淺談深度學習的技術(shù)原理及其在計算機視覺的應用
目前,深度學習幾乎成了計算機視覺領域的標配,也是當下人工智能領域最熱門的研究方向。計算機視覺的應用場景和深度學習背后的技術(shù)原理是什么呢?下面讓我們來一探究竟。
計算機視覺的應用
什么是計算機視覺呢?形象地說,計算機視覺就是給計算機裝上眼睛(照相機)和大腦(算法),讓計算機可以感知周圍的環(huán)境。目前計算機視覺研究主要集中在基礎應用場景,像圖片分類、物體識別、人臉的3D建模等。
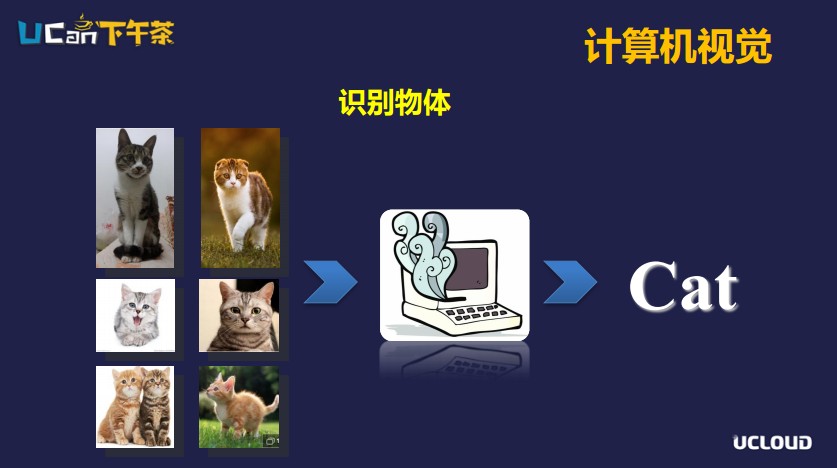
識別物體是圖片分類的一個比較常見的應用,例如一個簡單的貓咪識別模型,我們首先要給計算機定義模型,然后準備大量貓咪的照片去訓練這個模型,讓計算機能識別出來,輸一張圖片的時候能識別出圖片是不是貓咪。正常情況下計算機模型能識別得比較準確,但是當我們輸入了一些有遮擋、形態(tài)多變或者角度、光照不一的圖片時,之前我們建立的模型就識別不出來。這就是計算機視覺在應用中存在的難點問題。
深度學習背后的技術(shù)原理
機器學習
在計算機視覺領域中是怎么運用深度學習來解決問題的呢?深度學習作為機器學習的一種,這里先簡單介紹下機器學習。
機器學習的本質(zhì)其實是為了找到一個函數(shù),讓這個函數(shù)在不同的領域會發(fā)揮不同的作用。像語音識別領域,這個函數(shù)會把一段語音識別成一段文字;圖像識別的領域,這個函數(shù)會把一個圖像映射到一個分類;下圍棋的時候根據(jù)棋局和規(guī)則進行博弈;對話,是根據(jù)當前的對話生成下一段對話。
機器學習離不開學習兩個字,根據(jù)不同的學習方式,可以分為監(jiān)督學習和非監(jiān)督學習兩種方式。
監(jiān)督學習中,算法和數(shù)據(jù)是模型的核心所在。在監(jiān)督學習中最關鍵的一點是,我們對訓練的每個數(shù)據(jù)都要打上標簽,然后通過把這些訓練數(shù)據(jù)輸入到算法模型經(jīng)過反復訓練以后,每經(jīng)過一次訓練都會減少算法模型的預計輸出和標簽數(shù)據(jù)的差距。通過大量的訓練,算法模型基本上穩(wěn)定下來以后,我們就可以把這個模型在測試數(shù)據(jù)集上驗證模型的準確性。這就是整個監(jiān)督學習的過程,監(jiān)督學習目前在圖片分類上應用得比較多。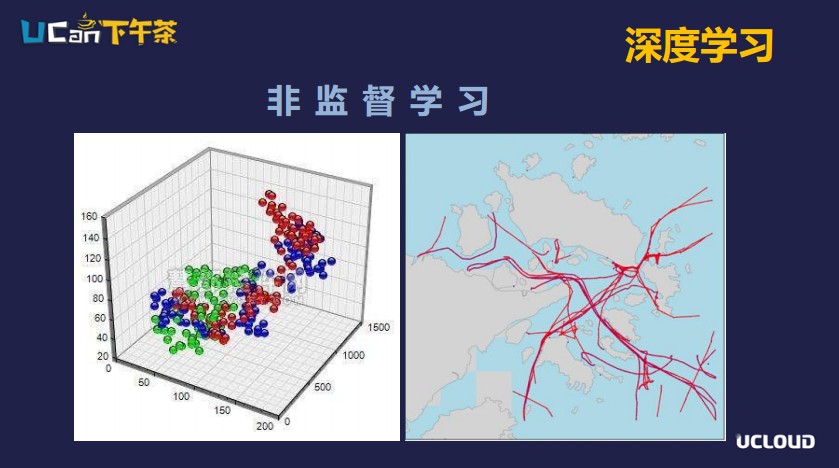
