













譯者 | 康少京
審校 | 孫淑娟
隔離定義為在數據庫并發執行多個事務時,不會影響到其他事務的執行。本文將解釋這些隔離級別,并概述它們之間的權衡。我們還建議選擇最適合您需求的隔離級別。
讓我們從有效使用隔離級別所需的最低知識開始,研究表示大多數應用程序的兩個用例及其對不同隔離級別的影響。
用例1:銀行交易
客戶從銀行賬戶取錢:
- 開始交易;
- 讀取用戶余額;
- 在活動表中創建一行(我們避免將其稱為事務,以避免與數據庫事務混淆);
- 從讀取的金額中減去提款金額后,更新用戶的余額;
- 提交。
在交易完成之前,我們不希望用戶的余額發生變化。
用例2:零售交易
國際客戶從零售店購買物品時使用的貨幣與標價不同:
- 開始交易;
- 讀取exchange_rate表,獲取最新的兌換率;
- 在訂單表中創建一行;
- 提交。
假設有一個單獨的過程正在不斷更新匯率,但我們不關心匯率在讀取之后是否會發生變化,即使當前交易還沒有完成。
可序列化
Serializable隔離級別是唯一滿足ACID屬性理論定義的級別。它從本質上說,兩個并發事務不允許相互干擾對方的更改,如果一個接一個地執行,則必須產生相同的結果。
不幸的是,Serializable通常被認為是不切實際的,即使對于非分布式數據庫。所有現有的流行數據庫(如Postgres和MySQL)都不推薦它,這并不是巧合。
為什么這個設置如此不切實際?讓我們來看看兩個用例:
在銀行用例中,Serializable是完美的。在讀取用戶余額后,數據庫保證用戶余額不會改變。因此,應用業務邏輯是安全的,例如確保用戶有足夠的余額,并根據讀取的值寫入新的余額。在銀行用例中,Serializable是完美的。
在零售用例中,Serializable也可以正常工作。在創建訂單的事務成功之前,不允許更新匯率的流程執行其操作。
由于事件的精確順序,這聽起來像是一個很棒的功能。但是,如果創建訂單的交易緩慢又復雜怎么辦?也許它需要去倉庫檢查庫存。也許它必須對下訂單的用戶進行信用檢查。它將持有該行上的鎖,防止匯率進程更新。這種意想不到的依賴關系可能會阻止系統擴展。
Serializable設置也會經常出現死鎖。例如,如果兩個事務讀取一個用戶的余額,它們將在該行上放置一個共享讀取鎖。如果事務稍后修改該行,它們將嘗試將讀鎖升級為寫鎖。這將導致死鎖,因為每個事務都將被另一個事務持有的讀鎖阻塞。正如我們將在下面看到的,不同的隔離級別可以很容易地避免這個問題。
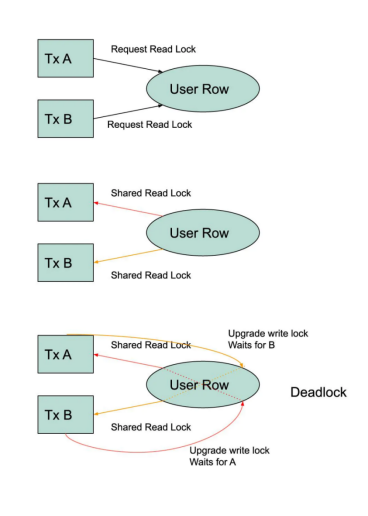
換句話說,有爭議的工作負載將無法使用Serializable設置進行擴展。如果工作負載沒有爭議,我們就不需要這個隔離級別。較低的隔離可能同樣有效。
為了解決這種不必要且昂貴的安全問題,必須重構應用程序。例如,獲取匯率的代碼在事務開始之前調用,或者使用單獨的連接來完成讀取程序。
雖然理論上沒有那么純粹,但其他隔離級別允許您在個案的基礎上執行序列化讀取。這使得它們在編寫可伸縮系統時更加靈活和實用。
無鎖定實現
有一些方法可以在不鎖定數據的情況下提供可序列化的一致性。然而,這類系統也會遇到上述相同的問題,即沖突交易的失敗方式不同。問題的根本原因在于隔離級別本身,任何實現都無法讓您擺脫這些約束。
重復讀
RepeatableRead是一個模糊的設置。因為它區分了點選擇和搜索,并為每個點定義了不同的行為。這不是非黑即白的,并導致了許多其他實現。這里就不詳細討論這個隔離級別。然而,就我們的用例而言,RepeatableRead提供了與Serializable相同的保證,因此繼承了相同的問題。
快照讀
SnapshotRead隔離級別雖然不是ANSI標準,但已經越來越流行了。也被稱為MVCC。這種隔離級別的優點是無爭用:它在事務開始時創建一個快照。所有讀取都發送到該快照,而不獲取任何鎖。但寫操作遵循嚴格的可序列化規則。
SnapshotRead事務對于只讀工作負載最有價值,因為您可以看到一致的數據庫快照。這避免了在加載事務上相互依賴的不同數據片段時出現意外。還可以使用快照功能在特定時間讀取多個表,然后觀察自該快照以來發生的更改。對于希望將更改流式傳輸到分析數據庫的更改數據捕獲工具,這個功能非常方便。
對于執行寫入的事務,快照特性不是很有用。您主要想控制是否允許在上次讀取后更改值。如果您想允許該值更改,它將在您閱讀后立即失效,因為其他人可以稍后對其進行更新。因此,無論您是從快照讀取還是獲取最新值,這都沒有關系。如果不希望更改,則需要最新的值,并且必須鎖定行以防止更改。
