基于Hadoop的大數據平臺實施——整體架構設計
大數據的熱度在持續(xù)的升溫,繼云計算之后大數據成為又一大眾所追捧的新星。我們暫不去討論大數據到底是否適用于您的公司或組織,至少在互聯(lián)網上已經被吹噓成無所不能的超級戰(zhàn)艦。好像一夜之間我們就從互聯(lián)網時代跳躍進了大數據時代!關于到底什么是大數據,說真的,到目前為止就和云計算一樣,讓我總覺得像是在看電影《云圖》——云里霧里的感覺。或許那些正在向你推銷大數據產品的公司會對您描繪一幅烏托邦似的美麗畫面,但是您至少要保持清醒的頭腦,認真仔細的慎問一下自己,我們公司真的需要大數據嗎?
做為一家第三方支付公司,數據的確是公司最最重要的核心資產。由于公司成立不久,隨著業(yè)務的迅速發(fā)展,交易數據呈幾何級增加,隨之而來的是系統(tǒng)的不堪重負。業(yè)務部門、領導、甚至是集團老總整天嚷嚷的要報表、要分析、要提升競爭力。而研發(fā)部門能做的唯一事情就是執(zhí)行一條一條復雜到自己都難以想象的SQL語句,緊接著系統(tǒng)開始罷工,內存溢出,宕機........簡直就是噩夢。OMG!please release me!!!
其實數據部門的壓力可以說是常人難以想象的,為了把所有離散的數據匯總成有價值的報告,可能會需要幾個星期的時間或是更長。這顯然和業(yè)務部門要求的快速響應理念是格格不入的。俗話說,工欲善其事,必先利其器。我們也該鳥槍換炮了......。
網上有一大堆文章描述著大數據的種種好處,也有一大群人不厭其煩的說著自己對大數據的種種體驗,不過我想問一句,到底有多少人多少組織真的在做大數據?實際的效果又如何?真的給公司帶來價值了?是否可以將價值量化?關于這些問題,好像沒看到有多少評論會涉及,可能是大數據太新了(其實底層的概念并非新事物,老酒裝新瓶罷了),以至于人們還沉浸在各種美妙的YY中。
做為一名嚴謹的技術人員,在經過短暫盲目的崇拜之后,應該快速的進入落地應用的研究中,這也是踩著“云彩”的架構師和騎著自行車的架構師的本質區(qū)別。說了一些牢騷話,當做發(fā)泄也好,博眼球也好,總之,我想表達的其實很簡單:不要被新事物所迷惑,也不要盲目的崇拜任何一樣新事物,更不要人云亦云,這是我們做研究的人絕對要不得。
說了很多也是時候進入正題了。公司高層決定,正式在集團范圍內實施大數據平臺(還特地邀請了一些社區(qū)的高手,很期待.......),做為第三方支付公司實施大數據平臺也無可厚非,因此也積極的參與到這個項目中來。正好之前關于OSGi的企業(yè)級框架的研究也告一段落,所以想利用CSDN這個平臺將這次大數據平臺實施過程記錄下來。我想一定能為其它有類似想法的個人或公司提供很好的參考資料!
***記,大數據平臺的整體架構設計
1. 軟件架構設計
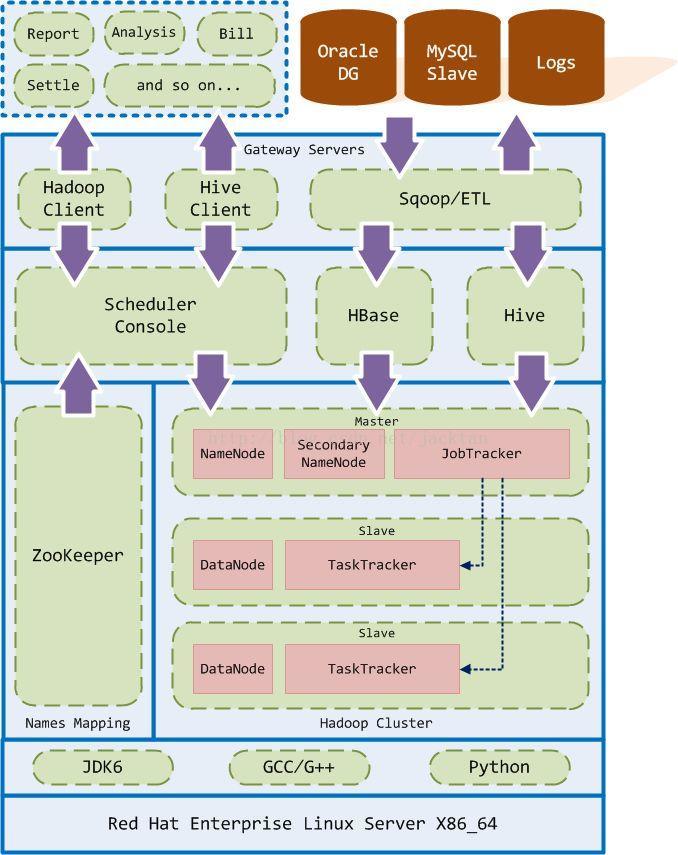
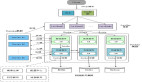
大數據平臺架構設計沿襲了分層設計的思想,將平臺所需提供的服務按照功能劃分成不同的模塊層次,每一模塊層次只與上層或下層的模塊層次進行交互(通過層次邊界的接口),避免跨層的交互,這種設計的好處是:各功能模塊的內部是高內聚的,而模塊與模塊之間是松耦合的。這種架構有利于實現平臺的高可靠性,高擴展性以及易維護性。比如,當我們需要擴容Hadoop集群時,只需要在基礎設施層添加一臺新的Hadoop節(jié)點服務器即可,而對其他模塊層無需做任何的變動,且對用戶也是完全透明的。
