群規(guī)模變大后,如何發(fā)現(xiàn)問題機器是個難題,快手通過Container失敗率高機器check、物理指標(biāo)異常topN check和Job失敗信息匯總?cè)齻€方法來快速發(fā)現(xiàn)問題機器。
yarn一個主要的功能就是調(diào)度整個集群的資源。yarn的調(diào)度模型是比較復(fù)雜的,為了保證調(diào)度公平性,需要對隊列和app進行排序。快手的初始思路是減少排序時間,縮小排序規(guī)模,優(yōu)化排序算法。通過優(yōu)化后,能夠支撐5000臺機器的規(guī)模。
但是優(yōu)化后還是存在問題,擴展性不足,只能利用一個CPU;缺少全局節(jié)點信息,調(diào)度策略難以全局決策。最終,快手重構(gòu)了調(diào)度架構(gòu)和邏輯,開發(fā)了Kwai scheduler,建立資源分配的上帝視角,預(yù)先給隊列分配資源,并發(fā)批量調(diào)度。先選APP再選節(jié)點,調(diào)度策略方便擴充,最終線上的調(diào)度速度可以達到每秒鐘4萬多。
未來,快手將在三個方面進行建設(shè),資源分級保障建設(shè)、多集群建設(shè)和超配在離線混合部署。目前,快手yarn集群規(guī)模較大,使用資源非常多,通過作業(yè)畫像和分級保障體系把資源傾斜給更重要的作業(yè)。此外,單集群容量有限,快手還會考慮多集群建設(shè)。第三,快手的yarn主要托管是離線計算的資源,公司很多非YARN管理的空閑資源沒有使用,將合適的任務(wù)調(diào)度到空閑的機器上,也是快手未來探索的方向。
云端大數(shù)據(jù)產(chǎn)品架構(gòu)及實踐
彈性MapReduce是騰訊云構(gòu)架于云端海量存儲、計算基礎(chǔ)設(shè)施之上的云端Hadoop 框架,用戶可在十分鐘獲得一個安全、低成本、高可靠、高彈性擴展、架構(gòu)可持續(xù)演進的專屬大數(shù)據(jù)集群。騰訊云高級工程師喬超分享了騰訊云大數(shù)據(jù)EMR產(chǎn)品及其價值,同時根據(jù)實際經(jīng)驗介紹了大數(shù)據(jù)平臺實踐。
如今,各大企業(yè)都意識到數(shù)據(jù)的重要性,如何挖掘數(shù)據(jù)價值,為企業(yè)做出決策,變得尤為重要。然而,在企業(yè)級大數(shù)據(jù)架構(gòu)中,主要在三大領(lǐng)域存在挑戰(zhàn),企業(yè)級數(shù)倉與數(shù)據(jù)集市構(gòu)建、流式數(shù)據(jù)分析和海量數(shù)據(jù)檢索與分析,而各大社區(qū)也都通過開源組件形成了不同的解決方案。但是構(gòu)建大數(shù)據(jù)平臺的技術(shù)復(fù)雜性高,構(gòu)建周期長,運維基礎(chǔ)設(shè)施匱乏,技術(shù)抗風(fēng)險能力弱,因此,大數(shù)據(jù)開源技術(shù)能一定程度滿足研發(fā)工程師的顯性技術(shù)需求,但無法滿足企業(yè)潛在的深層次隱形需求。
為了幫助企業(yè)解決以上挑戰(zhàn)問題,騰訊云從技術(shù)組件到產(chǎn)品服務(wù),通過完善大數(shù)據(jù)基礎(chǔ)設(shè)施幫助企業(yè)客戶高效應(yīng)對從初創(chuàng)發(fā)展到成熟過程中的大數(shù)據(jù)技術(shù)性挑戰(zhàn)。騰訊云將企業(yè)劃分為初創(chuàng)型和成熟型,對于初創(chuàng)型企業(yè),騰訊云提供封裝好的開箱即用的產(chǎn)品,包括計算服務(wù)、BI分析組件,云數(shù)倉、云搜等能力。而對于成熟型企業(yè),騰訊云幫助其解決偏運維層面的問題,結(jié)合用戶自己的特色,更加貼近用戶的業(yè)務(wù)應(yīng)用場景,幫助用戶建立自己的大數(shù)據(jù)解決方案,騰訊云在此方面則提供彈性MapReduce和ES。
