TensorFlow官方發布剪枝優化工具:參數減少80%,精度幾乎不變
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
去年TensorFlow官方推出了模型優化工具,最多能將模型尺寸減小4倍,運行速度提高3倍。
最近現又有一款新工具加入模型優化“豪華套餐”,這就是基于Keras的剪枝優化工具。
訓練AI模型有時需要大量硬件資源,但不是每個人都有4個GPU的豪華配置,剪枝優化可以幫你縮小模型尺寸,以較小的代價進行推理。
什么是權重剪枝?
權重剪枝(Weight Pruning)優化,就是消除權重張量中不必要的值,減少神經網絡層之間的連接數量,減少計算中涉及的參數,從而降低操作次數。
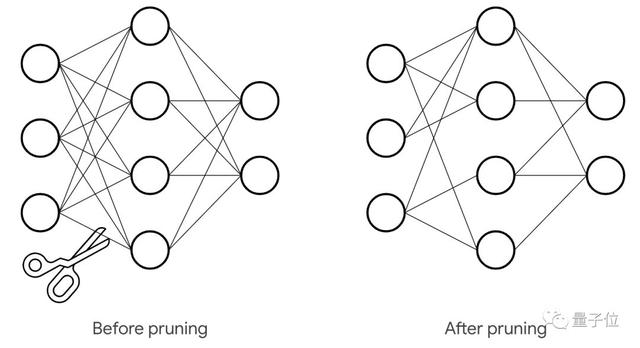
這樣做的好處是壓縮了網絡的存儲空間,尤其是稀疏張量特別適合壓縮。例如,經過處理可以將MNIST的90%稀疏度模型從12MB壓縮到2MB。
此外,權重剪枝與量化(quantization)兼容,從而產生復合效益。通過訓練后量化(post-training quantization),還能將剪枝后的模型從2MB進一步壓縮到僅0.5MB 。
TensorFlow官方承諾,將來TensorFlow Lite會增加對稀疏表示和計算的支持,從而擴展運行內存的壓縮優勢,并釋放性能提升。
優化效果
權重剪枝優化可以用于不同任務、不同類型的模型,從圖像處理的CNN用于語音處理的RNN。下表顯示了其中一些實驗結果。
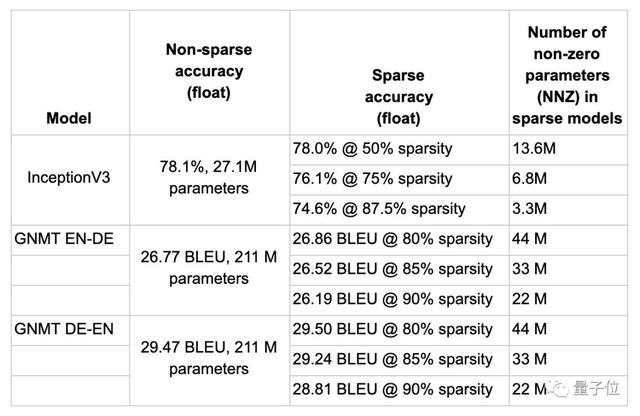
以GNMT從德語翻譯到英語的模型為例,原模型的BLEU為29.47。指定80%的稀疏度,經優化后,張量中的非零參數可以從211M壓縮到44M,準確度基本沒有損失。
使用方法
現在的權重剪枝API建立在Keras之上,因此開發者可以非常方便地將此技術應用于任何現有的Keras訓練模型中。
開發者可以指定最終目標稀疏度(比如50%),以及執行剪枝的計劃(比如2000步開始剪枝,在4000步時停止,并且每100步進行一次),以及剪枝結構的可選配置。
- import tensorflow_model_optimization as tfmot
- model = build_your_model()
- pruning_schedule = tfmot.sparsity.keras.PolynomialDecay(
- initial_sparsity=0.0, final_sparsity=0.5,
- begin_step=2000, end_step=4000)
- model_for_pruning = tfmot.sparsity.keras.prune_low_magnitude(model, pruning_schedule=pruning_schedule)
- ...
