













重回榜首的BERT改進版開源了,千塊V100、160GB純文本的大模型
前段時間 Facebook 創建的改進版 BERT——RoBERTa,打敗 XLNet 登上了 GLUE 排行榜榜首。近日,Facebook 公開了該模型的研究細節,并開源了模型代碼。
BERT 自誕生以來就展現出了卓越的性能,GLUE 排行榜上前幾名的模型一度也大多使用 BERT。然而,XLNet 的橫空出世,
打破了 BERT 的紀錄
。不過,不久之后,劇情再次出現反轉,Facebook 創建的改進版 BERT——RoBERTa,登上了 GLUE 排行榜榜首。
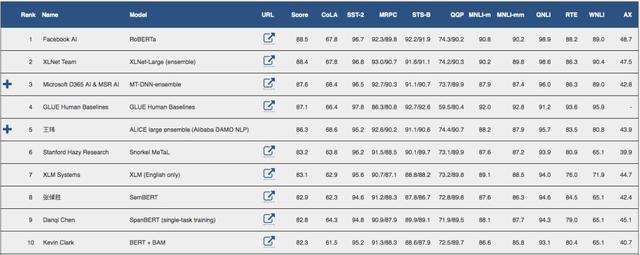
圖源:https://gluebenchmark.com/leaderboard/
Facebook 的研究人員表示,如果訓練得更久一點、數據再大一點,
BERT 就能重返SOTA
。
那么 RoBERTa 到底訓練了多長時間,使用了多少數據呢?近日,Facebook 研究人員公開了研究細節。
論文地址:https://arxiv.org/pdf/1907.11692.pdf
GitHub 地址:https://github.com/pytorch/fairseq/tree/master/examples/roberta
RoBERTa 到底有多大
之前 XLNet 團隊就對標準的 BERT 和 XLNet
做過一次公平的對比
,他們測試了在相同參數水平、預訓練數據、超參配置等情況下兩者的效果。當然,XLNet 通過修改架構與任務,它的效果是全面超過標準 BERT 的。但如果 BERT 要再次超越 XLNet,那么數據和算力都需要更多。
算力
據介紹,Facebook 研究人員在多臺 DGX-1 計算機上使用混合精度浮點運算,每臺計算機具備 8 個 32GB Nvidia V100 GPU,這些 GPU 通過 Infiniband 連接。
但研究者并沒有具體說 RoBERTa 使用了多少張 V100 GPU 訓練了多長時間,我們只能了解到他們訓練 Large 模型用 1024 塊 V100 訓練了一天,這樣以谷歌云的價格來算需要 6.094 萬美元。如下是原論文所述:
We pretrain for 100K steps over a comparable BOOKCORPUS plus WIKIPEDIA dataset as was used in Devlin et al. (2019). We pretrain our model using 1024 V100 GPUs for approximately one day.
因為 XLNet 的 TPU 訓練價格也是 6 萬美元,而且直觀上用 GPU 訓練會比 TPU 貴,所以我們根據上面的描述猜測 6.094 萬美元是在 BOOKCORPUS 加 WIKIPEDIA 數據集上訓練的成本。此外,XLNet 數據集擴充十倍,它的 TPU 訓練成本也增加了 5 倍,也許 RoBERTa 也遵循同樣的規則?
