AutoML、AutoKeras......這四個(gè)「Auto」的自動(dòng)機(jī)器學(xué)習(xí)方法你分得清嗎?
讓我們先來(lái)看一個(gè)簡(jiǎn)短的童話故事…
從前,有一個(gè)魔法師,他使用一種無(wú)人再使用的編程語(yǔ)言,在一種無(wú)人再使用的框架下訓(xùn)練模型。一天,一位老人找到他,讓他為一個(gè)神秘的數(shù)據(jù)集訓(xùn)練一個(gè)模型。
這位魔法師孜孜不倦,嘗試了數(shù)千種不同的方式訓(xùn)練這個(gè)模型,但很不幸,都沒(méi)有成功。于是,他走進(jìn)了他的魔法圖書館尋找解決辦法。突然,他發(fā)現(xiàn)了一本關(guān)于一種神奇法術(shù)的書。這種法術(shù)可以把他送到一個(gè)隱藏的空間,在那里,他無(wú)所不知,他可以嘗試每一種可能的模型,能完成每一種優(yōu)化技術(shù)。他毫不猶豫地施展了這個(gè)法術(shù),被送到了那個(gè)神秘的空間。自那以后,他明白了如何才能得到更好的模型,并采用了那種做法。在回來(lái)之前,他無(wú)法抗拒將所有這些力量帶走的誘惑,所以他把這個(gè)空間的所有智慧都賜予了一塊名為「Auto」的石頭,這才踏上了返程的旅途。
從前,有個(gè)擁有「Auto」魔石的魔法師。傳說(shuō),誰(shuí)掌握了這塊魔法石的力量,誰(shuí)就能訓(xùn)練出任何想要的模型。
哈利波特與死亡圣器
這樣的故事太可怕了,不是嗎?我不知道這個(gè)故事是不是真的,但在現(xiàn)代,機(jī)器學(xué)習(xí)領(lǐng)域的頭號(hào)玩家們似乎很有興趣將這樣的故事變成現(xiàn)實(shí)(可能會(huì)略有改動(dòng))。在這篇文章中,我將分享哪些設(shè)想是可以實(shí)現(xiàn)的,并幫助你直觀地理解它們的設(shè)計(jì)理念(盡管所有工具的名字中都有「auto」這個(gè)詞,但它們之間似乎并沒(méi)有共同之處)。
動(dòng)機(jī)——人生艱難
在給定的數(shù)據(jù)集中實(shí)現(xiàn)當(dāng)前***模型性能通常要求使用者認(rèn)真選擇合適的數(shù)據(jù)預(yù)處理任務(wù),挑選恰當(dāng)?shù)乃惴ā⒛P秃图軜?gòu),并將其與合適的參數(shù)集匹配。這個(gè)端到端的過(guò)程通常被稱為機(jī)器學(xué)習(xí)工作流(Machine Learning Pipeline)。沒(méi)有經(jīng)驗(yàn)法則會(huì)告訴我們?cè)撏膫€(gè)方向前進(jìn),隨著越來(lái)越多的模型不斷被開(kāi)發(fā)出來(lái),即使是選擇正確的模型這樣的工作也變得越來(lái)越困難。超參數(shù)調(diào)優(yōu)通常需要遍歷所有可能的值或?qū)ζ溥M(jìn)行抽樣、嘗試。然而,這樣做也不能保證一定能找到有用的東西。在這種情況下,自動(dòng)選擇和優(yōu)化機(jī)器學(xué)習(xí)工作流一直是機(jī)器學(xué)習(xí)研究社區(qū)的目標(biāo)之一。這種任務(wù)通常被稱為「元學(xué)習(xí)」,它指的是學(xué)習(xí)關(guān)于學(xué)習(xí)的知識(shí)。
AZURE 的自動(dòng)化機(jī)器學(xué)習(xí)(試用版)
- 開(kāi)源與否:否
- 是否基于云平臺(tái):是(可以完成任何計(jì)算目標(biāo)的模型的評(píng)價(jià)和訓(xùn)練)
- 支持的模型類別:分類、回歸
- 使用的技術(shù):概率矩陣分解+貝葉斯優(yōu)化
- 訓(xùn)練框架: sklearn