喬超介紹了騰訊云云端大數(shù)據(jù)基礎(chǔ)設(shè)施的優(yōu)勢:1、海量計算資源的優(yōu)勢,騰訊云擁有全球25個地理區(qū)域、全球51個可用區(qū)、分鐘級計算存儲資源實時調(diào)度,解決用戶就近計算的場景。2、開放性和連續(xù)。通過與開源基金及公司協(xié)作,開源協(xié)同的持續(xù)性研發(fā)資源投入。3、大數(shù)據(jù)業(yè)務(wù)場景化。騰訊云提供騰訊系金融、社交網(wǎng)站、游戲、視頻、新聞資訊、電商等領(lǐng)域大數(shù)據(jù)場景應(yīng)用,同時也包括用戶畫像、精準(zhǔn)推薦、用戶行為分析、金融風(fēng)控等場景應(yīng)用。4、持續(xù)性服務(wù)。騰訊云提供線上技術(shù)交流、培訓(xùn),線下技術(shù)沙龍交流平臺以及持續(xù)性產(chǎn)品/服務(wù)支撐。
彈性MapReduce是騰訊云構(gòu)架于云端海量存儲、計算基礎(chǔ)設(shè)施之上的云端Hadoop 框架,用戶可在十分鐘獲得一個安全、低成本、高可靠、高彈性擴展、架構(gòu)可持續(xù)演進的專屬大數(shù)據(jù)集群。該產(chǎn)品幫助企業(yè)在提升研發(fā)效率、運維效率、降低硬件成本的同時,輕松應(yīng)對TB、PB級的海量數(shù)據(jù)的價值挖掘挑戰(zhàn)。
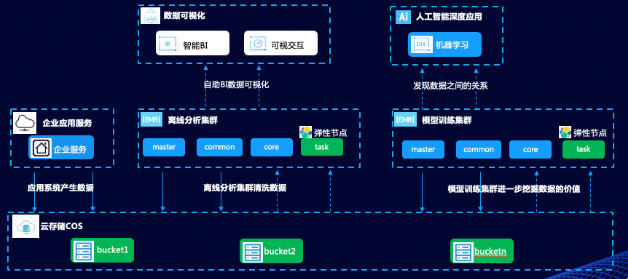
彈性MapReduce可以靈活應(yīng)對多業(yè)務(wù)場景,包括在線業(yè)務(wù)、數(shù)據(jù)倉庫、實時流式計算,機器學(xué)習(xí),有效支持企業(yè)大數(shù)據(jù)架構(gòu)可持續(xù)演進。基于云端的Hadoop框架產(chǎn)品將有效提升企業(yè)對大數(shù)據(jù)基礎(chǔ)設(shè)施的快速構(gòu)建、高效運維及應(yīng)用的綜合性大數(shù)據(jù)能力。騰訊云彈性MapReduce產(chǎn)品包括四大優(yōu)勢:10分鐘構(gòu)建上百節(jié)點大數(shù)據(jù)集群,支持控制臺/程序API靈活構(gòu)建;十分鐘節(jié)點級橫向擴展(數(shù)節(jié)點擴展至數(shù)百節(jié)點),十分鐘集群級橫向擴展(單一集群擴展至數(shù)個異構(gòu)集群);百余監(jiān)控指標(biāo)覆蓋(服務(wù)器級、服務(wù)級),異常事件秒級觸達,Ddos/VPC安全加固、 Kerberos節(jié)點級服務(wù)信任;云端多源數(shù)據(jù)支持(云數(shù)據(jù)庫、ES、Ckafka、流計算、Snova云數(shù)倉),云端可視化BI工具無縫對接。
在沙龍現(xiàn)場,喬超現(xiàn)場演示了通過騰訊云快速構(gòu)建云端大數(shù)據(jù)分析平臺,只需要四步,首先勾選EMR組件,然后配置集群規(guī)格,創(chuàng)建集群,最后快速擴縮容。