再來看非監(jiān)督學習。跟監(jiān)督學習不同的地方是,非監(jiān)督學習不需要為所有的訓練數(shù)據(jù)都打上標簽。非監(jiān)督學習主要應用在兩個大類,第一類是做聚類分析,聚類分析是把一組看似無序的數(shù)據(jù)進行分類分組,以達到能夠更加更好理解的目的;另外是做自動編碼器,在數(shù)據(jù)分析的時候,原始數(shù)據(jù)量往往比較大,除了包含一些冗余的數(shù)據(jù),還會包含一些對分析結(jié)果不重要的數(shù)據(jù)。自動編碼器主要是對原始數(shù)據(jù)做降維操作,把冗余的數(shù)據(jù)去掉,提高后面數(shù)據(jù)分析的效率。
通過不同的學習方式獲取到數(shù)據(jù)后,算法是接下來非常重要的一環(huán)。算法之于計算機就像大腦對于我們?nèi)祟悾x擇一個好的算法也是特別重要的。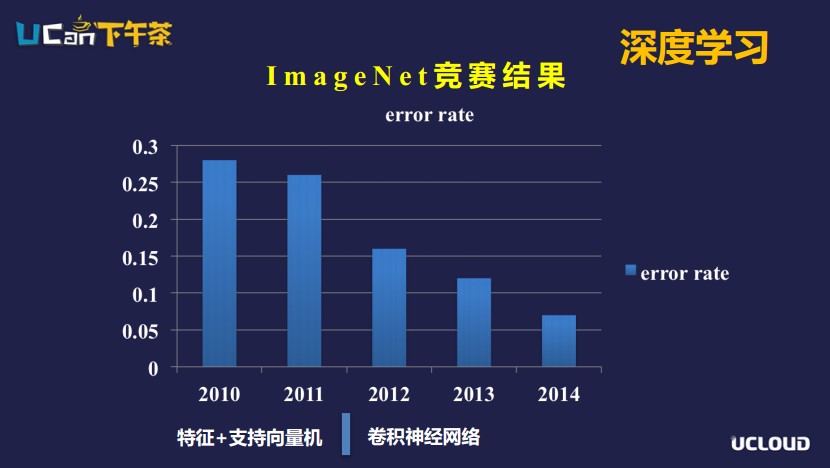
上面是ImaegNet競賽的結(jié)果,2012年以前圖片分類采用的機器學習的模型是特征+支持向量機的模型,2012年以后是卷積神經(jīng)網(wǎng)絡的模型,卷積神經(jīng)網(wǎng)絡在計算機視覺領域發(fā)揮著至關重要的作用。為什么2014年以后卷積神經(jīng)網(wǎng)絡才發(fā)揮它的作用呢?我們先來看看神經(jīng)網(wǎng)絡。
神經(jīng)網(wǎng)絡
神經(jīng)網(wǎng)絡是受人腦神經(jīng)元結(jié)構(gòu)的啟發(fā),研究者認為人腦所有的神經(jīng)元都是分層的,可以通過不同的層次學習不一樣的特征,由簡單到復雜地模擬出各種特征。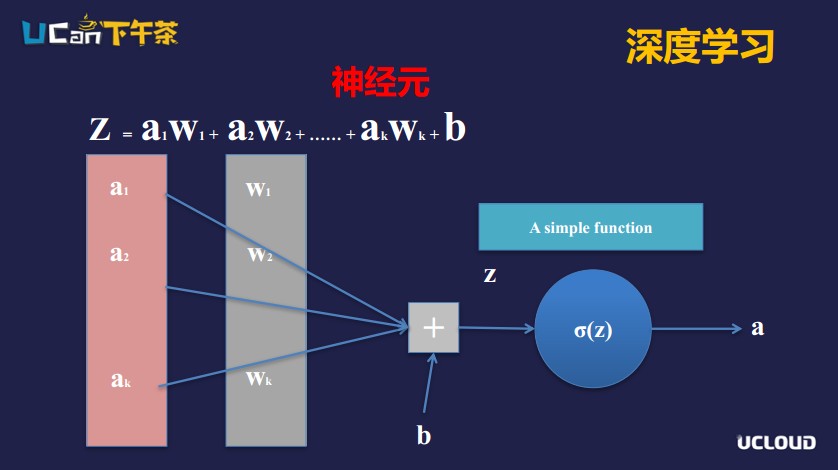
上圖是計算機應用數(shù)學的方式來模擬人腦中神經(jīng)元的示意圖。a1到ak是信號的輸入,神經(jīng)元會對輸入信號進行兩次變換。第一部分是線性變換,因為神經(jīng)元會對自己感興趣的信號加一個權(quán)重;第二部分是非線性變換。