這種方法的理念是,如果兩個(gè)數(shù)據(jù)集在一些工作流中能得到類似的(即相關(guān)的)結(jié)果,那么它們?cè)谄渌墓ぷ髁髦锌赡芤矔?huì)產(chǎn)生類似的結(jié)果。這聽(tīng)起來(lái)可能似曾相識(shí)。如果你以前處理過(guò)推薦系統(tǒng)的協(xié)同過(guò)濾問(wèn)題,你就知道「如果兩個(gè)用戶過(guò)去喜歡相同的項(xiàng)目,那么將來(lái)他們喜歡相似項(xiàng)目的可能性就會(huì)更大」。
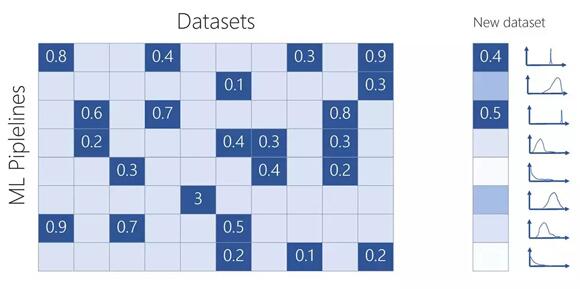
由工作流 P 和數(shù)據(jù)集 D 組成的輸入矩陣的可視化。數(shù)字對(duì)應(yīng)于數(shù)據(jù)集 D 在工作流 P 上得到的平衡均值。
要解決這個(gè)問(wèn)題意味著兩件事:學(xué)習(xí)一種隱藏的表示方法來(lái)捕獲不同數(shù)據(jù)集和不同機(jī)器學(xué)習(xí)工作流之間的關(guān)系,以預(yù)測(cè)某工作流在給定數(shù)據(jù)集上能夠獲得的準(zhǔn)確率;學(xué)習(xí)一種函數(shù),能夠成功地告訴你下一步應(yīng)該嘗試哪個(gè)工作流。***個(gè)任務(wù)是通過(guò)創(chuàng)建一個(gè)平衡后的準(zhǔn)確率組成的矩陣來(lái)完成的,不同的工作流可以應(yīng)對(duì)不同的數(shù)據(jù)集。論文《Probabilistic Matrix Factorization for Automated Machine Learning》描述了該方法,詳細(xì)說(shuō)明了他們?cè)诔^(guò) 600 個(gè)數(shù)據(jù)集上嘗試的 42,000 個(gè)不同的機(jī)器學(xué)習(xí)工作流。也許這與你今天在 Azure 的試用版中看到的是不同的,但它可以為你提供一種思路。作者指出,隱藏表征不僅成功地捕獲了關(guān)于模型的信息,而且成功地捕獲了關(guān)于超參數(shù)和數(shù)據(jù)集特征的信息(注意,這個(gè)學(xué)習(xí)過(guò)程是以無(wú)監(jiān)督的方式進(jìn)行的)。
目前所描述的模型可以作為已經(jīng)評(píng)估的工作流的函數(shù)來(lái)預(yù)測(cè)每個(gè)機(jī)器學(xué)習(xí)工作流的預(yù)期性能,但是還沒(méi)有對(duì)下一步應(yīng)該嘗試哪個(gè)工作流給出任何指導(dǎo)。由于他們使用的是矩陣分解的概率版本,該方法可以生成關(guān)于工作流性能的預(yù)測(cè)后驗(yàn)分布,從而允許我們使用采集函數(shù)(貝葉斯優(yōu)化)來(lái)指導(dǎo)對(duì)機(jī)器學(xué)習(xí)工作流空間的探索。基本上,該方法可以選擇出下一個(gè)可以***化預(yù)期的準(zhǔn)確率提升的工作流。
然而,推薦系統(tǒng)飽受一個(gè)非常特殊的問(wèn)題的困擾:冷啟動(dòng)。如果一個(gè)新的數(shù)據(jù)集出現(xiàn)在系統(tǒng)中(也就是你的數(shù)據(jù)集),那么模型無(wú)從知曉這個(gè)新的數(shù)據(jù)集與什么相似。為了解決冷啟動(dòng)問(wèn)題,我們可以從數(shù)據(jù)集中計(jì)算出一些元特征,以捕獲觀測(cè)次數(shù)、分類的類別數(shù)、值的范圍等特征。然后通過(guò)這些指標(biāo)在已知數(shù)據(jù)集的空間中確定出一個(gè)封閉的數(shù)據(jù)集。他們?cè)诓煌墓ぷ髁魃蠂L試了 5次,直到開(kāi)始使用采集函數(shù)來(lái)通知自動(dòng)機(jī)器學(xué)習(xí)系統(tǒng)接下來(lái)要嘗試的數(shù)據(jù)集。注意,這個(gè)方法不需要訪問(wèn)實(shí)際的數(shù)據(jù)集,只需要訪問(wèn)本地計(jì)算出的元特性(這大大減小了開(kāi)銷)。
