如何優(yōu)雅的解決分布式數(shù)據(jù)庫(kù)的復(fù)雜故障
故障簡(jiǎn)介
ACID是事務(wù)的四個(gè)特性,其中D(Duration)就是講的持久性,數(shù)據(jù)庫(kù)的一大價(jià)值就在于可以有效處理的故障,保證數(shù)據(jù)不會(huì)丟失。隨著分布式數(shù)據(jù)庫(kù)的發(fā)展,部署的復(fù)雜度上升,數(shù)據(jù)庫(kù)面臨的故障場(chǎng)景也越來(lái)越多。
常見(jiàn)硬件故障
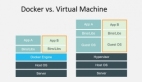
接下來(lái),我們看下常見(jiàn)數(shù)據(jù)中心的故障概率

《Designs, Lessons and Advice from Building Large Distributed Systems》,jeff dean
網(wǎng)絡(luò)故障
除了上述故障,對(duì)于分布式系統(tǒng)設(shè)計(jì),還有一些額外的網(wǎng)絡(luò)故障需要考慮
腦裂,顧名思義,腦裂指的是系統(tǒng)因?yàn)榫W(wǎng)絡(luò)故障被分割為多個(gè)獨(dú)立的區(qū)域;
多網(wǎng)面條件下,部分網(wǎng)面故障,這個(gè)錯(cuò)誤一般是很難出現(xiàn)的,因?yàn)槊總€(gè)網(wǎng)面往往是邏輯的,并不和網(wǎng)卡綁定,如果用戶調(diào)整配置出錯(cuò),可能導(dǎo)致這種故障,如果系統(tǒng)橫跨多個(gè)網(wǎng)面,需要考慮這個(gè)故障;
脆弱的數(shù)據(jù)中心
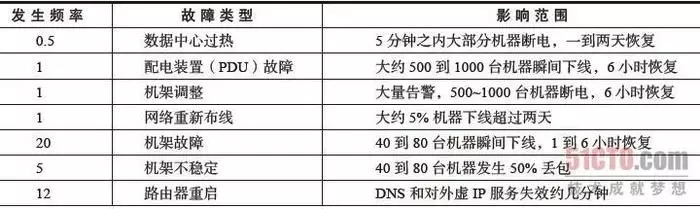
實(shí)際上,數(shù)據(jù)中心也沒(méi)有想象中的那么穩(wěn)定,下圖是筆者2017年11月22日截取的cloudharmony監(jiān)控?cái)?shù)據(jù),監(jiān)控300多家數(shù)據(jù)中心的可靠性情況。
可以看到,即使大名鼎鼎的azure,也未能達(dá)到宣稱99.95%,有興趣的詳細(xì)了解的可以看這里
除此之外,再給大家舉幾個(gè)詳細(xì)的例子
2017年9月29日 azure北歐數(shù)據(jù)中心故障
北歐數(shù)據(jù)中心部分在定期的常規(guī)滅火系統(tǒng)維護(hù)中發(fā)生了意外,釋放出了滅火劑。然后導(dǎo)致了專門用于遏制和安全的空氣處理單元(AHU)自動(dòng)關(guān)閉。而受到影響區(qū)域的某些系統(tǒng)為防止系統(tǒng)過(guò)熱對(duì)部分機(jī)器進(jìn)行關(guān)機(jī)和重啟,AHU在35分鐘后手動(dòng)恢復(fù),因?yàn)橄到y(tǒng)突然關(guān)機(jī)導(dǎo)致部分?jǐn)?shù)據(jù)需要恢復(fù),系統(tǒng)在7小時(shí)后才恢復(fù)正常。該事故導(dǎo)致了部分用戶的存儲(chǔ)服務(wù)不可用。
2017年2月28日amazon s3故障
運(yùn)維工程師定位賬務(wù)系統(tǒng)變慢這個(gè)問(wèn)題時(shí),想要?jiǎng)h除一小部分服務(wù)器,結(jié)果命令輸入錯(cuò)誤刪除了大批服務(wù)器,包括 index subsystem和placement subsystem的服務(wù)器,導(dǎo)致S3服務(wù)從9:37AM開(kāi)始不可用,直到1:54PM,其中最有意思的是,AWS Service Health Dashboard系統(tǒng)依賴S3,因此從故障發(fā)生直到11:37AM,監(jiān)控頁(yè)面沒(méi)有顯示故障。這個(gè)故障據(jù)說(shuō)弄倒了半個(gè)墻外的互聯(lián)網(wǎng)世界。