神經(jīng)網(wǎng)絡就是由許多的神經(jīng)元級聯(lián)而形成的,每一個神經(jīng)元都經(jīng)過線性變換和非線性變換,為什么會有非線性變換?從數(shù)學上看,沒有非線性變換,不管你神經(jīng)網(wǎng)絡層次有多深都等價于一個神經(jīng)元。如果沒有非線性變換,神經(jīng)網(wǎng)絡深度的概念就沒有什么意義了。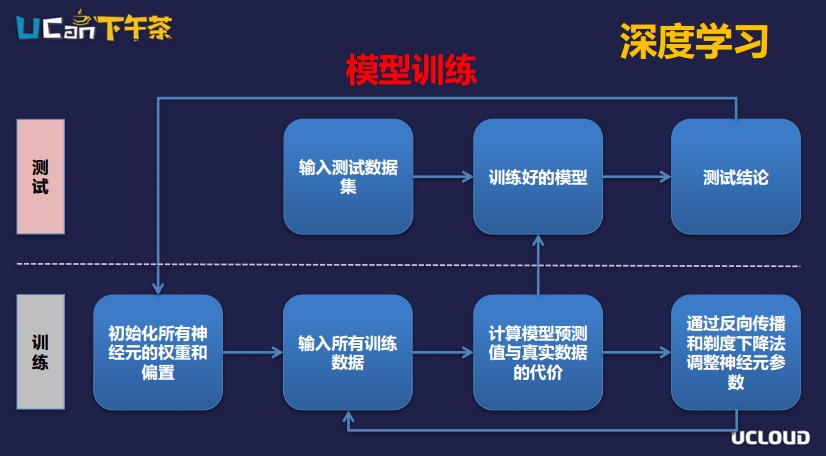
這是大家知道的神經(jīng)元網(wǎng)絡整體的模型,我們具體怎么來訓練神經(jīng)網(wǎng)絡呢?
第一步,定義一個網(wǎng)絡模型,初始化所有神經(jīng)網(wǎng)絡的權(quán)重和偏置。定義好網(wǎng)絡模型以后再定義好這個模型的代價函數(shù),代價函數(shù)就是我們的預測數(shù)據(jù)和標簽數(shù)據(jù)的差距,這個差距越小,說明模型訓練得越成功。第一次訓練的時候會初始化所有神經(jīng)元的參數(shù)。輸入所有訓練數(shù)據(jù)以后,通過當前的模型計算出所有的預測值,計算預測值以后和標簽數(shù)據(jù)比較,看一下預測值和實際值有多大的差距。
第二步,不斷優(yōu)化差距,使差距越來越小。神經(jīng)網(wǎng)絡根據(jù)導數(shù)的原理發(fā)明了反向傳播和梯度下降算法,通過N次訓練后,標簽數(shù)據(jù)與預測值之間的差距就會越來越小,直到趨于一個極致。這樣的話,所有神經(jīng)元的權(quán)重、偏置這些參數(shù)都訓練完成了,我們的模型就確定下來了。接下來就可以在測試集上用測試數(shù)據(jù)來驗證模型的準確率。
卷積神經(jīng)網(wǎng)絡
以上所講的都是一般的全連接神經(jīng)網(wǎng)絡,接下來進入卷積神經(jīng)網(wǎng)絡。卷積神經(jīng)網(wǎng)絡是專門針對圖片處理方面的神經(jīng)網(wǎng)絡。卷積神經(jīng)網(wǎng)絡首先會輸入一張圖片,這張圖片是30×30,有三個顏色通道的數(shù)據(jù),這是輸入層。下面是卷積層,有一個卷積核的概念,每一個卷積核提取圖片的不同特征。