數據
BERT 模型預訓練的關鍵是大量文本數據。Facebook 研究人員收集了大量數據集,他們考慮了五個不同大小、不同領域的英語語料庫,共有 160GB 純文本,而 XLNet 使用的數據量是 126GB。這些語料庫分別是:
- BOOKCORPUS (Zhu et al., 2015) 和英語維基百科:這是 BERT 訓練時所用的原始數據 (16GB);
- CC-NEWS:Facebook 研究人員從 CommonCrawl News 數據集的英語部分收集到的數據,包含 2016 年 9 月到 2019 年 2 月的 6300 萬英語新聞文章(過濾后有 76GB 大小);
- OPENWEBTEXT (Gokaslan and Cohen, 2019):Radford et al. (2019) 中介紹的 WebText 語料庫的開源克隆版本。其中包含爬取自 Reddit 網站共享鏈接的網頁內容 (38GB);
- STORIES:Trinh and Le (2018) 中提到的數據集,包含 CommonCrawl 數據的子集,該數據集經過過濾以匹配 Winograd schemas 的故事性風格 (31GB)。
這樣的數據量已經非常大了,它是原來 BERT 數據量的十多倍。但正如 XLNet 作者楊植麟所言,數據量大并不一定能帶來好處,我們還需要在數量與質量之間做權衡。也許十倍量級的數據增加,可能還不如幾倍高質量數據帶來的提升大。
RoBERTa 到底是什么
Facebook 對 BERT 預訓練模型進行了復現研究,對調參和訓練數據規模的影響進行了評估,發現 BERT 訓練嚴重不足。于是他們提出了 BERT 的改進版——RoBERTa,它可以匹敵甚至超過所有 post-BERT 方法的性能。
這些改進包括:
- 模型訓練時間更長,batch 規模更大,數據更多;
- 移除「下一句預測」這一訓練目標;
- 在更長的序列上訓練;
- 動態改變應用于訓練數據上的掩碼模式。
Facebook 研究人員還收集了一個新型大數據集 CC-NEWS,以更好地控制訓練數據集規模的影響。CC-NEWS 數據集的規模與其他私人使用數據集差不多。
總之,Facebook 研究人員關于 RoBERTa 的研究貢獻可以總結如下:
- 展示了一組重要的 BERT 設計選擇、訓練策略,介紹了一些可使下游任務性能更優的替代方法;
- 使用新型數據集 CCNEWS,并確認使用更多數據進行預訓練可以進一步提升模型在下游任務上的性能;
- 訓練方面的改進證明,在正確的設計選擇下,掩碼語言模型預訓練的性能堪比其他近期方法。
RoBERTa 都改了些啥
對于原版 BERT,直接用它來做極大數據的預訓練并不能 Work,我們還需要一些特殊的技巧來提升模型的魯棒性,這也就是 Facebook 研究者主要嘗試的。如下研究人員在論文中揭示并量化了 BERT 要進行哪些改進才能真正變得穩健。
1. 靜態 vs. 動態掩碼
BERT 依賴隨機掩碼和預測 token。原版的 BERT 實現在數據預處理期間執行一次掩碼,得到一個靜態掩碼。Facebook 研究者將該策略與動態掩碼進行比較,動態掩碼即,每次向模型輸入一個序列時都會生成掩碼模式。在預訓練進行更多步或使用更大的數據集時,這點變得尤其重要。
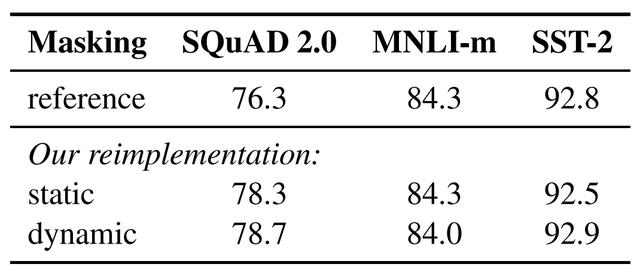
表 1: BERT_BASE 的靜態和動態掩碼比較。
2. 模型輸入格式和下一句預測