2016年4月13日Google Compute Engine停止服務(wù)
全球所有區(qū)域的Google Compute Engine停止服務(wù),18分鐘后恢復(fù)。該故障由一個(gè)運(yùn)維工程師刪除一個(gè)無(wú)用的ip blocks引起的,而刪除ip這個(gè)操作并沒(méi)有合理做配置同步,這個(gè)操作觸發(fā)了網(wǎng)絡(luò)配置系統(tǒng)的一致性檢測(cè),當(dāng)網(wǎng)絡(luò)配置系統(tǒng)檢測(cè)到不一致后,進(jìn)行了重啟,導(dǎo)致服務(wù)中斷。
2015年5月27日 杭州電信挖斷阿里網(wǎng)線
光纖挖斷后,部分用戶無(wú)法使用,兩小時(shí)后恢復(fù)。
2014年7月1日 寧夏銀行核心數(shù)據(jù)庫(kù)系統(tǒng)故障
銀行二部(2014)187號(hào)正式發(fā)全國(guó)文件,對(duì)寧夏銀行事故的描述大致如下,2014年7月1日,寧夏銀行核心系統(tǒng)數(shù)據(jù)庫(kù)出現(xiàn)故障,導(dǎo)致該行(含異地分支機(jī)構(gòu))存取款、轉(zhuǎn)賬支付、借記卡、網(wǎng)上銀行、ATM和POS業(yè)務(wù)全部中斷。
經(jīng)初步分析,在季末結(jié)算業(yè)務(wù)量較大的情況下,因備份系統(tǒng)異常導(dǎo)致備份存儲(chǔ)磁盤讀寫處理嚴(yán)重延時(shí),備份與主存儲(chǔ)數(shù)據(jù)不一致,在采取中斷數(shù)據(jù)備份錄像操作后,造成生產(chǎn)數(shù)據(jù)庫(kù)損壞并宕機(jī)。因?qū)幭你y行應(yīng)急恢復(fù)處置機(jī)制嚴(yán)重缺失,導(dǎo)致系統(tǒng)恢復(fù)工作進(jìn)展緩慢,直至7月3日5點(diǎn)40分核心系統(tǒng)才恢復(fù)服務(wù),業(yè)務(wù)系統(tǒng)中斷長(zhǎng)達(dá)37小時(shí)40分鐘,其間完全依靠手工辦理業(yè)務(wù)。
故障分類
看一下數(shù)據(jù)中心網(wǎng)絡(luò)的互聯(lián)圖
圖上任何的硬件設(shè)備都可能發(fā)生故障,從各個(gè)主機(jī),交換機(jī)到網(wǎng)線。
我們嘗試以故障域?qū)收献鲆粋€(gè)簡(jiǎn)單的分類。所謂故障域,就是會(huì)因?yàn)橐粋€(gè)故障而同時(shí)不可用的一組組件,常見(jiàn)的故障域包括:
- 物理機(jī)器,包括本地磁盤,網(wǎng)卡故障,內(nèi)存故障等
- 數(shù)據(jù)中心共用一組電源的一個(gè)機(jī)柜
- 數(shù)據(jù)中心共用一個(gè)網(wǎng)絡(luò)設(shè)備的數(shù)個(gè)機(jī)柜
- 受單個(gè)光纖影響的一個(gè)數(shù)據(jù)中心
- 處于同一個(gè)地域的多組數(shù)據(jù)中心,被同一個(gè)城市供電或受同一自然災(zāi)害影響
故障的變化
不同組件發(fā)生故障的概率是不同,google一項(xiàng)研究表明,在36 °C和47 °C范圍內(nèi)運(yùn)轉(zhuǎn)的磁盤,故障率***,隨著時(shí)間的發(fā)展,磁盤故障率也逐漸提升,***年只有1.7%,第三年達(dá)到8.6%。
現(xiàn)在也有很多研究,將大數(shù)據(jù)和人工智能引入了磁盤故障預(yù)測(cè)領(lǐng)域,取得了不錯(cuò)的成果。
數(shù)據(jù)庫(kù)故障處理
