達觀數據:一文詳解深度學習、機器學習與NLP的前世今生
隨著深度學習的發展,自然語言處理領域的難題也得到了不斷突破,AlphaGo項目的主要負責人David Silver曾說“深度學習 (DL)+ 強化學習 (RL) = 人工智能 (AI)”。目前深度學習在自然語言處理上主要有哪些應用?在工程實踐中是否會有哪些瓶頸?以下內容是根據達觀數據聯合創始人高翔在《深度學習與文本智能處理》直播的總結。
一、為什么做文本挖掘
什么是NLP?簡單來說:NLP的目的是讓機器能夠理解人類的語言,是人和機器進行交流的技術。它應用在我們生活中,像:智能問答、機器翻譯、文本分類、文本摘要,這項技術在慢慢影響我們的生活。
NLP的發展歷史非常之久,計算機發明之后,就有以機器翻譯為開端做早期的NLP嘗試,但早期做得不是很成功。直到上個世紀八十年代,大部分自然語言處理系統還是基于人工規則的方式,使用規則引擎或者規則系統來做問答、翻譯等功能。
***次突破是上個世紀九十年代,有了統計機器學習的技術,并且建設了很多優質的語料庫之后,統計模型使NLP技術有了較大的革新。接下來的發展基本還是基于這樣傳統的機器學習的技術。從2006年深度學習開始,包括現在圖像上取得非常成功的進步之后,已經對NLP領域影響非常大。
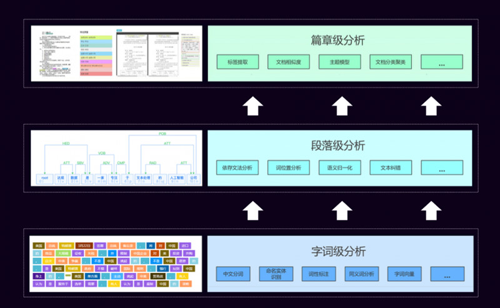
達觀劃分的NLP技術層次
當年上小學時有一本書叫《字詞句篇與達標訓練》,里面講了字、詞、句、篇,我們開始學寫字,中文的一個字比英文的一個字母的語義要豐富的多,但表義能力仍然較差。詞是最基礎的一級,所以中文一般的處理情況都是按照詞級別,詞級別的分析就有了中文分詞、有了命名實體識別這樣的層次來做底層處理。
在這個底層處理之上是段落級別,是一句話、一段話、短的文本,對這個級別文本做法又對應了相關的技術,包括:依存文法分析、詞位置分析、語義歸一化、文本糾錯等等功能。但是這個功能也是為它更上級的服務去服務的,達觀稱之為“篇章”級的應用。
大部分同學平時做比賽、做項目關注的點最多是在“篇章”級的應用,底下這些中文分詞等都已經有很好的工具了,不用再從頭到尾去開發,只要關心上層的應用,把底下的工具用好,讓它產生需要的Feature,來做分類、主題模型、文章建模,這種比較高層次的應用。
所以,要做好NLP,包括我們公司在內,這三個級別的技術都是自己掌握的。但是如果個人學習使用是有權衡的。某個同學的某一個技術特別好也是OK的,因為現在開源工具,甚至商用工具有很好的效果。如果不要求精度特別高或者有特殊的要求,用這些工具一般是可以達到你的要求。
每個層次的技術都是完全不同的,而且層次間的技術是有聯系,一般的聯系是底層是為上層服務。
達觀數據就是應用這些技術為企業提供文檔智能審閱、個性化推薦、垂直搜索等文本挖掘服務。
二、為什么要用深度學習?
