













EfficientViT-SAM:精度不變原地起飛!

作者提出了EfficientViT-SAM,這是一系列加速的SAM模型。在保留SAM輕量級的提示編碼器和 Mask 解碼器的同時,作者用EfficientViT替換了沉重的圖像編碼器。在訓練方面,首先從SAM-ViT-H圖像編碼器向EfficientViT進行知識蒸餾。隨后,在SA-1B數據集上進行端到端的訓練。得益于EfficientViT的高效性和容量,EfficientViT-SAM在A100 GPU上實現了48.9的TensorRT速度提升,而且沒有犧牲性能。
代碼和預訓練:https://github.com/mit-han-lab/efficientvit
1 Introduction
Segment Anything Model (SAM) 是一系列在高質量數據集上預訓練的圖像分割模型,該數據集包含1100萬張圖片和10億個 Mask 。SAM 提供了驚人的零樣本圖像分割性能,并在許多應用中都有用途,包括增強現實/虛擬現實、數據標注、交互式圖像編輯等。
盡管性能強大,但SAM的計算量非常大,這在時間敏感的情境中限制了其適用性。特別是,SAM的主要計算瓶頸在于其圖像編碼器,在推理時每張圖像需要2973 GMACs。
為了加速SAM,已經進行了許多嘗試,用輕量級模型替換SAM的圖像編碼器。例如,MobileSAM 將SAM的ViT-H模型的知識蒸餾到一個小型視覺 Transformer 中。EdgeSAM 訓練了一個純基于CNN的模型來模仿ViT-H,并采用了一種細致的蒸餾策略,過程中涉及到提示編碼器和 Mask 解碼器。EfficientSAM 利用MAE預訓練方法來提高性能。
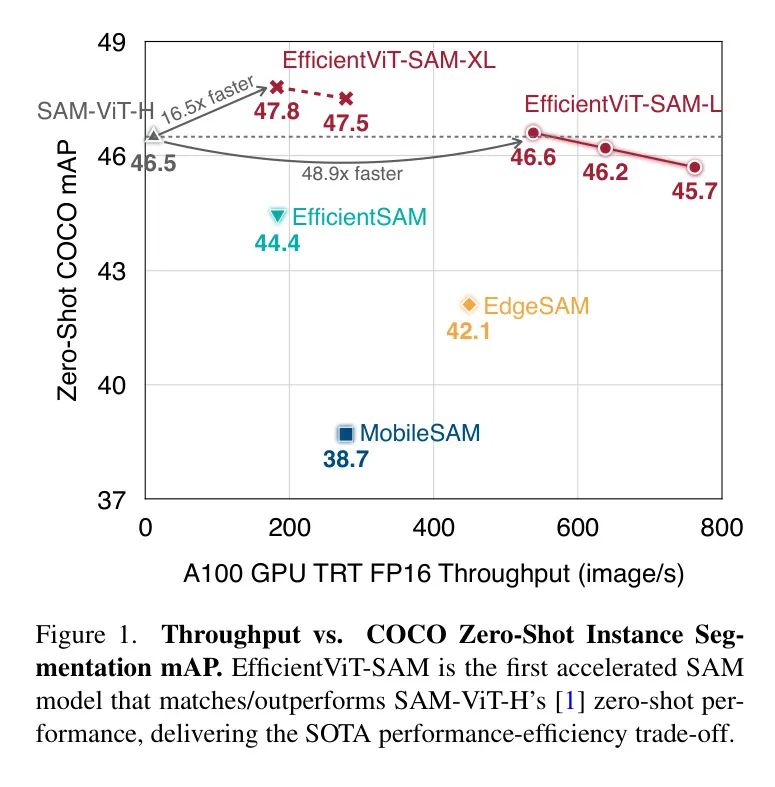
盡管這些方法可以降低計算成本,但它們都存在顯著的性能下降(圖1)。本文引入了EfficientViT-SAM來解決這一限制,通過利用EfficientViT來替換SAM的圖像編碼器。同時,作者保留了SAM的輕量級提示編碼器和 Mask 解碼器架構。作者的訓練過程包括兩個階段。首先,作者使用SAM的圖像編碼器作為教師來訓練EfficientViT-SAM的圖像編碼器。其次,作者使用整個SA-1B數據集端到端地訓練EfficientViT-SAM。
作者全面評估了EfficientViT-SAM在一系列零樣本基準測試上的表現。EfficientViT-SAM在性能和效率上顯著優于所有之前的SAM模型。特別是,在COCO數據集上,與SAM-ViT-H相比,EfficientViT-SAM在A100 GPU上實現了48.9倍的吞吐量提升,而mAP沒有下降。
2 Related Work
Segment Anything Model