日志系統(tǒng)
數(shù)據(jù)庫(kù)會(huì)為數(shù)據(jù)修改記錄日志,日志記錄了數(shù)據(jù)的變化,根據(jù)不同的日志用途,可以分為redo日志、. undo日志、redo/undo日志,現(xiàn)在流行的是redo日志。
看一下postgresql日志的結(jié)構(gòu):
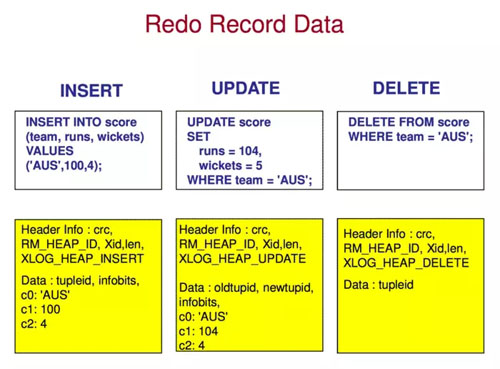
根據(jù)不同日志記錄方式,可以分為如下兩種類型:
- 物理日志,上圖即物理日志,replay速度快,但是日志量大,實(shí)現(xiàn)邏輯相對(duì)簡(jiǎn)單不易出錯(cuò);
- 邏輯日志,replay速度相對(duì)慢,日志量小,而且對(duì)于MVCC機(jī)制的數(shù)據(jù)庫(kù)有一個(gè)額外的好處,備機(jī)可以單獨(dú)gc,和主機(jī)無(wú)關(guān);
數(shù)據(jù)庫(kù)日志系統(tǒng)有兩個(gè)重要的原理:
- WAL原則,也就是日志刷盤要在頁(yè)面刷盤之前,這里的刷盤,并非調(diào)用write就可以,還需要調(diào)用sync操作。在合適時(shí)機(jī),往往是事務(wù)提交時(shí),將日志刷盤,并調(diào)用sync同步到磁盤,以保證斷電時(shí)可以恢復(fù)數(shù)據(jù)。除了在事務(wù)提交時(shí)將日志刷盤,在涉及元數(shù)據(jù)操作時(shí),往往也會(huì)調(diào)用sync將數(shù)據(jù)刷盤,以保證元數(shù)據(jù)的一致。
- 通過(guò)日志系統(tǒng)恢復(fù),不僅僅需要一份完好的日志,還需要一份完整的(可以是落后的)數(shù)據(jù)作為起點(diǎn)。
日志系統(tǒng)是系統(tǒng)軟件內(nèi)廣泛使用的技術(shù),不僅僅是數(shù)據(jù)庫(kù),日志代表了系統(tǒng)的改變,他可以用來(lái)恢復(fù)/備份,也可以用做通知系統(tǒng),掌握了系統(tǒng)的日志流,就相當(dāng)于掌握了系統(tǒng)的整個(gè)狀態(tài),日志可以更抽象的理解為日志+狀態(tài)機(jī),通過(guò)不斷的重訪日志,改變狀態(tài)機(jī)的狀態(tài),可以通過(guò)傳遞日志將狀態(tài)改變傳遞到整個(gè)系統(tǒng)的各個(gè)角落,關(guān)于日志系統(tǒng),筆者見(jiàn)過(guò)的***的一篇文章是The Log: What every software engineer should know about real-time data’s unifying abstraction,非常推薦一讀,日志即一切。
日志回收
日志代表了系統(tǒng)所有的變化,如果數(shù)據(jù)大小是從0開(kāi)始擴(kuò)展到100G,那么日志至少也要有100G,甚至更多,而日志的增長(zhǎng)和用戶做出的改動(dòng)是正相關(guān),任何系統(tǒng)也無(wú)法存儲(chǔ)***增長(zhǎng)的日志。
回收日志所占存儲(chǔ)空間是必然的選擇,日志收回有兩個(gè)好處:
- 減少日志占據(jù)磁盤空間
- 降低系統(tǒng)恢復(fù)需要的時(shí)間
實(shí)際上,對(duì)于MVCC機(jī)制實(shí)現(xiàn)的數(shù)據(jù)庫(kù),因?yàn)槿罩净厥蘸褪聞?wù)提交沒(méi)有關(guān)系,所以可以嚴(yán)格的將日志控制在指定大小,為系統(tǒng)運(yùn)維提供方便。