深度學習的發展與應用要有一定的基礎,上個世紀末互聯網時代到來已經有大量的數據電子化,我們有海量的文章真是太多了,有這樣的數據之后就要去算它,需要算法進步,以前這個數據量規模沒法算,或者數據量太大算起來太慢。就算有更好的算法還是算得很慢時,就需要芯片的技術,尤其我們現在用并行計算GPU,這個加速對各種各樣的算法尤其深度學習的算法影響速度非常大。
所以一定要有這三個基礎——數據、算法、芯片,在這三個核心基礎上面做更高級的應用,涉及人的感官——聽覺、視覺、語言這三個感官,語音的識別、計算機的視覺、自然語言的處理。
深度學習與機器學習
很多同學會把深度學習和機器學習劃等號。實際上它們不是等號。AI的概念非常大,比如我們用的Knowledge Base知識數據庫也是一種AI,它可能沒有那么智能。機器學習是AI其中的一小塊,而深度學習又是機器學習中的一小塊,我們常見的CNN、RNN都屬于深度學習的范疇。同時,達觀也做Logistics Regression知識圖譜,因為知識圖譜是NLP中一個很重要的應用,無論是生成知識圖譜,還是用它做像問答等其他應用都是會用到的。
我們為什么要用深度學習?可以比較一下經典機器學習和深度學習間的差異。
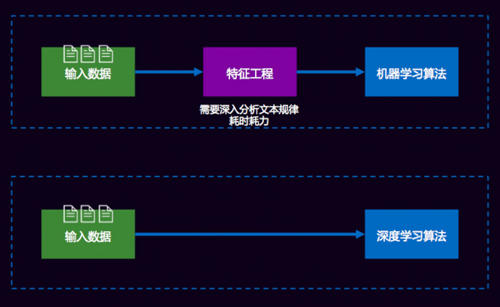
比如做一個分類的問題,這兩個分類問題唯一的區別就是特征工程的區別。我們用經典的機器學習算法是上面這條路,輸入數據后大家就開始(包括打比賽也)做各種各樣的特征工程。有了這樣的特征,我們還要根據TF-IDF、互信息、信息增益等各種各樣的方式去算特征值,或對特征進行過濾排序。傳統機器學習或經典機器學習90%的時間都會花在特征工程上。
而Deep learning顛覆了這個過程,不需要做特征工程。需要各種各樣的特征,比如需要一些長時間依賴的特征,那可以用RNN、LSTM這些,讓它有個序列的依賴;可以用局部的特征,用各種各樣的N元語法模型,現在可以用CNN來提取局部的文本特征。
深度學習節省的時間是做特征工程的時間,這也是非常看重深度學習的原因:
***,特征工程做起來很累。
第二,很多實際場景是挖掘出一個好的特征或者對我們系統貢獻很大的特征,往往比選擇算法影響還大。用基本的特征,它的算法差距不會特別大,最多也就10個點,主要還是特征工程這塊,而深度學習很好的解決了這個問題。
有了深度學習之后,對文本挖掘就有了統一處理的框架,達觀把它定義為五個過程:
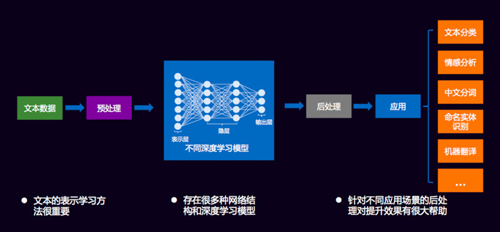
1、文本數據。
2、預處理。預處理很重要,大家在工作中拿到的數據都是經過清洗過程的,“達觀杯”算法大賽的數據是我們幫大家清洗過的。比賽中做到的字、詞都是各種各樣的ID,是預處理的一部分。
3、有了預處理之后,我們可以選擇各種各樣的網絡。
4、后處理,比如業務需要分類,分類最終的結果是通過不通過,這都是后處理的過程。
5、應用,應用的方向有文本分類、情感分析、中文分詞、命名實體識別、機器翻譯。
幾乎所有任務都可以拿Deep learning來做,它的適應性和它的廣度非常好,例如傳統的機器學習做文本分類需要特定的算法,而這個算法不可能做命名實體識別的事情。
通過Vector Representationns?進行低緯度連續空間的字詞表示
在深度學習在NLP領域火起來之前,最有代表性的一個研究、對每個人影響***的工作就是Word2Vec,把一個字、一個詞變成向量來表示,這是對我們影響非常大的工作。