SAM 在計算機視覺領域已經獲得廣泛認可,作為該領域的一個里程碑,它在圖像分割方面展示了卓越的性能和泛化能力。SAM 將圖像分割定義為可提示的任務,旨在給定任何分割提示時生成有效的分割 Mask 。為了實現這一目標,SAM 使用圖像編碼器和提示編碼器來處理圖像并提供提示。兩個編碼器的輸出隨后被送入 Mask 解碼器,該解碼器生成最終的 Mask 預測。
SAM 在一個大規模的分割數據集上進行訓練,該數據集包含超過1100萬張圖像和超過10億個高質量 Mask ,這使得它能夠在零樣本開放世界分割中表現出強大的能力。SAM 在各種下游應用中展示了其高度的適應性,包括圖像修復、目標跟蹤和3D生成。然而,SAM的圖像編碼器組件帶來了顯著的計算成本,導致高延遲,限制了在時間敏感場景中的實用性。最近的工作集中在提高SAM的效率,旨在解決其計算限制。
Efficient Deep Learning Computing
提高深度神經網絡的效率在邊緣和云計算平臺上的實際應用中至關重要。作者的工作與有效的模型架構設計相關,旨在通過用高效的模型架構替換低效的模型架構來改善性能與效率之間的權衡。作者的工作還與知識蒸餾相關,該方法利用預訓練的教師模型指導學生模型的訓練。此外,作者可以將EfficientViT-SAM與其他并行技術結合,以進一步提高效率,包括剪枝、量化和硬件感知神經架構搜索。
3 Method
作者提出了EfficientViT-SAM,該方法利用EfficientViT來加速SAM。特別是,EfficientViT-SAM保留了SAM的提示編碼器和 Mask 解碼器架構,同時用EfficientViT替換了圖像編碼器。作者設計了兩系列模型,EfficientViT-SAM-L和EfficientViT-SAM-XL,它們在速度和性能之間提供了平衡。隨后,作者以端到端的方式使用SA-1B數據集來訓練EfficientViT-SAM。
EfficientViT
EfficientViT 是一系列用于高效高分辨率密集預測的視覺 Transformer 模型。其核心構建模塊是一個多尺度線性注意力模塊,它通過硬件高效的運算實現了全局感受野和多尺度學習。
具體來說,它用輕量級的ReLU線性注意力替代了效率低下的softmax注意力,以擁有全局感受野。通過利用矩陣乘法的結合性質,ReLU線性注意力可以在保持功能的同時,將計算復雜度從二次降低到一次。此外,它還通過卷積增強了ReLU線性注意力,以減輕其在局部特征提取上的局限性。更多細節可在原論文中找到。
EfficientViT-SAM
模型架構。EfficientViT-SAM-XL的宏觀架構如圖2所示。其主干包含五個階段。類似于EfficientViT,作者在早期階段使用卷積塊,而在最后兩個階段使用efficientViT模塊。作者通過上采樣和加法融合最后三個階段的特征。融合后的特征被送入由幾個融合的MBConv塊組成的 Neck ,然后送入SAM Head 。