上文所說(shuō)數(shù)據(jù)恢復(fù)需要一份完好的數(shù)據(jù)作為起點(diǎn),其實(shí)原因就是最開(kāi)始的日志被回收了,如果能保留從初始狀態(tài)到***狀態(tài)的所有日志,那么光靠日志也可以恢復(fù)系統(tǒng),但是很明顯,任何系統(tǒng)也不能保留所有日志。
checkpoint
checkpoint用于回收日志,checkpoint的流程如下:
打點(diǎn):記錄當(dāng)前日志位置;
將當(dāng)前系統(tǒng)內(nèi)所有內(nèi)存中的數(shù)據(jù)刷盤,并調(diào)用sync同步到磁盤,此時(shí)仍要遵循WAL原則;
寫checkpoint日志,或?qū)heckpoint信息作為元數(shù)據(jù)刷盤;
回收checkpoint起始點(diǎn)之前的日志;
上面是常見(jiàn)的做checkpoint方式,這種方式也叫做全量檢查點(diǎn)(full checkpoint),這種方式實(shí)現(xiàn)簡(jiǎn)單,但是明顯checkpoint是一次IO峰值,會(huì)造成性能抖動(dòng)。
還有一種做checkpoint的方式,叫做增量檢查點(diǎn)(incremental checkpoint),過(guò)程如下:
后臺(tái)寫進(jìn)程按照頁(yè)面***次修改的順序刷盤;
打點(diǎn):記錄當(dāng)前刷盤的頁(yè)面對(duì)應(yīng)的日志點(diǎn),寫checkpoint日志或者作為元數(shù)據(jù)刷盤;
這種方式化checkpoint為后臺(tái)寫操作,做checkpoint時(shí)只需要打點(diǎn)即可,消除了IO峰值,有助于平穩(wěn)數(shù)據(jù)庫(kù)性能。
torn page
數(shù)據(jù)庫(kù)頁(yè)面大小和磁盤扇區(qū)大小往往不同,因此當(dāng)頁(yè)面刷盤時(shí),如果系統(tǒng)斷電,可能只有部分頁(yè)面刷盤,這種現(xiàn)象,我們稱之為torn page,這個(gè)頁(yè)面相當(dāng)于被徹底損壞,而日志replay需要一份完整的數(shù)據(jù)做起點(diǎn),此時(shí)是無(wú)法恢復(fù)的。
處理半寫有幾種方式:
- innodb的double write,pg的full page write,這兩種方式原理是類似的,都是在頁(yè)面刷盤前,將頁(yè)面首先寫在其他地方,sync后,再覆蓋寫頁(yè)面。
- 從備份恢復(fù),從備份單獨(dú)恢復(fù)某一個(gè)頁(yè)面。
這里有幾個(gè)例外:
- 追加寫的系統(tǒng)沒(méi)有這個(gè)問(wèn)題;
- 如果頁(yè)面大小和扇區(qū)大小相同,也沒(méi)有這個(gè)問(wèn)題,很多元數(shù)據(jù)設(shè)計(jì)都會(huì)考慮這點(diǎn);
- 很多文件系統(tǒng)或分布式文件系統(tǒng),raid卡,或者磁盤本身也可以處理這個(gè)故障,如果使用能自處理半寫故障的硬件,數(shù)據(jù)庫(kù)就可以不開(kāi)啟這個(gè)功能;
磁盤寫滿
磁盤寫滿這種問(wèn)題只能通過(guò)運(yùn)維手段解決,因?yàn)閿?shù)據(jù)庫(kù)事務(wù)提交必須寫日志,如果無(wú)法寫日志,那么任何事務(wù)都不能提交,相當(dāng)于停庫(kù),因此應(yīng)對(duì)磁盤故障一般是通過(guò)監(jiān)控,在磁盤空間即將不足時(shí)提前預(yù)警。
磁盤損壞
如上文所說(shuō),數(shù)據(jù)庫(kù)恢復(fù)需要一份完整的數(shù)據(jù)和日志,因此,如果數(shù)據(jù)或者日志遇到了磁盤損壞,日志系統(tǒng)是無(wú)法恢復(fù),只能依賴其他的方式了。