谷歌的 AUTOML(測(cè)試版)
- 開(kāi)源與否:否
- 是否基于云平臺(tái):是(訓(xùn)練和評(píng)價(jià))
- 支持的模型類別:用于分類的卷積神經(jīng)網(wǎng)絡(luò)(CNN)、循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)、長(zhǎng)短期記憶網(wǎng)絡(luò)(LSTM)
- 使用的技術(shù):帶梯度策略更新的強(qiáng)化學(xué)習(xí)
- 訓(xùn)練框架:TensorFlow
說(shuō)到神經(jīng)網(wǎng)絡(luò),最近***進(jìn)的模型的成功離不開(kāi)從功能設(shè)計(jì)到架構(gòu)設(shè)計(jì)的范式轉(zhuǎn)換。也就是說(shuō),構(gòu)建能夠以無(wú)監(jiān)督的方式從數(shù)據(jù)中學(xué)習(xí)***表征的機(jī)器學(xué)習(xí)架構(gòu),而不是直接設(shè)計(jì)這樣的特性(這是復(fù)雜的,需要大量關(guān)于數(shù)據(jù)的先驗(yàn)知識(shí))。然而,設(shè)計(jì)架構(gòu)仍然需要大量的知識(shí)和時(shí)間。谷歌 AutoML 的解決思路是創(chuàng)建一個(gè)元模型,該模型能夠?qū)W習(xí)一種方法,為子模型設(shè)計(jì)和生成能夠在感興趣的數(shù)據(jù)集上取得良好性能的架構(gòu)。
他們使用實(shí)現(xiàn)為 RNN 的神經(jīng)架構(gòu)搜索,生成編碼為長(zhǎng)度可變token序列(「字符串」的一種精妙表達(dá)方式)的架構(gòu)。
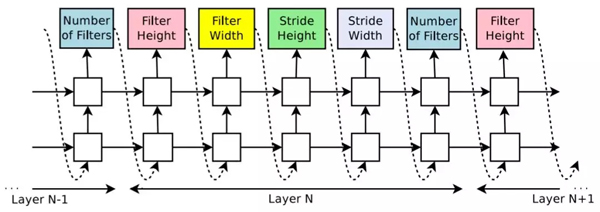
使用該方法生成的 CNN 的編碼。每個(gè)顏色框?qū)?yīng)于RNN生成的建議體系架構(gòu)的一個(gè)參數(shù)(或token)。
一旦生成了一個(gè)架構(gòu),就會(huì)構(gòu)建并訓(xùn)練所提出的模型,最終記錄所獲得的精度。RNN經(jīng)過(guò)訓(xùn)練,使用了強(qiáng)化學(xué)習(xí)策略,該策略更新了RNN的參數(shù),以便隨著時(shí)間的推移生成更好的架構(gòu)。
生成的token序列可以看作是生成架構(gòu)時(shí)應(yīng)該執(zhí)行的動(dòng)作(action)序列。該模型最終會(huì)得到一個(gè)數(shù)據(jù)集上的準(zhǔn)確率 R,我們可以考慮將 R 作為獎(jiǎng)勵(lì)信號(hào)與強(qiáng)化學(xué)習(xí)算法一起訓(xùn)練 RNN。然而,這樣的獎(jiǎng)勵(lì)是不可微的,這就是為什么他們建議通過(guò)一些改進(jìn)措施,使用策略梯度方法迭代更新參數(shù)(如Williams 等人在 1992 所提出的方法)。由于訓(xùn)練過(guò)程非常耗時(shí),他們使用分布式訓(xùn)練和異步參數(shù)更新來(lái)加速學(xué)習(xí)過(guò)程,如 Dean 等人在 2012 發(fā)表的論文中提出的方法。
