用戶畫像系統的技術架構和整體實現
作者簡介:楊思義,男,26歲,2015年6月畢業于山東大學齊魯軟件學院,工程碩士學位。
2014年6月至今工作于北京亞信智慧數據科技有限公司 BDX大數據事業部,從2014年9月開始從事項目spark相關應用開發。
這里講解下用戶畫像的技術架構和整體實現,那么就從數據整理、數據平臺、面向應用三個方面來討論一個架構的實現(個人見解)。
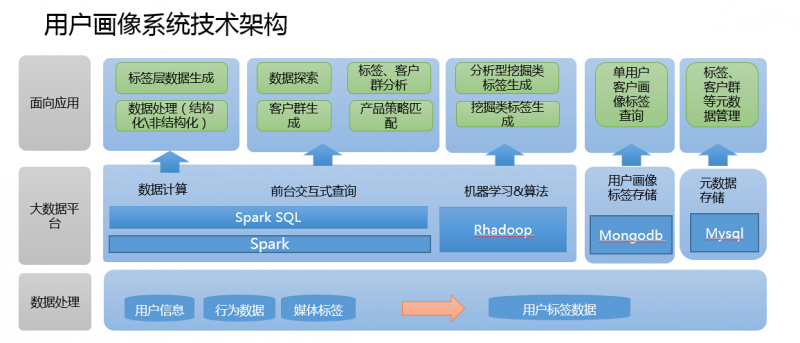
數據整理:
1、數據指標的的梳理來源于各個系統日常積累的日志記錄系統,通過sqoop導入hdfs,也可以用代碼來實現,比如spark的jdbc連接傳統數據庫進行數據的cache。還有一種方式,可以通過將數據寫入本地文件,然后通過sparksql的load或者hive的export等方式導入 HDFS。
2、通過hive編寫UDF 或者hiveql 根據業務邏輯拼接ETL,使用戶對應上不同的用戶標簽數據(這里的指標可以理解為為每個用戶打上了相應的標簽),生成相應的源表數據,以便于后續用戶畫像系統,通過不同的規則進行標簽寬表的生成。
數據平臺
1、數據平臺應用的分布式文件系統為Hadoop的HDFS,因為Hadoop2.0以后,任何的大數據應用都可以通過 ResoureManager申請資源,注冊服務。比如(sparksubmit、hive)等等。而基于內存的計算框架的出現,就并不選用hadoop 的MapReduce了。當然很多離線處理的業務,很多人還是傾向于使用Hadoop,但是hadoop的封裝的函數只有map和Reduce太過單一,而不像spark一類的計算框架有更多封裝的函數(可參考博客spark專欄)。可以大大提升開發效率。
2、計算的框架選用Spark以及RHadoop,這里Spark的主要用途有兩種,一種是對于數據處理與上層應用所指定的規則的數據篩選過濾, (通過Scala編寫spark代碼提交至sparksubmit)。一種是服務于上層應用的SparkSQL(通過啟動spark thriftserver與前臺應用進行連接)。 RHadoop的應用主要在于對于標簽數據的打分,比如利用協同過濾算法等各種推薦算法對數據進行各方面評分。
3、MongoDB內存數據的應用主要在于對于單個用戶的實時的查詢,也是通過對spark數據梳理后的標簽寬表進行數據格式轉換(json格式)導入mongodb,前臺應用可通過連接mongodb進行數據轉換,從而進行單個標簽的展現。(當然也可將數據轉換為Redis中的key value形式,導入Redis集群)
4、mysql的作用在于針對上層應用標簽規則的存儲,以及頁面信息的展現。后臺的數據寬表是與spark相關聯,通過連接mysql隨后 cache元數據進行filter,select,map,reduce等對元數據信息的整理,再與真實存在于Hdfs的數據進行處理。
面向應用
從剛才的數據整理、數據平臺的計算,都已經將服務于上層應用的標簽大寬表生成。(用戶所對應的各類標簽信息)。那么前臺根據業務邏輯,勾選不同的標簽進行求和、剔除等操作,比如本月流量大于200M用戶(標簽)+本月消費超過100元用戶(標簽)進行和的操作,通過前臺代碼實現sql的拼接,進行客戶數目的探索。這里就是通過jdbc的方式連接spark的thriftserver,通過集群進行HDFS上的大寬表的運算求count。(這里要注意一點,很多sql聚合函數以及多表關聯join 相當于hadoop的mapreduce的shuffle,很容易造成內存溢出,相關參數調整可參考本博客spark欄目中的配置信息) 這樣便可以定位相應的客戶數量,從而進行客戶群、標簽的分析,產品的策略匹配從而精準營銷。