備份
按照級(jí)別劃分,常見(jiàn)的備份方式有:
- 全量備份:傳統(tǒng)數(shù)據(jù)庫(kù)全量備份通常的做法是首先做一次checkpoint,然后將所有的數(shù)據(jù)和checkpoint點(diǎn)之后的日志拷貝走,如果數(shù)據(jù)量很多,這是一次很重的操作;
- 增量備份:增量備份同樣需要做一次checkpoint,然后將上一次備份后變化的頁(yè)面和checkpoint點(diǎn)之后的日志拷貝走,如何找到上一次備份之后變化的頁(yè)面,做全量頁(yè)面比對(duì)是一種方法,通過(guò)bitmap文件記錄頁(yè)面變化也是一種方法,percona就實(shí)現(xiàn)了第二種方法;增量備份往往是可以疊加的,也是可以合并的,全量備份和增量備份也可以按時(shí)間順序合并。
- 日志歸檔:日志歸檔指的是將制定的日志定時(shí)歸檔;
很顯然,從上述操作的開(kāi)銷從大到小排列依次是,全量備份>增量備份>日志歸檔。數(shù)據(jù)庫(kù)運(yùn)維時(shí)往往會(huì)結(jié)合這三種方式,以達(dá)到縮小故障RPO的目標(biāo)。
amazon aurora實(shí)現(xiàn)了近實(shí)時(shí)備份的功能,備份時(shí)間不超過(guò)5分鐘。
多機(jī)熱備
如果某臺(tái)機(jī)器因此各種原因發(fā)生了故障,比如cpu燒毀,內(nèi)存故障,或者操作系統(tǒng)bug,甚至被炸掉了,都可以使用備份的方式恢復(fù)。
但是通過(guò)備份恢復(fù)往往耗時(shí)較長(zhǎng),不能滿足業(yè)務(wù)連續(xù)性(Business Continuity)的需求,除了備份以外,數(shù)據(jù)庫(kù)都支持單機(jī)熱備,以及支持只讀查詢的備機(jī)。
很明顯,備機(jī)要根據(jù)故障域和客戶的要求,進(jìn)行反親和部署。
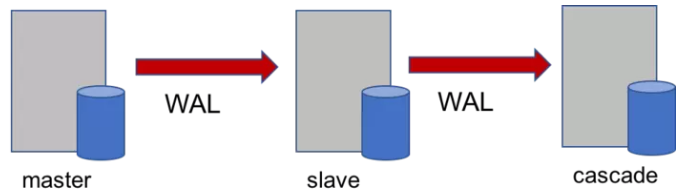
master-slave(-cascade)
每個(gè)主機(jī)可以掛多個(gè)備機(jī),每個(gè)備機(jī)可以掛多個(gè)級(jí)連備,這是當(dāng)前傳統(tǒng)數(shù)據(jù)庫(kù)的常見(jiàn)部署方式。postgres甚至支持多級(jí)的級(jí)連備(次級(jí)連)等等,但是不是很常用。這種部署方式可以有效的處理單機(jī)故障。作為支持只讀操作的備機(jī),可以有效的分?jǐn)傋x負(fù)載,這是一種有延遲的讀操作,本身也是滿足相應(yīng)隔離級(jí)別的,但是和主機(jī)放在一起考慮的話,并沒(méi)有一致性可言。
事務(wù)提交時(shí)機(jī)
根據(jù)主機(jī)事務(wù)的提交時(shí)機(jī),有幾種事務(wù)提交級(jí)別:
主機(jī)日志落盤,此時(shí)RTO<1min,RPO>0
主機(jī)日志落盤,同時(shí)主機(jī)日志發(fā)送到備機(jī),此時(shí)RTO<1min,RPO=0
主機(jī)日志落盤,同時(shí)主機(jī)日志發(fā)送到備機(jī),并且落盤,此時(shí)RTO<1min,RPO=0
這三種提交級(jí)別,主機(jī)性能越來(lái)越差,一般而言,同城備機(jī)采用第二種方式,異地備機(jī)使用***種方式。
共享磁盤
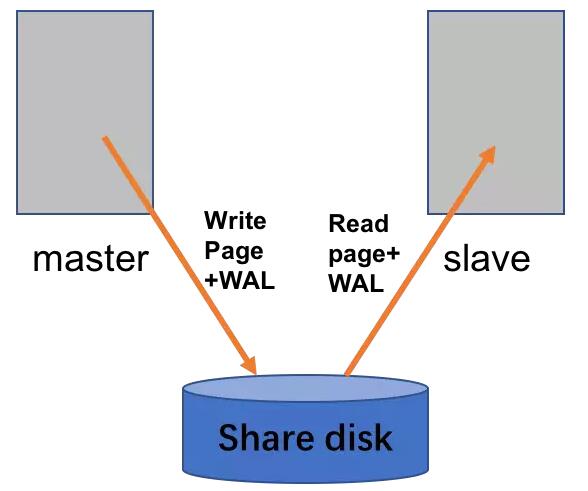
共享磁盤方案依賴共享存儲(chǔ),備機(jī)只讀不寫,雖然備機(jī)不寫盤,但仍然需要不斷的在內(nèi)存replay日志,以便主機(jī)故障后能快速升主。