這件事情的好處是什么?在之前我們以詞為單位,一個詞的表示方式幾乎都是one hot, one hot序列有一個致命的缺點,你不能計算相似度,所有人算出來都是“0”,都是一樣的,距離也都是一樣的,因此它不能很好的表示詞之間的關系。
過去像威海市、濰坊市、棗莊市這三個城市對計算機來說是完全不一樣的東西,而我們使用Word2Vec做這件事情有兩個好處:
***,這個詞如果有1萬維的話,1萬維本來存儲它就是一個非常稀疏的矩陣、而且很浪費,我們就可以把它變得更小,因為我們的Word2Vec里面一般的向量都在 512以內。
這個維度的向量相對1萬維來說已經是比較低維的空間,它里面存的是各種的浮點數,這個浮點數看起來這三個向量好像每個都不一樣,但是實際去計算,發現這三個向量之間的相似度非常高,一個是相似度可以判斷它的相似性,另外是判斷它們的距離。
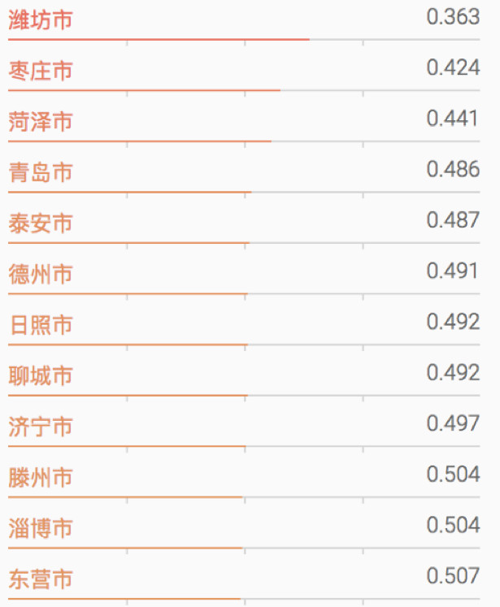
威海、濰坊、棗莊這幾個城市在空間上離得非常近,它們的數值也非常近。它對于我們實際工作的好處是增強了我們的泛化能力,這是一個很難做的事情。
***,有更好的帶語義的表示;
第二,有了這樣的表示之后可以做語義的計算,包括山東-威海約等于廣東-佛山,兩個向量之間是約等于的,語義的東西不太好解釋,但是人知道這是怎么回事,語義相近就是Word2Vec***的幫助。
有了表示學習之后,下一步就是常見的各種網絡結構,這些都是非常常見的,比如CNN、GRU、RNN、Bi-LSTM。LSTM也是一種RNN,Bi-LSTM也是一種LSTM,只不過Bi是雙向的LSTM,它可能學到前后上下文的特征和語義。GRU的好處是比LSTM這種算法稍微簡單,所以在層次比較深的時候或者比較復雜的時候,用它這個單元的運算效率會高一點、快一點,但它實際精度可能稍微差一點,所以模型那么多,怎么來選是很重要的,要根據大家的實踐去看看怎么用。
CNN模型原理
CNN是卷積神經網絡。
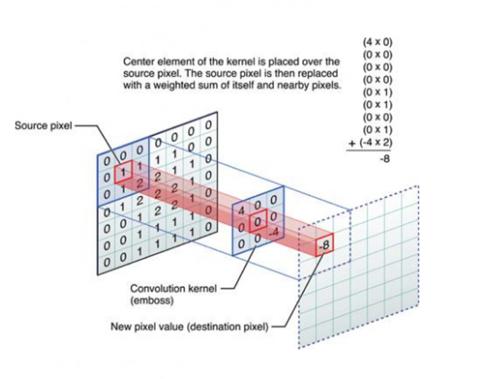
這張圖中間的九宮格就是個卷積格,每個數字相當于一個過濾器。它做的事情對一個圖像來說,是把九宮格和圖像中對應的矩陣相乘,乘出來一個結果,得到卷積之后它就開始平移,平移的步長是可選擇的,一般我們都是一步一步平移過去。
它這樣的好處是什么?對于圖像來說,1個像素真的代表不了什么東西,那9個像素是不是有意義?是有意義的,它可能學到像直線、彎曲等特征,很簡單的圖形特點,然后它會得到一層。
為什么叫深度學習?我們這只是一層,它在CNN里面尤其圖像識別網絡,大家都聽過“大力出奇跡”,網絡越深效果越好,因為它經過一層一層的學習,可以把每一層的特征進行濃縮。簡單的像素沒有任何的表義能力,到***層濃縮之后它有一些點線的能力,再往上濃縮可能就有弧線的能力,再往上濃縮它越來越復雜,可以做到把一個像素這個沒有意義的東西變成有意義的東西,可以把它可以看成是一層層的過濾,選出***的特征結果,這是卷積的原理。卷積不僅僅在圖像里,在文本里用得也非常好。
RNN和LSTM
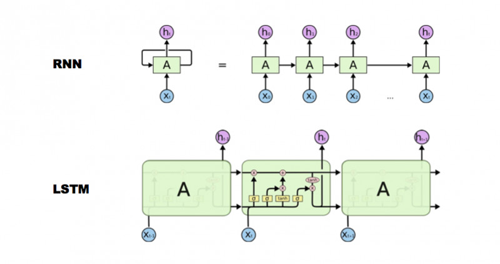
簡單來說LSTM就是單元格換了一個更復雜的RNN,它可以做到RNN做不到的事情。為什么叫長短期記憶網絡?看下面這張圖,它比傳統的RNN多了一個所謂的細胞狀態,我翻譯成“細胞”,一般也叫“cell”。它多了一個存儲長期信息的“cell”狀態。