它能生成什么樣的模型?根據(jù)谷歌大腦發(fā)表的相關(guān)論文《NEURALARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING》,在卷積架構(gòu)方面,他們將修正過(guò)的線性單元用于非線性模型(Nair & Hinton, 2010)、批量歸一化(Ioffe &Szegedy, 2015)和跳躍連接(Szegedy et al., 2015 and He et al.,2016a)。對(duì)于每個(gè)卷積層,它可以在 [1,3,5,7] 中選擇一個(gè)濾波器高度,在 [1,3,5,7] 中選擇一個(gè)濾波器寬度,在 [24,36,48] 中選擇多個(gè)濾波器。在步長(zhǎng)方面,它必須預(yù)測(cè) [1,2,3] 中的步長(zhǎng)。對(duì)于 RNN 和 LSTM,該架構(gòu)支持在[identity,tanh, sigmoid, relu] 中選擇激活函數(shù)。RNN 神經(jīng)元的輸入對(duì)的數(shù)量(「基數(shù)」)設(shè)置為 8。
AUTOKERAS
- 開(kāi)源與否:是
- 是否基于云平臺(tái):否
- 支持的模型類別:用于分類的卷積神經(jīng)網(wǎng)路(CNN)、循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)、長(zhǎng)短期記憶網(wǎng)絡(luò)(LSTM)
- 使用的技術(shù):高效神經(jīng)架構(gòu)搜索(參見(jiàn)《Efficient NeuralArchitecture Search via Parameter Sharing》)
- 訓(xùn)練框架:Keras
AutoKeras 和谷歌AutoML 的構(gòu)建思路相同:它使用一個(gè)通過(guò)循環(huán)訓(xùn)練的 RNN 控制器,對(duì)候選架構(gòu)(即子模型)進(jìn)行采樣,然后對(duì)其進(jìn)行訓(xùn)練,以測(cè)量其在期望任務(wù)中的性能。接著,控制器使用性能作為指導(dǎo)信號(hào),以找到更有前景的架構(gòu)。然而,我們之前沒(méi)有提到計(jì)算過(guò)程的代價(jià)有多高。實(shí)際上,神經(jīng)架構(gòu)搜索在計(jì)算上非常昂貴、耗時(shí),例如 Zoph 等人在 2018 年發(fā)表的論文使用 450 個(gè) GPU 運(yùn)行了大約 4 萬(wàn)個(gè) GPU 小時(shí)。另一方面,使用更少的資源往往產(chǎn)生傾倒的結(jié)果。為了解決這個(gè)問(wèn)題,AutoKeras使用了高效神經(jīng)架構(gòu)搜索(ENAS)。
ENAS 應(yīng)用了一個(gè)類似于遷移學(xué)習(xí)的概念,其思想是:在特定任務(wù)上為特定模型學(xué)習(xí)的參數(shù)可以用于其他任務(wù)上的其他模型。因此,ENAS 迫使所有生成的子模型共享權(quán)值,從而刻意防止從頭開(kāi)始訓(xùn)練每一個(gè)子模型。這篇論文的作者表明,ENAS 不僅可以在子模型之間共享參數(shù),還能夠獲得非常強(qiáng)的性能。
Auto-sklearn
- 開(kāi)源與否:是
- 是否基于云平臺(tái):否
- 支持的模型類別:分類、回歸
- 使用的技術(shù):貝葉斯優(yōu)化+自動(dòng)集成構(gòu)造
- 訓(xùn)練框架:sklearn
Auto-sklean 是基于Auto-Weka(https://www.automl.org/automl/autoweka/)使用的 CASH(組合算法選擇和超參數(shù)優(yōu)化)問(wèn)題的定義以及和 AzureAutomated ML 相同的思路構(gòu)建的:他們考慮同時(shí)選擇一個(gè)學(xué)習(xí)算法和設(shè)置其超參數(shù)的問(wèn)題。他們提出的主要區(qū)別是將兩個(gè)額外的步驟合并到主進(jìn)程中:一開(kāi)始是元學(xué)習(xí)步驟,***是自動(dòng)化集成構(gòu)造步驟,詳情請(qǐng)參閱論文《Efficient and Robust Automated Machine Learning》。