很明顯,share disk方案性能類似數(shù)據(jù)單機(jī),而且RTO<1min,RPO=0。但是受硬件限制,sharding disk方案只適用于同城。
技術(shù)是螺旋式前進(jìn)的,在分布式計(jì)算中,share disk的思想也很流行,很多系統(tǒng)依賴分布式文件系統(tǒng)/存儲(chǔ)系統(tǒng),在其上構(gòu)建基于share disk的計(jì)算系統(tǒng),比如大數(shù)據(jù)領(lǐng)域久負(fù)盛名的hadoop,還有OLTP領(lǐng)域的新力量aurora,還有newsql領(lǐng)域的tidb+tikv。
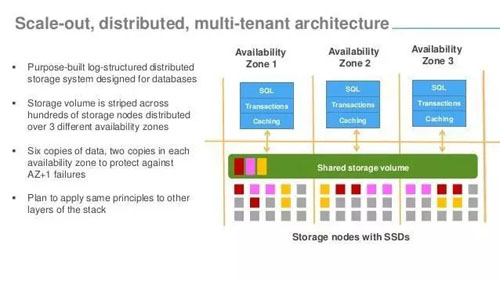
master-master
master-master架構(gòu)服務(wù)也很多,日漸成為主流,目前低一致性的大數(shù)據(jù)系統(tǒng)幾乎都是多主架構(gòu),筆者對(duì)大數(shù)據(jù)不夠熟悉,這里只列一致性較強(qiáng)的一些數(shù)據(jù)庫(kù)系統(tǒng)
- 傳統(tǒng)領(lǐng)域,oracle RAC,IBM purescale;
- sharding中間件,很多互聯(lián)網(wǎng)公司都開(kāi)發(fā)屬于自己的中間件,比如騰訊tdsql,阿里DRDS,中興GoldenDB,開(kāi)源的方案也有很多,像pg-xc,pg-xl,mycat等等,中間件方案符合互聯(lián)網(wǎng)場(chǎng)景,技術(shù)門檻低,對(duì)用戶限制大;
- fdw(foreign-data wrapper),這也是一種類似sharding的方案,目前oracle和pg采用這種方案,將外部數(shù)據(jù)源直接映射為本地表,限制也很多,比如外部表的統(tǒng)計(jì)信息很難抽取等等;
- mysql group replication,使用paxos作為復(fù)制協(xié)議,結(jié)合傳統(tǒng)數(shù)據(jù)庫(kù)做出了新的探索;
- 類spanner架構(gòu),商業(yè)數(shù)據(jù)庫(kù)有spanner和oceanbase,開(kāi)源數(shù)據(jù)庫(kù)有tidb和cockroach;
master-master架構(gòu)的系統(tǒng),總有數(shù)據(jù)是可以提供服務(wù)的,因此可靠性更高,這是當(dāng)前分布式系統(tǒng)的主流方案。
paxos/raft
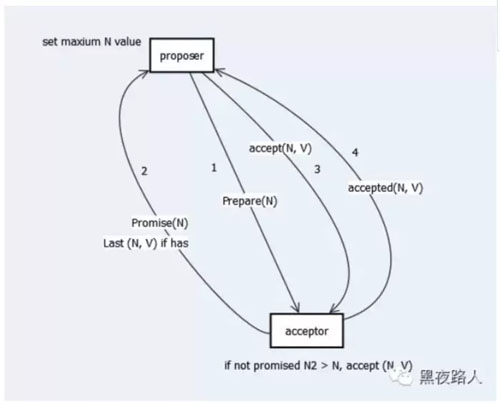
paxos/raft是當(dāng)前主流的分布式復(fù)制協(xié)議。
paxos協(xié)議精確定義了在分布式系統(tǒng)下達(dá)成共識(shí)的最小條件。關(guān)于paxos的原理可以參考這篇文章《一步一步理解Paxos算法》。
paxos是分布式系統(tǒng)的核心之一,關(guān)于這個(gè)算法給予再多的贊譽(yù)也不為過(guò)。paxos協(xié)議有很多變種,他的應(yīng)用也是有一些主要注意的地方,《SRE: google運(yùn)維解密》內(nèi)23章討論了paxos應(yīng)用的一些場(chǎng)景和情況,有興趣的可以了解一下。
一些工程可靠性手段
系統(tǒng)調(diào)用
什么樣的系統(tǒng)調(diào)用是可靠的?幾乎沒(méi)有,c語(yǔ)言中最容易出問(wèn)題的系統(tǒng)調(diào)用就是malloc,因?yàn)槭褂玫奶珡V泛了,在有些較深的代碼邏輯內(nèi),一旦申請(qǐng)內(nèi)存出錯(cuò),處理相當(dāng)棘手。在某個(gè)重要的內(nèi)閉的模塊中,首先申請(qǐng)足夠的內(nèi)存是一個(gè)比較好的做法,相當(dāng)于半自管理的內(nèi)存。