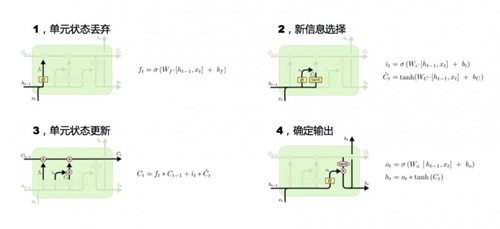
我們看一下***張圖,它是怎么來做長期記憶的更新?看輸入Ht-1和Xt,Ht-1是上一個時刻這個cell隱狀態的輸出,Xt是當前輸入,它們兩個通過這個函數計算后的輸出是0-1之間的某一個值。***步,決定上個時刻細胞狀態留下的比率是多少。
第二步,來了一些新的信息,不能只是把老的細胞狀態更新,還要把新的信息添進去,通過這兩個公式來添,***個公式輸出0-1的系數,第二個公式要選出量是多少。有了***步和第二步之后就開始第三步細胞狀態更新,***步的輸出0-1和Ct-1相乘決定上一時刻這個細胞狀態留下多少。第二步算出來系數和信息量相乘決定留下多少新增信息,然后把上一步剩下的和這一步新增的加起來,做一個更新,這個更新就是現在的cell狀態值。
現在單元的狀態更新完了,下一步就要輸出,這個輸出有兩個:***個,對外是一樣,還是隱層的輸出Ht,這個輸出和前面講的RNN隱層輸出是一樣的,只是多了一步內部更新。決定留下多少老的信息,決定留下多少新的信息,再把老的信息和新的信息加起來就是最終的結果。
長短期記憶網絡可以把很長很遠的語義通過Ct把信息記下來,而RNN本來就很擅長記憶這種比較近的信息,所以LSTM長短信息都能記下來,對后面特征的選擇、模型的輸出選擇有很大的幫助。
三、深度學習的具體應用
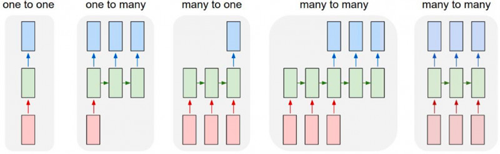
1、one to one。圖像分類:對于我們來說,圖像就是二維矩陣,就是像素XY坐標的矩陣,輸入之后經過神經網絡的處理輸出藍色,這是分類問題。
2、one to many。圖像描述。最早看到這個應用覺得很神奇,一個圖像進來了,它告訴我圖像上有一個狗、一個貓站在車旁邊,這就是一個圖像描述的過程,它可以把圖像變成很多輸出,這就是one to many的問題。
3、many to one。輸入的是一個序列,文字等都是這樣一個序列,這個序列輸出之后做文本分類、情感分析,它最終都給出來這樣一個結果,它們都屬于“多到一”的過程。
4.many to many。這有兩張圖,它們的區別是:***張圖紅色輸入的時候沒有藍色的輸出,而是等第三個紅色輸入的時候藍色開始輸出,它是一個異步的序列到序列的問題,異步到一個序列問題常見的例子就是機器翻譯。機器翻譯是看到很多上下文才能決定開始怎么翻譯,不能光看到China就翻譯成中國,因為英文的表述和中文表述順序有時候不同,需要看到上下文之后再去翻譯。但是有異步就有同步,我們寫代碼經常遇到異步和同步問題,其實這邊也一樣,序列到序列的同步關系就是我們經常見的,所有選手應該都知道的序列標注問題。序列標注問題的上面就是各種各樣的應用。
本次講的是文本,所以我著重會講many to one和many to many的過程。
文本分類

“達觀杯”算法大賽很多同學在用傳統的方式,包括baseline來做,很多人吐槽baseline好像有點高。但是我們沒有做特殊優化,這是最基礎的版本,做出來很高說明傳統的機器學習還是非常好的,不是Deep learning一統天下。
傳統的機器學習,需要構造特征,不同領域定制化程度很高,這個模型A領域用了,B領域幾乎要從頭再做一遍,沒有辦法把其他的特征遷移過來很好的使用。某些領域效果很好,某些領域另外一個算法很好,傳統機器學習把各種各樣的方式做以融合來提升效果。