- model_for_pruning.fit
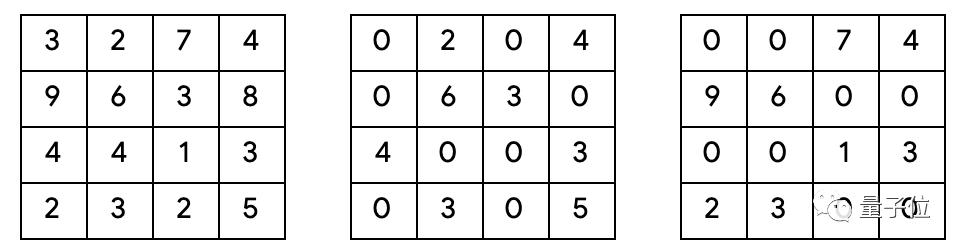
△ 三個不同張量,左邊的沒有稀疏度,中心的有多個單獨0值,右邊的有1x2的稀疏塊。
隨著訓練的進行,剪枝過程開始被執行。在這個過程中,它會消除消除張量中最接近零的權重,直到達到當前稀疏度目標。
每次計劃執行剪枝程序時,都會重新計算當前稀疏度目標,根據平滑上升函數逐漸增加稀疏度來達到最終目標稀疏度,從0%開始直到結束。
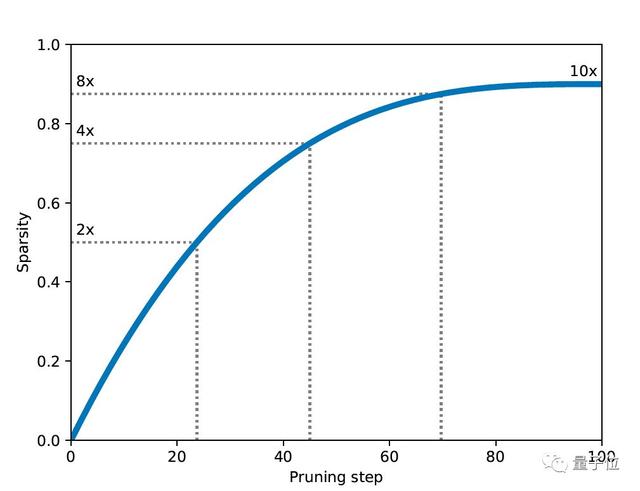
用戶也可以根據需要調整這個上升函數。在某些情況下,可以安排訓練過程在某個步驟達到一定收斂級別之后才開始優化,或者在訓練總步數之前結束剪枝,以便在達到最終目標稀疏度時進一步微調系統。
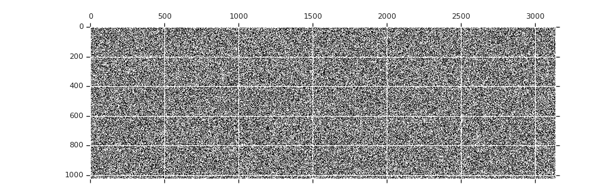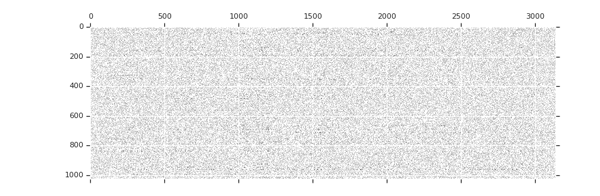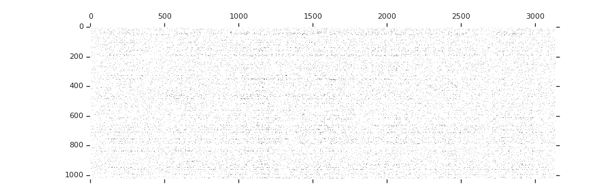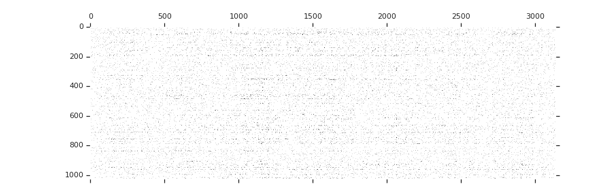
△權重張量剪枝動畫,黑色的點表示非零權重,隨著訓練的進行,稀疏度逐漸增加
GitHub地址:
https://github.com/tensorflow/model-optimization
官方教程:
https://www.tensorflow.org/model_optimization/guide/pruning/pruning_with_keras