最后,喬超介紹了騰訊云彈性MapReduce運營實踐全方位規(guī)劃,包括初期規(guī)劃、集群構(gòu)建、參數(shù)優(yōu)化、線上運營四個階段。在初期規(guī)劃方面,企業(yè)需要進行資源預(yù)估,同時騰訊云也會提供建議,然后企業(yè)進行機型配置核定,包括機型、核數(shù)、內(nèi)存、磁盤等方面。在集群構(gòu)建階段,通過大數(shù)據(jù)技術(shù)棧,提供從底層基礎(chǔ)架構(gòu)到上層應(yīng)用全方位的技術(shù)能力。而集群部署模式分為混合部署和獨立部署兩種,初期階段可以混合部署,隨著業(yè)務(wù)規(guī)模及企業(yè)發(fā)展,逐步走向獨立部署模式。經(jīng)過EMR團隊多年的經(jīng)驗積累,在參數(shù)優(yōu)化這塊他們也給出了一些建議,包括通過心跳設(shè)置和元數(shù)據(jù)管理對HDFS進行優(yōu)化,通過ResourceManager堆大小、TimeLineServer和AMShare三個方面對yarn進行優(yōu)化,通過FetchTask和計算引擎對Hive進行優(yōu)化等。
騰訊基于Flink構(gòu)建實時流計算平臺的技術(shù)實踐
Flink是由Apache軟件基金會開發(fā)的開源流處理框架,其核心是用Java和Scala編寫的分布式流數(shù)據(jù)流引擎。而Flink也是大數(shù)據(jù)處理領(lǐng)域最近冉冉升起的一顆新星。騰訊高級工程師楊華介紹了騰訊實時流計算技術(shù)的演進過程以及對Apache Flink所進行的優(yōu)化與擴展。
Flink在騰訊的發(fā)展要追溯到2017年。2017年上半年,騰訊對Flink框架進行調(diào)研,包括性能對比測試,評估關(guān)鍵可用性等現(xiàn)網(wǎng)關(guān)鍵指標(biāo)。到了2017年下半年,騰訊內(nèi)部進行特性的定制開發(fā)與性能優(yōu)化,相關(guān)業(yè)務(wù)的灰度測試、上線。2018年上半年,騰訊打造Oceanus實時流計算平臺,覆蓋公用云、專有云場景,內(nèi)部業(yè)務(wù)遷移與試運行。2018年下半年,Oceanus公有云流計算產(chǎn)品正式上線公測,騰訊其他BG流計算業(yè)務(wù)與大數(shù)據(jù)套件整合。到了今年上半年,騰訊上線在線機器學(xué)習(xí)業(yè)務(wù)、秒級監(jiān)控等服務(wù),打造場景化的業(yè)務(wù)支撐能力,支持廣告、推薦業(yè)務(wù)。雖然騰訊研發(fā)Flink只有2年半的時間,但是目前騰訊的Flink支持集群總核數(shù)達到34萬,峰值算力達到每秒2.1億,日均處理消息量20萬億,日均消息規(guī)模是PB級別。
騰訊對Flink進行了四方面的優(yōu)化。由于Flink的Web UI不利于定位新網(wǎng)的問題,因此在Flink1.6版本時,騰訊對web UI進行重構(gòu)。第二,騰訊對JobManager Failover進行優(yōu)化。通過Standalone模式和宿主模式,騰訊云對Queryable state進行了優(yōu)化。最后,騰訊對Increment Window進行改進,對Flink原生窗口進行增強。
Apache Hudi是今年上半年剛剛加入Apache孵化器進行孵化的項目,是Uber于2016年在內(nèi)部環(huán)境中使用的框架,用于大規(guī)模數(shù)據(jù)集。通過Upsert和Incremental pull兩種方式,Hudi可以在Hadoop重新分布式文件系統(tǒng)數(shù)據(jù)集上進行集中。 Hudi可以在延遲和成本的維度上,在單個的物理數(shù)據(jù)集上提供三個不同的邏輯視圖:一是讀優(yōu)化視圖,能夠指向常規(guī)的Hive表進行查詢;二是增量視圖,能夠捕獲數(shù)據(jù)集的變更流供給下游的Job/ETL,允許增量拉取;三是準(zhǔn)實時視圖,在準(zhǔn)實時數(shù)據(jù)上進行查詢,同時聯(lián)合Apache Parquet(列) & Avro(行)的數(shù)據(jù)。而Flink和Hudi進行整合,可以提升分析過程的效率。