整個大數據平臺按其職能劃分為五個模塊層次,從下到上依次為:
運行環(huán)境層:
運行環(huán)境層為基礎設施層提供運行時環(huán)境,它由2部分構成,即操作系統(tǒng)和運行時環(huán)境。
(1)操作系統(tǒng)我們推薦安裝REHL5.0以上版本(64位)。此外為了提高磁盤的IO吞吐量,避免安裝RAID驅動,而是將分布式文件系統(tǒng)的數據目錄分布在不同的磁盤分區(qū)上,以此提高磁盤的IO性能。
(2)運行時環(huán)境的具體要求如下表:
- 名稱版本說明
- JDK1.6或以上版本Hadoop需要Java運行時環(huán)境,必須安裝JDK。
- gcc/g++3.x或以上版本當使用Hadoop Pipes運行MapReduce任務時,需要gcc編譯器,可選。
- python2.x或以上版本當使用Hadoop Streaming運行MapReduce任務時,需要python運行時,可選。
基礎設施層:
基礎設施層由2部分組成:Zookeeper集群和Hadoop集群。它為基礎平臺層提供基礎設施服務,比如命名服務、分布式文件系統(tǒng)、MapReduce等。
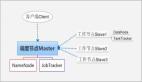
(1)ZooKeeper集群用于命名映射,做為Hadoop集群的命名服務器,基礎平臺層的任務調度控制臺可以通過命名服務器訪問Hadoop集群中的NameNode,同時具備failover的功能。
(2)Hadoop集群是大數據平臺的核心,是基礎平臺層的基礎設施。它提供了HDFS、MapReduce、JobTracker和TaskTracker等服務。目前我們采用雙主節(jié)點模式,以此避免Hadoop集群的單點故障問題。
基礎平臺層:
基礎平臺層由3個部分組成:任務調度控制臺、HBase和Hive。它為用戶網關層提供基礎服務調用接口。
(1)任務調度控制臺是MapReduce任務的調度中心,分配各種任務執(zhí)行的順序和優(yōu)先級。用戶通過調度控制臺提交作業(yè)任務,并通過用戶網關層的Hadoop客戶端返回其任務執(zhí)行的結果。其具體執(zhí)行步驟如下:
- 任務調度控制臺接收到用戶提交的作業(yè)后,匹配其調度算法;
- 請求ZooKeeper返回可用的Hadoop集群的JobTracker節(jié)點地址;
- 提交MapReduce作業(yè)任務;
- 輪詢作業(yè)任務是否完成;
- 如果作業(yè)完成發(fā)送消息并調用回調函數;
- 繼續(xù)執(zhí)行下一個作業(yè)任務。
作為一個完善的Hadoop集群實現,任務調度控制臺盡量自己開發(fā)實現,這樣靈活性和控制力會更加的強。
(2)HBase是基于Hadoop的列數據庫,為用戶提供基于表的數據訪問服務。
(3)Hive是在Hadoop上的一個查詢服務,用戶通過用戶網關層的Hive客戶端提交類SQL的查詢請求,并通過客戶端的UI查看返回的查詢結果,該接口可提供數據部門準即時的數據查詢統(tǒng)計服務。