訓練。為了初始化圖像編碼器,作者首先將SAM-ViT-H的圖像嵌入信息蒸餾到EfficientViT中。作者采用L2損失作為損失函數。對于提示編碼器和 Mask 解碼器,作者通過加載SAM-ViT-H的權重來初始化它們。然后,作者以端到端的方式在SA-1B數據集上訓練EfficientViT-SAM。
在端到端的訓練階段,作者以相等的概率隨機選擇框提示和點提示。在點提示的情況下,作者從真實 Mask 中隨機選擇1-10個前景點,以確保作者的模型能夠有效應對各種點配置。在框提示的情況下,作者使用真實邊界框。對于EfficientViT-SAM-L/XL模型,作者將最長邊調整至512/1024,并相應地填充較短邊。作者每張圖像選擇多達64個隨機采樣的 Mask 。
為了監督訓練過程,作者使用Focal Loss和骰子損失的線性組合,Focal Loss與骰子損失的比例為20:1。類似于SAM中采用的消除歧義的方法,作者同時預測三個 Mask ,并且只反向傳播損失最低的那個。作者還通過添加第四個輸出Token來支持單一 Mask 的輸出。在訓練期間,作者隨機交替使用兩種預測模式。
作者使用SA-1B數據集對EfficientViT-SAM進行了2個周期的訓練,批量大小為256。采用AdamW優化器,動量參數設為0.9,設為0.999。初始學習率對于EfficientViT-SAM-L/XL分別設定為2e/1e,并使用余弦衰減學習率計劃將其降低至0。在數據增強方面,作者應用了隨機水平翻轉。
4 Experiment
在本節中,作者在4.1節中對EfficientViT-SAM的運行時效率進行了全面分析。隨后,作者在COCO 和 LVIS 數據集上評估了EfficientViT-SAM的零樣本能力,這些數據集在訓練過程中未曾遇到。作者執行了兩項不同的任務:4.2節中的單點有效 Mask 評估以及4.3節中的邊界框提示實例分割。這些任務分別評估了EfficientViT-SAM的點提示和邊界框提示特征的有效性。此外,作者在4.4節還提供了SGlnW基準測試的結果。
Runtime Efficiency
作者比較了EfficientViT-SAM與SAM及其他加速工作的模型參數、MACs和吞吐量。結果展示在表1中。作者在單個NVIDIA A100 GPU上進行了吞吐量的測量,并使用了TensorRT優化。
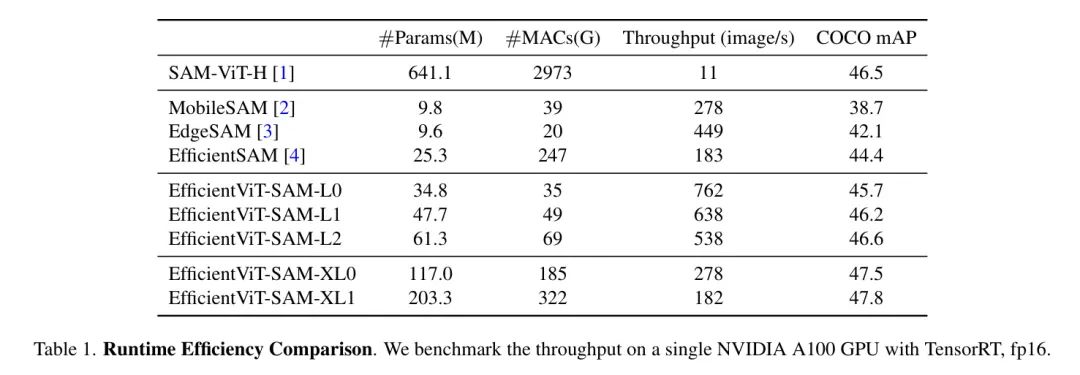
作者的結果顯示,與SAM相比,作者實現了令人印象深刻的17到69倍的加速。此外,盡管EfficientViT-SAM的參數數量多于其他加速工作,但由于其有效地利用了硬件友好的運算符,因此其吞吐量顯著提高。
Zero-Shot Point-Prompted Segmentation
作者在表2中評估了基于點提示對目標進行分割時EfficientViT-SAM的零樣本性能。作者采用了文獻[1]中描述的點選擇方法。即初始點被選為距離目標邊界最遠的點。后續的每個點都選為距離錯誤區域邊界最遠的點,該錯誤區域被定義為真實值和先前預測之間的區域。