其次容易出錯(cuò)的系統(tǒng)調(diào)用是和IO相關(guān)的調(diào)用,比如IO調(diào)用出錯(cuò)更難處理的是IO變慢,讀寫操作的速度在故障時(shí)是完全不不能有任何期待的,幾十秒,幾分鐘甚至更久都很正常,所以,如果自旋鎖內(nèi)包含一個(gè)IO操作,這個(gè)系統(tǒng)離崩潰就不遠(yuǎn)了。
凡是跨網(wǎng)絡(luò)的操作,對(duì)網(wǎng)絡(luò)不要有任何期待,在操作前,釋放所有不必要持有的資源,并做好調(diào)用出錯(cuò)的準(zhǔn)備,并為其設(shè)定一個(gè)超時(shí)時(shí)間,改為異步模式是一個(gè)好選擇。
checksum
如果由于外部破壞或bug等原因?qū)е聰?shù)據(jù)損壞,可以通過(guò)checksum的方式探查,checksum一般在如下兩個(gè)時(shí)機(jī)應(yīng)用:
數(shù)據(jù)刷盤時(shí)計(jì)算,并同時(shí)記錄到磁盤上;
數(shù)據(jù)讀取時(shí)校驗(yàn);
磁盤心跳/連接心跳
進(jìn)程卡死是不可避免的,當(dāng)系統(tǒng)cpu被占滿時(shí),或者由于某些bug,可能導(dǎo)致某些關(guān)鍵進(jìn)程得不到調(diào)度,導(dǎo)致其無(wú)法傳遞某些信息,某些故障可能對(duì)整個(gè)系統(tǒng)都是致命。
如何偵測(cè)進(jìn)程/線程卡斯,有兩種常用的做法:
維護(hù)磁盤心跳,比如定期touch某個(gè)文件,如果長(zhǎng)時(shí)間文件的時(shí)間戳沒(méi)有變化,表示該程序卡死;
提供接口供外部程序訪問(wèn),外部程序定期訪問(wèn)該進(jìn)程,如果長(zhǎng)時(shí)間得不到回應(yīng),可以認(rèn)為程序卡死;
對(duì)于bug導(dǎo)致的程序卡死,往往殺掉進(jìn)程重新拉起可以解決。
調(diào)度/隊(duì)列/優(yōu)先級(jí)/流控
系統(tǒng)性能是很難做到線性提升的,對(duì)于數(shù)據(jù)庫(kù)來(lái)說(shuō),更是不可能,對(duì)于大部分?jǐn)?shù)據(jù)庫(kù)系統(tǒng)來(lái)說(shuō),性能首先隨連接數(shù)增加而提升到某個(gè)點(diǎn),繼續(xù)增加連接數(shù),往往性能會(huì)下降,
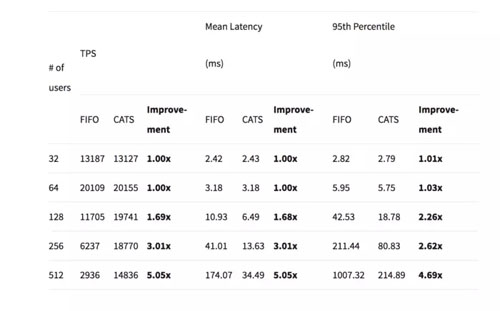
上圖是mysql8.0.3 CATS特性的性能測(cè)試結(jié)果,明顯可以看到超過(guò)64連接后,性能隨著連接數(shù)增加而降低。
這也是數(shù)據(jù)庫(kù)系統(tǒng)一般都會(huì)做連接池的原因。
過(guò)量的壓力可能導(dǎo)致系統(tǒng)崩潰,比如上圖,F(xiàn)IFO的調(diào)度方式下,512連接,性能降低接近5倍。因此在大型系統(tǒng)中,連接池和優(yōu)先級(jí)隊(duì)列是一個(gè)好設(shè)計(jì),可以方便對(duì)系統(tǒng)的壓力進(jìn)行有效控制,同時(shí)通過(guò)監(jiān)控隊(duì)列長(zhǎng)度,可以直觀看到這部分系統(tǒng)的壓力和處理能力。
異地備份
主流的高可用方案有兩種,一種是兩地三中心,一種是異地多活。
兩地三中心
對(duì)于傳統(tǒng)數(shù)據(jù)庫(kù),兩地三中心的方案比較常見(jiàn),常見(jiàn)的部署是同城兩中心,異地一中心