用戶網關層:
用戶網關層用于為終端客戶提供個性化的調用接口以及用戶的身份認證,是用戶唯一可見的大數據平臺操作入口。終端用戶只有通過用戶網關層提供的接口才可以與大數據平臺進行交互。目前網關層提供了3個個性化調用接口:
- (1)Hadoop客戶端是用戶提交MapReduce作業(yè)的入口,并可從其UI界面查看返回的處理結果。
- (2)Hive客戶端是用戶提交HQL查詢服務的入口,并可從其UI界面查看查詢結果。
- (3)Sqoop是關系型數據庫與HBase或Hive交互數據的接口。可以將關系型數據庫中的數據按照要求導入到HBase或Hive中,以提供用戶可通過HQL進行查詢。同時HBase或Hive或HDFS也可以將數據導回到關系型數據庫中,以便其他的分析系統(tǒng)進行進一步的數據分析。
用戶網關層可以根據實際的需求***的擴展,以滿足不同用戶的需求。
客戶應用層:
客戶應用層是各種不同的終端應用程序,可以包括:各種關系型數據庫,報表,交易行為分析,對賬單,清結算等。
目前我能想到的可以落地到大數據平臺的應用有:
- 行為分析:將交易數據從關系型數據庫導入到Hadoop集群中,然后根據數據挖掘算法編寫MapReduce作業(yè)任務并提交到JobTracker中進行分布式計算,然后將其計算結果放入Hive中。終端用戶通過Hive客戶端提交HQL查詢統(tǒng)計分析的結果。
- 對賬單:將交易數據從關系型數據庫導入到Hadoop集群,然后根據業(yè)務規(guī)則編寫MapReduce作業(yè)任務并提交到JobTracker中進行分布式計算,終端用戶通過Hadoop客戶端提取對賬單結果文件(Hadoop本身也是一個分布式文件系統(tǒng),具備通常的文件存取能力)。
- 清結算:將銀聯(lián)文件導入HDFS中,然后將之前從關系型數據庫中導入的POSP交易數據進行MapReduce計算(即對賬操作),然后將計算結果連接到另外一個MapReduce作業(yè)中進行費率及分潤的計算(即結算操作),***將計算結果導回到關系型數據庫中由用戶觸發(fā)商戶劃款(即劃款操作)。
部署架構設計
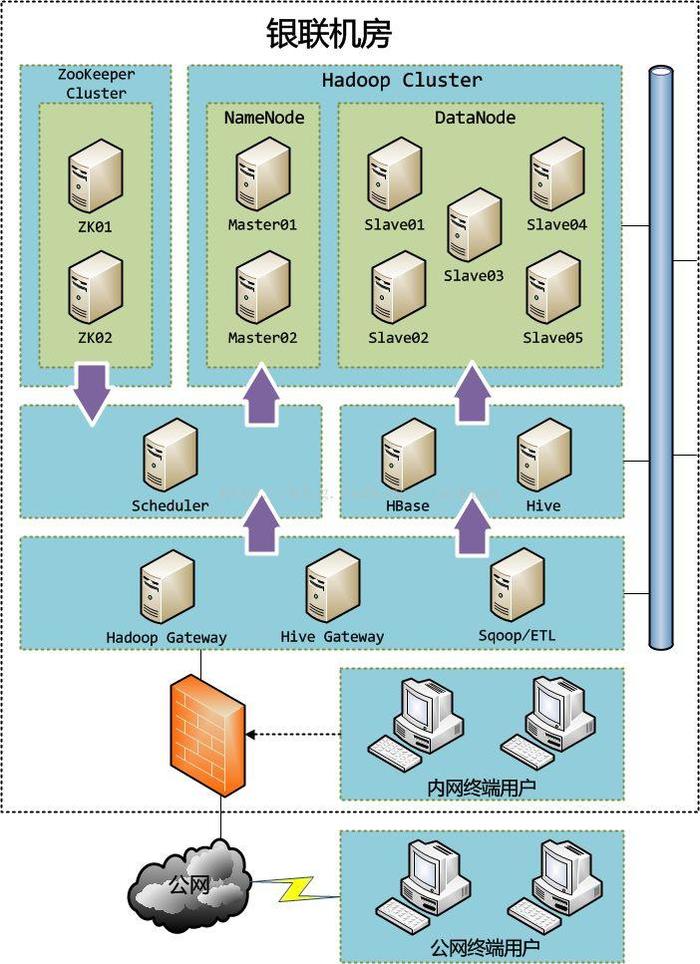
關鍵點說明:
- 目前整個Hadoop集群均放置在銀聯(lián)機房中。
- Hadoop集群中有2個Master節(jié)點和5個Slave節(jié)點,2個Master節(jié)點互為備份通過ZooKeeper可實現failover功能。每個Master節(jié)點共享所有的Slave節(jié)點,保證分布式文件系統(tǒng)的備份存在于所有的DataNode節(jié)點之中。Hadoop集群中的所有主機必須使用同一網段并放置在同一機架上,以此保證集群的IO性能。
- ZooKeeper集群至少配置2臺主機,以避免命名服務的單節(jié)點故障。通過ZooKeeper我們可以不再需要F5做負載均衡,直接由任務調度控制臺通過ZK實現Hadoop名稱節(jié)點的負載均衡訪問。
- 所有服務器之間必須配置為無密鑰SSH訪問。
- 外部或內部用戶均需要通過網關才能訪問Hadoop集群,網關在經過一些身份認證之后才能提供服務,以此保證Hadoop集群的訪問安全。