在原版的 BERT 預訓練步驟中,模型觀察到兩個連接在一起的文檔片段,這兩個片段要么是從相同的文檔中連續采樣,要么采樣自一個文檔的連續部分或不同文檔。為了更好地理解這種結構,研究者比較了幾種訓練格式:
- SEGMENT-PAIR+NSP:這種方式和 BERT 中用到的原始輸入格式相同,NSP 是 Next Sentence Prediction(下一句預測)結構的縮寫。
- SENTENCE-PAIR+NSP:每個輸入包含一對自然語言句子,采樣自一個文檔的連續部分或不同文檔。
- FULL-SENTENCES:每個輸入都包含從一或多個文檔中連續采樣的完整句子,以保證總長度至多 512 token。
- DOC-SENTENCES:這種輸入的構造與 FULL-SENTENCES 類似,只是它們可能不會跨過文檔邊界。
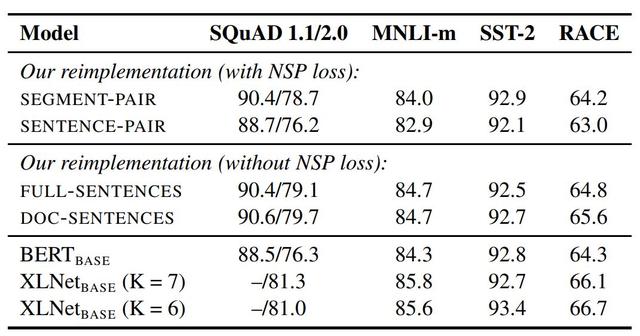
表 2:在 BOOKCORPUS 和 WIKIPEDIA 上預訓練的基礎模型的開發集結果。所有的模型都訓練 1M 步,batch 大小為 256 個序列。
3. 大批量訓練
神經機器翻譯領域之前的工作表明,在學習率適當提高時,以非常大的 mini-batch 進行訓練可以同時提升優化速度和終端任務性能。最近的研究表明,BERT 也能適應大批量訓練。
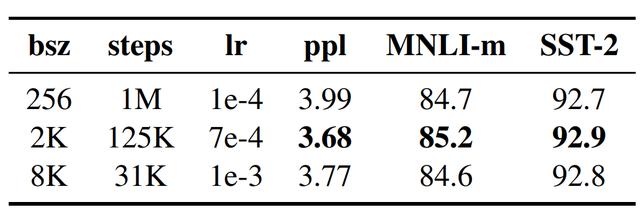
表 3:在 BOOKCORPUS 和 WIKIPEDIA 上用不同的 batch 大小(bsz)訓練的基礎模型在留出訓練數據(ppl)和開發集上的困惑度。
4. 文本編碼
Byte-Pair Encoding(BPE)是字符級和詞級別表征的混合,支持處理自然語言語料庫中的眾多常見詞匯。
原版的 BERT 實現使用字符級別的 BPE 詞匯,大小為 30K,是在利用啟發式分詞規則對輸入進行預處理之后學得的。Facebook 研究者沒有采用這種方式,而是考慮用更大的 byte 級別 BPE 詞匯表來訓練 BERT,這一詞匯表包含 50K 的 subword 單元,且沒有對輸入作任何額外的預處理或分詞。這種做法分別為 BERTBASE 和 BERTLARGE 增加了 15M 和 20M 的額外參數量。
實驗結果
Facebook 研究人員綜合所有這些改進,并評估了其影響。結合所有改進后的方法叫作 RoBERTa(Robustly optimized BERT approach)。
為了厘清這些改進與其他建模選擇之前的重要性區別,研究人員首先基于 BERT LARGE 架構訓練 RoBERTa,并做了一系列對照試驗以確定效果。
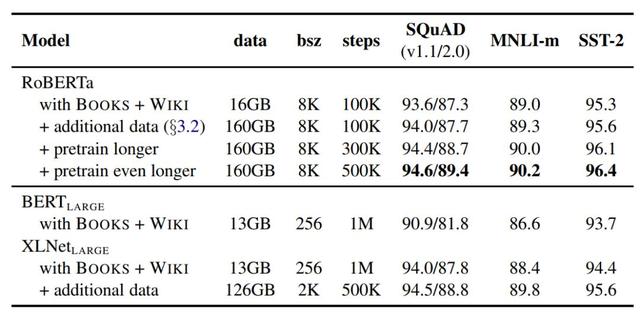
表 4:隨著訓練數據的增大(文本數量從 16GB → 160GB)、訓練步長的增加(100K → 300K → 500K 訓練步),RoBERTa 在開發集上的結果。在對照試驗中,表格中每一行都累積了前幾行的改進。
對于 GLUE,研究人員考慮了兩種微調設置。在第一種設置中(單任務、開發集),研究人員分別針對每一項 GLUE 任務微調 RoBERTa,僅使用對應任務的訓練數據。在第二種設置中(集成,測試集),研究人員通過 GLUE 排行榜對比 RoBERTa 和其他方法。
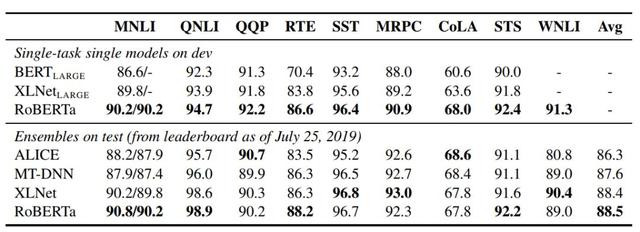
表 5:多個模型在 GLUE 上的結果。所有結果都基于 24 層的模型架構。