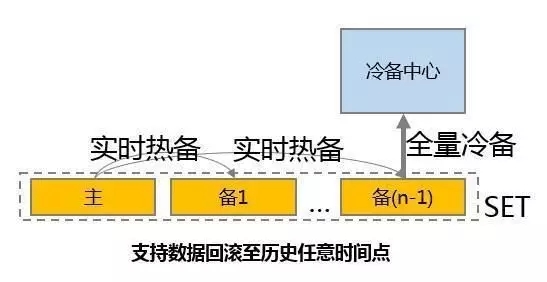
兩地三中心是一個(gè)初級(jí)和簡(jiǎn)單的部署架構(gòu),一旦主庫(kù)發(fā)生故障,異地中心很難頂上,只能起到冷備的作用:
- 一般而言,應(yīng)用距離主庫(kù)較近,異地網(wǎng)絡(luò)延時(shí)大,性能往往不如主庫(kù);
- 異地中心往往較本地中心硬件條件差,無(wú)論是帶寬還是時(shí)延,未必滿足應(yīng)用的需求;
- 異地中心不能提供服務(wù),浪費(fèi)資源;
- 如果不經(jīng)常做主備切換,一旦發(fā)生故障,往往異地中心會(huì)出現(xiàn)各種問(wèn)題,上文中寧夏銀行在故障前一年就做過(guò)故障演練,但是一年不練,真的發(fā)生故障時(shí),會(huì)出現(xiàn)各種問(wèn)題。
還有一種共有云上可靠性更高的方案,如下圖
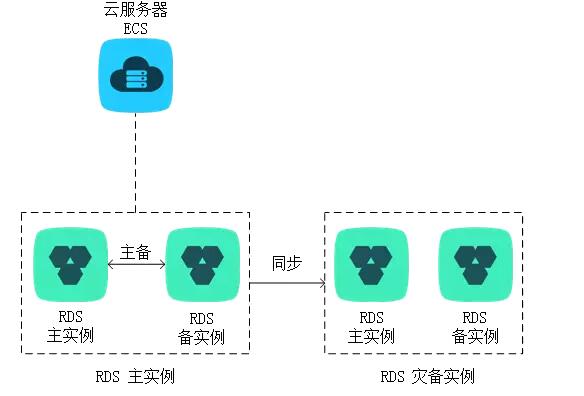
有錢任性。當(dāng)然,公有云海量部署可以攤低成本,在私有云上,這種方案更貴。
paxos并不適合兩地三中心的部署,paxos協(xié)議要求有3個(gè)對(duì)等的故障域,并且能處理一個(gè)故障域的故障,兩地三中心故障域并不對(duì)等
同城復(fù)制快,異地復(fù)制慢,性能受很大影響;
同城兩中心在地質(zhì)災(zāi)害時(shí)會(huì)同時(shí)故障,paxos不能處理;
異地多活
異地多活方案主要要考慮如下幾個(gè)問(wèn)題:
- 系統(tǒng)資源分配在異地條件下是否存在問(wèn)題;
- 故障自閉,任意數(shù)據(jù)中心間斷網(wǎng)造成的區(qū)域隔斷是否會(huì)導(dǎo)致系統(tǒng)不可用,尤其注意當(dāng)某個(gè)數(shù)據(jù)中心故障時(shí),流控系統(tǒng)往往會(huì)立刻就將壓力導(dǎo)入到其他可用區(qū)域,可能會(huì)立刻導(dǎo)致系統(tǒng)過(guò)載;
- 數(shù)據(jù)中心間數(shù)據(jù)同步性能是否可以滿足需要;
數(shù)據(jù)中心是及其昂貴的,一旦整個(gè)數(shù)據(jù)中心發(fā)生故障,作為服務(wù)整體服務(wù)質(zhì)量不降級(jí)是不可能的,如何優(yōu)雅降級(jí)并保證盡可能多的數(shù)據(jù)可用,這是分布式系統(tǒng)需要重點(diǎn)考慮的問(wèn)題。
以google spanner為例,時(shí)間戳分配是分布式的,不需要中心節(jié)點(diǎn),數(shù)據(jù)可以由用戶選擇部署方式,橫跨數(shù)據(jù)中心越多,性能越差,可靠性越強(qiáng),區(qū)域故障完全自閉,不影響其他部分。
異地多活是一項(xiàng)系統(tǒng)工程,在這個(gè)龐大工程里,數(shù)據(jù)庫(kù)只需要做好自己的事就可以了。
參考資料
《SRE: google運(yùn)維解密》
來(lái)自 Google 的高可用架構(gòu)理念與實(shí)踐
《the tail at scale》
Hard disk drive failure
CAP理論
The Log: What every software engineer should know about real-time data’s unifying abstraction
WAL Internals Of PostgreSQL
AWS re:Invent 2016: Getting Started with Amazon Aurora (DAT203)
一步一步理解Paxos算法
cloudharmony數(shù)據(jù)中心監(jiān)控