換句話說,SnapshotRead對于只讀工作負載很有用,但對于寫工作負載來說,它并不比ReadCommitted好,我們將在下面介紹。
在此隔離級別中重新應用Retail用例可以很自然地工作,不會產生爭用:從匯率中讀取的值產生了創建事務時快照的值。在進行此交易時,允許單獨的交易來更新匯率。
銀行用例如何?數據庫允許您對數據進行鎖定。例如,MySQL能夠“在共享模式下選擇…鎖定”(讀鎖)。此模式將讀取升級為可序列化事務的讀取。當然,還繼承了此隔離級別的死鎖風險。
較低的隔離級別可以兩全其美。您可以發出一個“select…for update”(寫鎖)。此鎖阻止另一個事務獲取此行上的任何類型的鎖。這種悲觀鎖定方法一開始聽起來很糟糕,但它允許兩個競爭事務成功完成,而不會遇到死鎖。第二個事務將等待第一個事務完成,此時它將讀取并鎖定新值所在的行。
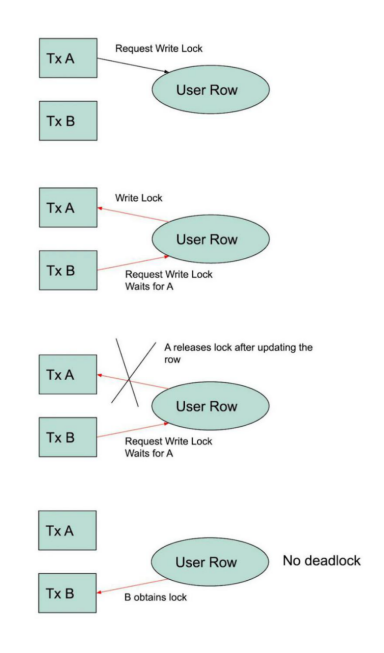
MySQL默認支持SnapshotRead隔離級別,但會將其稱為REPEATABLE_READ。
分布式數據庫
雖然單個數據庫有多種有效實現可重復讀取的方法,但在分布式數據庫中,問題變得更加復雜。這是因為事務可以跨越多個碎片。如果是這樣,系統必須提供嚴格的訂購保證。這種排序要求系統使用集中的并發控制機制或全局一致的時鐘。這兩種方法本質上都試圖將原本可以彼此獨立執行的事件緊密耦合起來。
因此,在希望分布式數據庫支持分布式快照讀取之前,必須了解并愿意接受這些權衡。
已提交
ReadCommitted隔離比SnapshotRead更明確,因為它不斷返回數據庫的最新視圖。這也是隔離級別中爭議最小的。在這個級別上,每次讀取一行時可能會得到不同的值。
ReadCommitted設置還允許您通過發出讀或寫鎖定來升級讀取,從而有效地允許您按需執行可序列化讀取。正如前面所說的,對于打算修改數據的應用程序事務,這種方法提供了兩全其美的解決方案。
Postgres支持的默認隔離級別是ReadCommitted。
讀取未提交
這種隔離級別通常被認為是不安全的,不建議用于分布式或非分布式設置。這是因為您可能會讀取稍后可能回滾的數據(或者從一開始就不存在的數據)。
分布式事務
這個主題與隔離級別是正交的,但這里必須涵蓋這一點,因為它在保持事物的松散耦合方面具有重要意義。
在分布式系統中,如果兩行位于不同的碎片或數據庫中,并且您希望在單個事務中原子化地修改它們,則會產生兩階段提交(2PC)的開銷。
這需要更多的工作:
- 創建關于分布式事務的元數據并保存到持久存儲中。
- 對所有單個交易發布準備。
- 提交的決策保存到元數據中。
- 向準備好的事務發出提交。
prepare要求您保存元數據,以便在提交(或回滾)前,如果節點發生崩潰,可以在新的leader中恢復事務。
分布式事務還與隔離級別交互。例如,假設只有2PC事務的第一次提交成功,第二次提交被延遲。如果應用程序已經讀取了第一次提交的效果,那么數據庫必須阻止應用程序讀取第二次提交的行,直到完成。反過來說,如果應用程序在第二次提交之前讀取了一行,那么它肯定看不到第一次提交的效果。
數據庫必須做額外的工作來支持分布式事務的隔離保證。如果應用程序可以容忍這些部分提交呢?然后,我們就做了應用程序不關心的不必要的工作。可能值得引入一個新的隔離級別,如ReadPartialCommits。請注意,這不同于ReadUncommitted,用戶讀取的數據最終可能被回滾。
最后,過度使用2PC會降低系統的整體可用性和延遲。這是因為性能最差的碎片將決定您的有效可用性。
總結
為了具有可伸縮性,應用程序應該避免依賴數據庫的任何高級隔離功能。相反,它應該盡可能少地使用擔保。如果可以編寫一個應用程序來使用ReadCommitted隔離級別,那么不建議遷移到SnapshotRead。Serializable或RepeatableRead。
最好避免多語句事務,但隨著應用程序的發展,這可能會不可避免。此時,嘗試主要依賴事務的原子保證,并保持數據庫系統支持的最低隔離級別。
如果使用分片數據庫,請完全避免分布式事務。這可以通過將相關行保留在同一個碎片中來實現。必須從一開始就這樣做,因為很難將非并發程序重構為并發程序。
譯者介紹
康少京,51CTO社區編輯,從事通訊類行業,底層驅動開發崗位。
原文標題:??Optimizing Isolation Levels for Scaling Distributed Databases??,作者:Sugu Sougoumarane
