auto-sklearnAutoML 方法
該方法使用了全部 38 個(gè)元特征來(lái)描述數(shù)據(jù)集,包括簡(jiǎn)單的、信息論的和統(tǒng)計(jì)的元特征,如數(shù)據(jù)點(diǎn)的數(shù)量、特征和分類,以及數(shù)據(jù)偏度和目標(biāo)的熵。利用這些信息,他們會(huì)選擇 k 個(gè)采樣點(diǎn)作為貝葉斯優(yōu)化的初始采樣點(diǎn)(seed)。注意,這種元學(xué)習(xí)方法通過(guò)使用數(shù)據(jù)集存儲(chǔ)庫(kù)來(lái)獲得強(qiáng)大的功能(就像 Azure Automated ML 那樣)。
在完成貝葉斯優(yōu)化之后,它們會(huì)構(gòu)建一個(gè)由所有嘗試過(guò)的模型組成的集成模型。這一步的思路是將訓(xùn)練每個(gè)模型所做的努力都存儲(chǔ)下來(lái)。他們沒(méi)有拋棄這些模型而選擇更好的模型,而是將它們存儲(chǔ)起來(lái),最終構(gòu)建出一個(gè)它們的集成模型。這種自動(dòng)集成構(gòu)造方法避免了讓自己陷入單個(gè)超參數(shù)的設(shè)置中,因此魯棒性更強(qiáng)(并且不容易過(guò)擬合)。他們使用集成選擇(這個(gè)貪婪過(guò)程從空集成開(kāi)始,迭代地添加能夠***化集成驗(yàn)證性能的模型)來(lái)構(gòu)建集成模型。
結(jié)語(yǔ)和點(diǎn)評(píng)
每一種方法都有各自的優(yōu)缺點(diǎn),也有其各自的賽道。Azure Automatic ML 和 auto-sklearn 是基于相同的思想構(gòu)建的,它們被用于回歸和分類任務(wù),計(jì)算量較少,因此實(shí)現(xiàn)成本較低。他們不需要整個(gè)數(shù)據(jù)集可見(jiàn)(只要構(gòu)造的模型能夠生成的),如果對(duì)數(shù)據(jù)隱私有要求的話,那么使用這兩種框架是很合適的。然而,他們嚴(yán)重依賴于已經(jīng)獲取到的數(shù)據(jù)集。除了事先處理過(guò)的機(jī)器學(xué)習(xí)工作流外,他們不能嘗試任何新的東西。我個(gè)人十分懷疑能否把這樣的方法稱為元學(xué)習(xí)。
另一方面,谷歌 AutoML 和 AutoKeras 也使用了相同的方法,它們?cè)噲D學(xué)習(xí)一種從頭開(kāi)始構(gòu)建模型的方法。這是一個(gè)更有野心的做法,這也是為什么它在動(dòng)作空間上更有限(CNN、RNN、LSTM)。然而,他們使用的強(qiáng)化學(xué)習(xí)方法使他們能夠探索構(gòu)建模型的新方法(谷歌聲稱他們的方法發(fā)現(xiàn)了一個(gè)比他們已有的模型好 1.05 倍的模型)。這聽(tīng)起來(lái)更像是元學(xué)習(xí)。然而,強(qiáng)化學(xué)習(xí)方法需要消耗大量的計(jì)算能力,這也就是它們每小時(shí)收費(fèi) 20 美元的原因。而這種情況下,AutoKeras 為了提高準(zhǔn)確率進(jìn)行的性能優(yōu)化是很有吸引力的(另外它是開(kāi)源的,如果你關(guān)心隱私的話,這也是一個(gè)好消息)。
原文鏈接:
https://medium.com/@santiagof/auto-is-the-new-black-google-automl-microsoft-automated-ml-autokeras-and-auto-sklearn-80d1d3c3005c
【本文是51CTO專欄機(jī)構(gòu)“機(jī)器之心”的原創(chuàng)譯文,微信公眾號(hào)“機(jī)器之心( id: almosthuman2014)”】