騰訊實時計算團隊對社區(qū)版的Flink進行了深度的優(yōu)化,并在此之上構(gòu)建了一個集開發(fā)、測試、部署和運維于一體的一站式可視化實時計算平臺——Oceanus。騰訊云流計算Oceanus是位于云端的流式數(shù)據(jù)匯聚和計算服務(wù),用戶只需幾分鐘就可輕松構(gòu)建流計算應(yīng)用,而無須關(guān)注基礎(chǔ)設(shè)施的運維,并能便捷對接豐富的云上數(shù)據(jù)源。它可以幫助企業(yè)構(gòu)建多樣化的流式數(shù)據(jù)處理能力,輕松應(yīng)對海量數(shù)據(jù)實時處理和分析決策的挑戰(zhàn)。
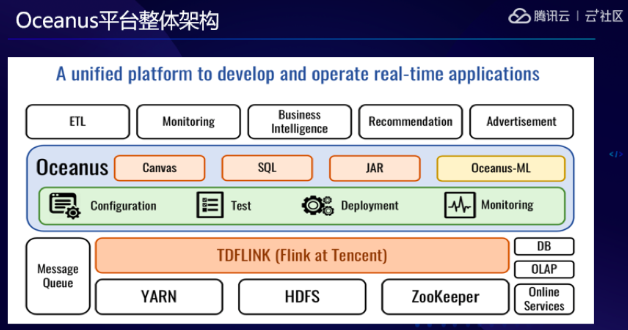
Oceanus平臺整體架構(gòu)
Oceanus平臺特點:1、實時計算;2、完全托管;3、超高彈性,支持彈性擴縮容;4、簡易SQL模式;5、支持UDX/自定義程序,方便大家去簡化開發(fā)邏輯的成本;6、豐富的云端生態(tài),提供一些生態(tài)的產(chǎn)品,包括數(shù)據(jù)采集等服務(wù)。
Oceanus擁有豐富的流計算應(yīng)用場景,有效支持企業(yè)的實時計算需要和提升決策分析水平。典型的應(yīng)用場景包括:1、點擊流分析,可以分析用戶在Oceanus進行操作的行為,通過后臺相應(yīng)分析為商業(yè)決策或者廣告投放提供支撐;2、金融實時風(fēng)控,欺詐的行為監(jiān)測;3、物聯(lián)網(wǎng)IoT監(jiān)控;4、電商精準(zhǔn)推薦。
Oceanus覆蓋作業(yè)的生命周期,包括開發(fā)、測試、部署、運維,用戶只需要關(guān)注它的應(yīng)用邏輯的實踐。目前,Oceanus應(yīng)用建構(gòu)方式包括三種模式:1、畫布的形式來構(gòu)建應(yīng)用,騰訊將Flink做成相應(yīng)的組件放在Oceanus的平臺上,用戶在使用的時候只需要在具體的算力進行相應(yīng)的編排即可;2、標(biāo)準(zhǔn)SQL的方式,支持SQL語法可以快速高效的創(chuàng)建應(yīng)用;3、支持Datastream API和dataset API,可高度定制特殊的業(yè)務(wù)邏輯。
最后,楊華介紹了Oceanus應(yīng)用提交步驟,首先讓用戶配置相應(yīng)的元數(shù)據(jù),包括消費信息、數(shù)據(jù)格式,然后創(chuàng)建DAG,最后再經(jīng)過編譯提交。
通過半天的沙龍活動,到場的用戶紛紛表示收獲滿滿,不但對大數(shù)據(jù)相關(guān)技術(shù)有了深入的了解,還對騰訊云在大數(shù)據(jù)方面所做的支持和優(yōu)化給予了肯定,期待未來更多的技術(shù)內(nèi)容分享。
云+社區(qū)技術(shù)沙龍是騰訊云官方開發(fā)者社區(qū)舉辦的沙龍活動,希望通過分享技術(shù)讓更多開發(fā)者學(xué)習(xí)和交流,成為騰訊云連接開發(fā)者的平臺,共同打造技術(shù)影響力。
【51CTO原創(chuàng)稿件,合作站點轉(zhuǎn)載請注明原文作者和出處為51CTO.com】