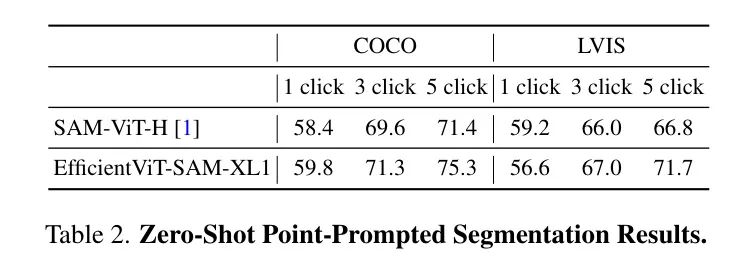
作者在COCO和LVIS數據集上使用1/3/5次點擊報告性能,以mIoU(平均交并比)作為評價指標。作者的結果顯示,與SAM相比,性能更優,尤其是在提供額外點提示時。
Zero-Shot Box-Prompted Segmentation
作者評估了EfficientViT-SAM在利用邊界框進行目標分割中的零樣本性能。首先,作者將真實邊界框輸入到模型中,結果展示在表4中。
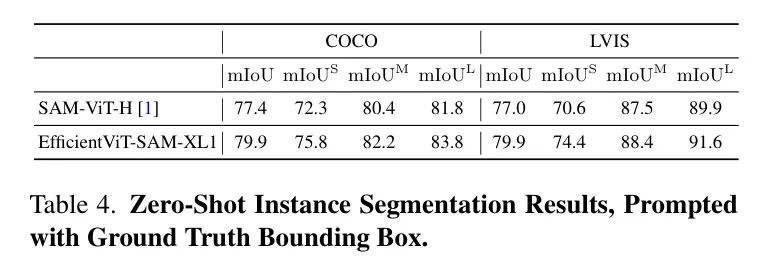
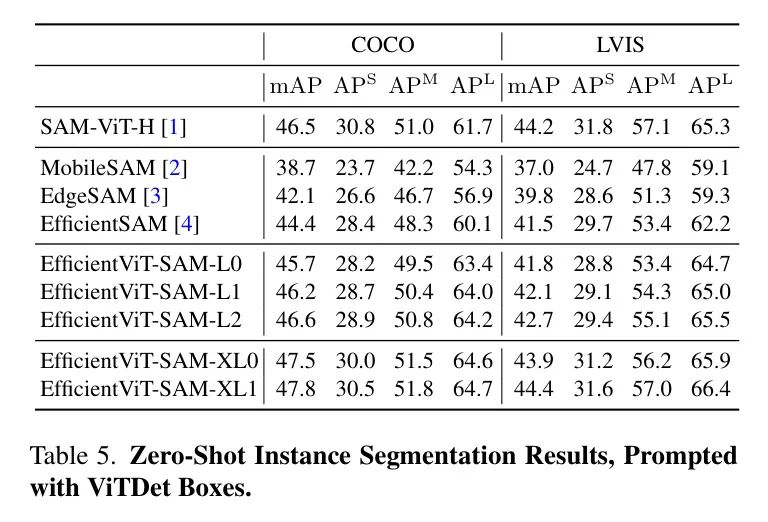
所有目標都報告了mIoU(平均交并比),并且分別為小型、中型和大型目標分別報告。EfficientViT-SAM在COCO和LVIS數據集上顯著超過了SAM。接下來,作者采用一個目標檢測器ViT-Det,并使用其輸出框作為模型的提示。表5的結果顯示,EfficientViT-SAM相比于SAM取得了更優的性能。值得注意的是,即使是EfficientViT-SAM的最輕版本,也顯著優于其他加速工作。
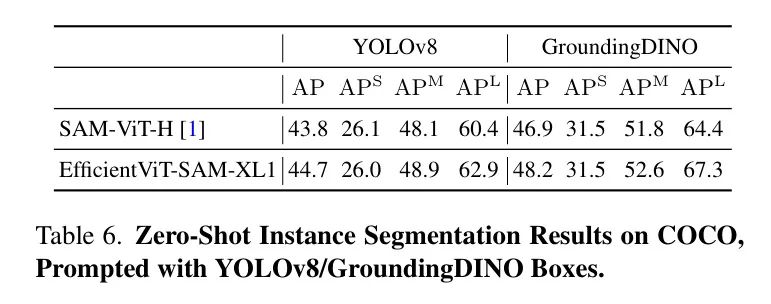
另外,作者使用YOLOv8和GroundingDINO 作為目標檢測器,在COCO數據集上評估了EfficientViT-SAM的性能。YOLOv8是一種實時目標檢測器,適用于實際應用場景。另一方面,GroundingDINO能夠使用文本提示來檢測目標,這使得作者可以基于文本線索進行目標分割。表6中展示的結果表明,EfficientViT-SAM相比于SAM具有卓越的性能。
Zero-Shot In-the-Wild Segmentation
野外分割基準包含25個零樣本野外分割數據集。作者將EfficientViT-SAM與Grounding-DINO結合,作為框提示,執行零樣本分割。每個數據集的全面性能結果在表3中展示。SAM達到48.7的mAP,而EfficientViT-SAM獲得了更高的48.9分。
Qualitative Results.
圖3展示了當提供點提示、框提示以及SAM模式時,EfficientViT-SAM的定性分割結果。結果顯示,EfficientViT-SAM不僅在分割大型物體上表現出色,也能有效處理小型物體。這些發現強調了EfficientViT-SAM卓越的分割能力。

5 Conclusion
在這項工作中,作者引入了EfficientViT-SAM,它使用EfficientViT來替代SAM的圖像編碼器。EfficientViT-SAM在無需犧牲各種零樣本分割任務性能的情況下,顯著提高了SAM的效率。






