深度學習則可實現端到端,無需大量特征工程。框架的通用性也很好,能滿足多領域的需求,并且可以使用費監督語料訓練字詞向量提升效果。但是為什么有人吐槽Deep learning?因為調參很麻煩,有時改了一下參數好很多,改了一個參數效果又下降了,有的算法能夠對此有一定的解釋,但不像傳統機器學習能夠解釋得那么好。這兩大幫派不能說完全誰戰勝了誰,是相融相生的。
TextCNN
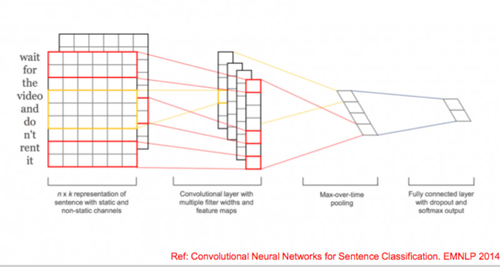
它是一個單層的CNN,選擇了幾種類型的卷積,做一個feature map,然后用max-pooling取得每個map***的特征作為最終的輸出,結構非常簡單,大家只要有一點深度學習的知識就可以,但是因為過于簡單,而且CNN天生的缺陷是寬度有限,導致它會損失語義的問題。
Deep Pyramin CNN
Deep Pyramin CNN就是深度的CNN, CNN的特點就是結構簡單。雖然有block N,但它每個block長得都是一樣的,除了***層,每一層就是一個pooling取一半,剩下是兩個等寬度的卷積,輸出250維,疊加好幾層后就可能學到非常準的語義。

Hierarchical Attention Network
這個模型的優點是非常符合人類的思維。Word級別的時候前面的套路都是一樣的,做各種Embedding,在Embedding到下一層次,這個輸到下一層sentence級別之前會加一層Attention,讓它知道這句話里面哪一個詞最重要,這像我們知道一句話中哪個詞最重要。
最終輸出之前再加個Attention,這個Attenton是去學這里面哪些句子最重要的。你可以簡單的理解,它把我們輸入的那么多文本,也是經過了一層層的過濾,前面是通過卷積的過程,它現在是通過Attention的機制去找。
還有一個特別好的地方是學部分可解釋,句子里哪些詞最重要,它的藍顏色就更深,它能找到語義級別哪個語義對分類貢獻***,這是這個網絡很好的一點。
包括前面講的HNN、Deep Pyramin CNN,網上的實現跟論文是有一定差別的。所以大家要注意,我們關注的是它整體的網絡結構,并不是每一點的***的還原,我們不是它的復制者,而是它的使用者。所有的網絡結構、參數甚至過程,只要大體的思想有了就OK。這兩個是many to one在文本分類上用得很多的。
序列標注
序列標注就兩個東西:***個是定義標簽體系。我們這邊一般最常用BMES,簡單一點的IO,復雜一點的BIO,BMES算是一個經典的方法,不多也不少,還有M1、M2、M3更復雜的一般都不太用。
深度學習和傳統文本處理方法的結合
傳統的CRF用起來效果不錯,Deep learning也能夠把這個事情做得很好。LSTM可以學習到很長的上下文,而且對識別非常有幫助。實際問題或者工業應用來說,我們要保證它的整體效果和復雜度的情況下,這邊Bi-LSTM是一個非常好的方式,也是相對比較成熟的方式。
為什么要加CRF?我對這個模型結構的看待,它是一個深度學習和傳統方式非常***的結合。Bi-LSTM做特征工程,CRF做標簽的輸出。很多同學都試過,用純的Bi-LSTM去寫,最終輸出標簽之間沒有序列依賴的關系。
序列標注特征選擇多維度字詞向量表示
做這個模型能做什么事情?大家的網絡都類似,怎么去PK?
