谷歌全球大規模宕機4小時,蘋果iCloud也遭殃!
最近,云服務廠商風波不斷!前有亞馬遜 AWS 電纜被挖,今又有谷歌多項服務發生宕機!
6 月 3 日,據外媒報道,谷歌云服務剛剛發生大規模宕機,影響了包括北美、英國、歐洲、南美等全球多地的谷歌服務。
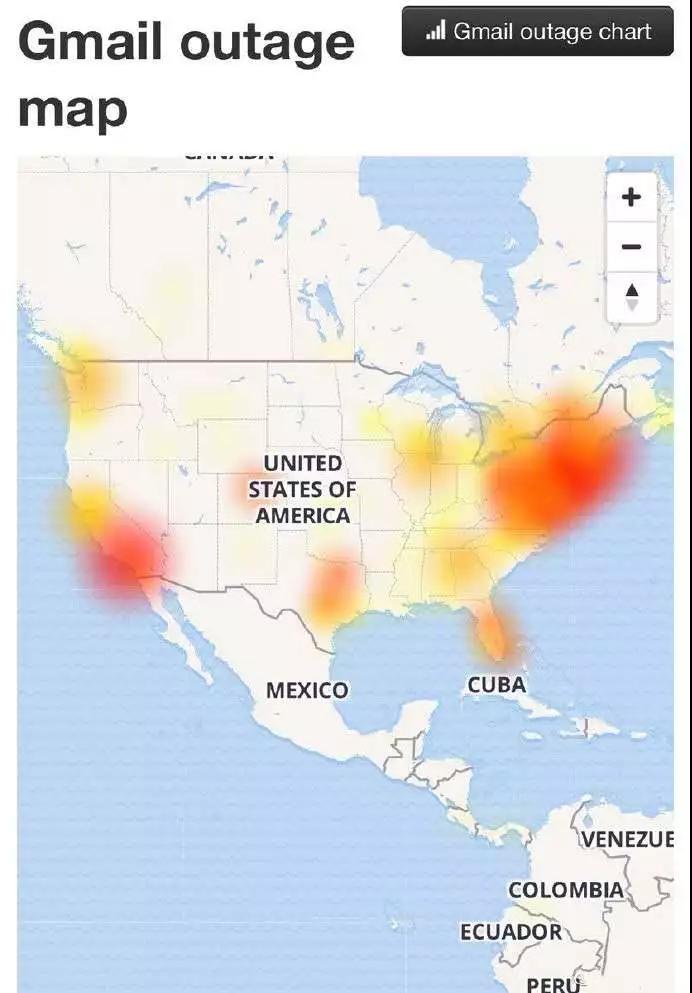
美國東海岸用戶率先報告了這個問題,但宕機監控器 DownDetector 的報告表明,可能有更多地區受此影響。
此次谷歌云服務斷線影響了諸多谷歌旗下網站與 App 的運行,包括世界***的郵件應用 Gmail、世界***視頻網站 YouTube 與免費辦公套件 G Suite。
此外包括 Discord 和 Snapchat 等依賴谷歌云服務的第三方 App 也受到了影響。
谷歌對此發表了緊急聲明:“我們在美國東部遇到了嚴重的網絡擁塞,影響了 Google Cloud,G Suite 和 YouTube 中的多項服務。用戶可能會感受到打開卡頓或間歇性報錯,我們會盡快恢復正常服務。”
該網絡問題疑似和 Level 3 公司有關,這是美國一家 ISP 服務商,為谷歌數據中心提供網絡服務。
故障三小時后,大部分問題修復,四小時后,谷歌聲稱修復全部問題。
有意思的是,蘋果公司也受到了此次宕機的影響。
據蘋果公司稱,其 iCloud 的許多產品今天下午都出現了問題。蘋果表示,云中的 iCloud Mail、iCloud Drive、iMessage、照片和文檔等功能的運行速度比用戶預期的要慢。
去年,蘋果公司證實,它使用谷歌云作為其部分 iCloud 產品的主干。該公司表示,存儲在谷歌上的數據包括聯系人、日歷、照片、視頻、文檔等。這與今天受停電影響的服務是一致的。除了谷歌云,蘋果還使用了亞馬遜的 S3 平臺。
這兩年,各大云服務商發生的宕機事件越來越頻繁,這對很多的企業造成的是直接性的利益受損!
云服務宕機大事件
①2018 年 11 月 9 日
谷歌公有云下的 Kubernetes 服務(GKE)宕機。
②2019 年 3 月 2 日
阿里云開始出現大規模故障,這場事故持續了三個小時左右,事后觀察了兩個小時。
③2019 年 3 月 12 日
3 月 12 日全球各地的谷歌云用戶反映使用 Gmail、YouTube、Google Drive、谷歌音樂與谷歌的其他服務時都遇到了問題,谷歌隨后承認出現故障,谷歌云平臺狀態頁面(Google Cloud Status Dashboard)顯示,此次故障影響了谷歌云存儲的所有區域。
④2019 年 3 月 13 日
3 月 13 日,全球***的社交網絡 Facebook 及其旗下 Instagram 和 WhatsApp 的服務器均出現故障。部分服務器故障時間長達 24 小時,這是 Facebook 公司近期遭遇的史上最長宕機。
就連前兩天,AWS 國內也出現數小時網絡中斷。

AWS 官方聲明中稱,由于 6 月 1 日晚間 CN-NORTH-1 地區的隔夜道路施工中有幾處光纜被切斷,導致可用區無法鏈接 Internet,進而引發所有可用區中新的實例無法啟動的故障。
“多云”部署或成為新的保障
目前越來越多的企業將其業務系統、數據部署在云上,云服務器一旦宕機,企業業務必然會受波及,因此安全被各企業視為頭等要務。
可靠性和業務連續性一直是電信業非常重視的指標,而云廠商對于服務可靠性的要求還不夠。
未來云服務或將像水電煤一樣成為基礎設施。停電 1 分鐘,對于一般家庭而言,也許只意味著少看一會兒電視、少吹一會兒空調,但對于企業而言,或許意味著一條生產線的癱瘓、整個生產流程的推倒重來。
同理,云服務器宕機 1 分鐘,對于云服務提供商來說是一次運維故障,但對企業而言,或許意味著客戶的流失甚至破產,特別是不可逆的故障不是云服務提供商賠償就能挽回的。
以下是預防宕機發生的多個方面:
①云廠商技術上的完善
云廠商技術上的完善,即增強云服務的可靠性和業務連續性,但毋庸置疑的是無論可靠性達到幾個 9 都無法保證云服務“永不宕機”。
②根據自身特點選擇云災備和云保險服務
盡量在經濟和人員條件可行的情況下使用這些分散風險,如果故障只出現在一個服務器集群,如果采用異地災備的方案,就可以在最快時間切換到另一個集群下,保持系統可用;云保險則是企業的***一道保障。
③增強用云規范意識
為避免由于人員的誤操作或者相關人員操作不規范造成的宕機事故,相關企業和政府機構應加強技術人員的培訓和災備意識的建立。
企業的 IT 人員日常應做到異機備份、數據容災、業務雙活、定期對災備和雙活進行演練等,盡可能避免云故障帶來的損失。