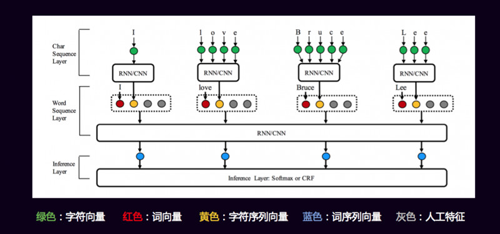
這是非常好的一篇論文,講到了我們怎么能夠把各種各樣的level的信息用到,它這邊是英文,所以有一個char級別的,先對char,通過RNN、CNN做一個Embedding,學習到char級別上的關系,char級別的關系合并之后是黃顏色那個字符的向量,然后它又把word級別的紅顏色的詞向量也加進去拼起來,還有兩個是灰顏色的,灰顏色的是人工特征。就看大家自己怎么加,這是每個人的智慧。
引入注意力機制來實現生成式摘要
生成式摘要很難的一個東西,它的訓練集標注比我們標分詞、標分類難得多,要有一篇文章,人得寫出摘要,整理出好多這樣的摘要,因為每個人寫得不一樣,包括評測的方式BLUE等,所以做摘要比較難。但是我們平時可以基于生成式文本的其他小應用。
舉個簡單的例子,大家爬過一些新聞的網站,那么長的正文一般正文***段把事情都說清楚了,然后有一個新聞的標題,我們可以用***段作為輸入,標題作為輸出,做這樣一個簡單的通過新聞***段可以寫出新聞標題的功能,其實跟生成摘要的思想是一樣的。
唯一的差別是它加了注意力的機制,你會發現它關注輸出的哪些詞對語義表達最有用,它會關注有用的信息,解碼的時候就可以得到各種各樣的序列、各種各樣的值,用beam search找到***的結果。
引入注意機制,以前做不了這個事情,現在我們可以做這個事情。工業中用得比較多的是抽取式的摘要,簡單來說就是一篇文章中哪些句子比較重要,把它抽出來就可以了。
四、達觀數據文本挖掘的經驗和思考
實際工程中需要考慮的因素:
1、長文本閱讀的場景和關鍵難點有哪些?
2、文檔結構信息(如段落)丟失時該如何還原?
3、數據的訓練量如何,質量和數據量都不行的時候該怎么辦?
4、如何構建一個真正面向實用的測評系統?
5、領域知識如何引入到系統中?
6、知識圖譜自動化構建方法?
7、深度學習和經典機器學習該如何取舍?
達觀在實際工程中運用深度學習挖掘文本的思考:
深度學習優點
1、我們可以用非監督的訓練向量來提升它的泛化,主要目標是提升泛化。
2、它有些端到端的方式,可以提供新思路。
3、深度學習能夠克服傳統模型的缺點,大家用CRF很多,但CFR有時拿不到太遠的長的上下文,它比較關注左右鄰居的狀態,很遠的狀態對它影響不大。但是有些語義影響很大,比如我們要抽“原告律師”、“被告律師”,“原告劉德華”,然后中間講了一大堆,“委托律師張學友”,我們能抽取出來他是律師,但是如何知道他是原告律師?一定要看到劉德華前面三個有“原告”兩個字,才知道他是原告律師。這時如果用深度學習LSTM的方式可以學到比較遠的上下文特征,幫助你解決這個問題。
深度學習缺點
1、 小數據量的情況,效果不能保證
2、 調參工作量有時不亞于特征工程
3、 系統要配合客戶的部署硬件系統
思考
1、在業務場景下盡量收集并理解數據,分析問題本質,選擇合適模型
2、初始階段可以使用傳統機器學習模型快速嘗試,再引入深度學習技術
3、疑難問題使用端到端也許會有驚喜
4、關注前沿技術,包括對抗網絡、強化學習、遷移學習
5、一句話送給大家, “數據決定效果的上限,模型只是逼近上線。”
6、不斷嘗試,從挫折中總結規律
【本文為51CTO專欄作者“達觀數據”的原創稿件,轉載可通過51CTO專欄獲取聯系】