提取出來以后到池化層,就是把卷積層的數(shù)據(jù)規(guī)模縮小,減少數(shù)據(jù)的復雜度。卷積和池化連起來我們叫做一個隱層,一個卷積神經(jīng)網(wǎng)絡會包含很多個隱層,隱層之后是全連接層,全連接層的目的是把前面經(jīng)過多個卷積池化層的特征把數(shù)據(jù)平鋪開,形成特征向量,我們把特征向量輸入到分類器,對圖片進行分類。
簡單來說,卷積神經(jīng)網(wǎng)絡更適合計算機視覺主要有兩個原因,一是參數(shù)共享,另外一個是稀疏連接。
基于深度學習的人臉識別算法模型
以上是深度學習在計算機視覺領域的相關應用以及它背后的技術(shù)原理,接下來看看基于深度學習的人臉識別算法模型。
先看一下人臉識別的應用場景,主要分三個方面:一是1:1的場景,如過安檢的時身份證和人臉比對、證券開戶;二是1:N的場景,比如說公安部要在大量的視頻中檢索犯罪嫌疑人;三是大數(shù)據(jù)分析場景,主要是表情分類,還有醫(yī)學的分析等。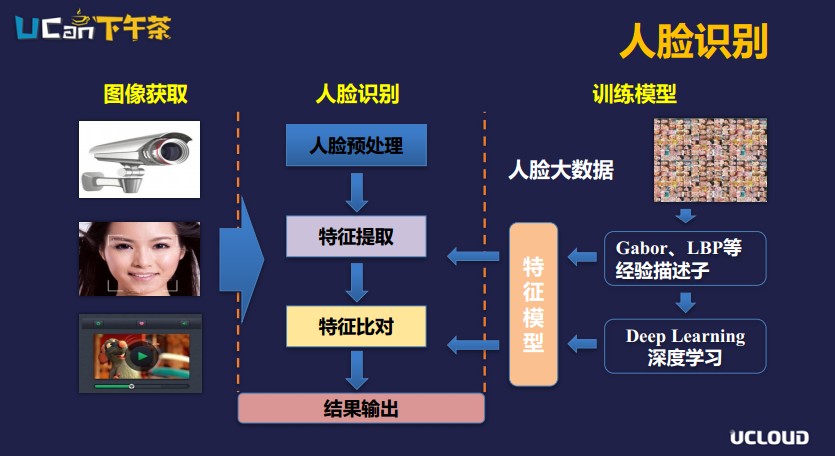
上圖主要是人臉識別簡單的流程,右邊的是訓練模型,有人臉的大數(shù)據(jù)庫,經(jīng)過Gabor、LBP等經(jīng)驗描述子,或深度學習算法提取特征模型,這個模型部署在應用上,應用通過攝像頭、視頻獲取到人臉以后做預處理,進行特征提取,特征比對,最后輸出結(jié)果,這是比較通用的人臉識別的流程。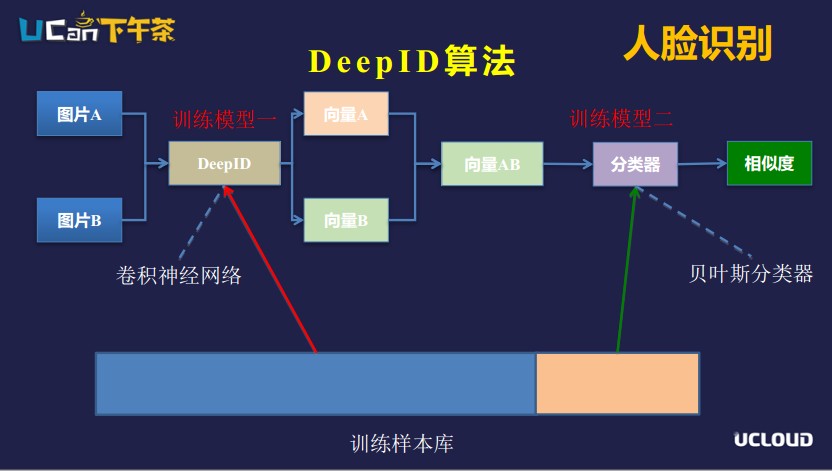
DeepID算法
DeepID算法的目的是識別兩張圖片,最后的輸出是兩張圖片的相似度。輸入圖片A和圖片B,經(jīng)過DeepID卷積神經(jīng)網(wǎng)絡模型會計算出向量A和向量B,合并成向量AB。然后將向量AB輸入分類器,算出向量AB的相似度,最后以這個相似度區(qū)分這兩個圖片是不是同一類。
這里要提到的兩個模型,一是DeepID的模型,二是分類器的模型。DeepID模型是用卷積神經(jīng)網(wǎng)絡算法訓練的,最后的應用是把卷積神經(jīng)網(wǎng)絡后面的softmax分類層去掉,得到softmax前面的特征向量;分類器模型是比較經(jīng)典的如支持向量機/聯(lián)合貝葉斯分類。訓練過程中,把訓練樣本分成五份,四份用來訓練卷積神經(jīng)網(wǎng)絡,一份用來訓練分類器,可以相互印證。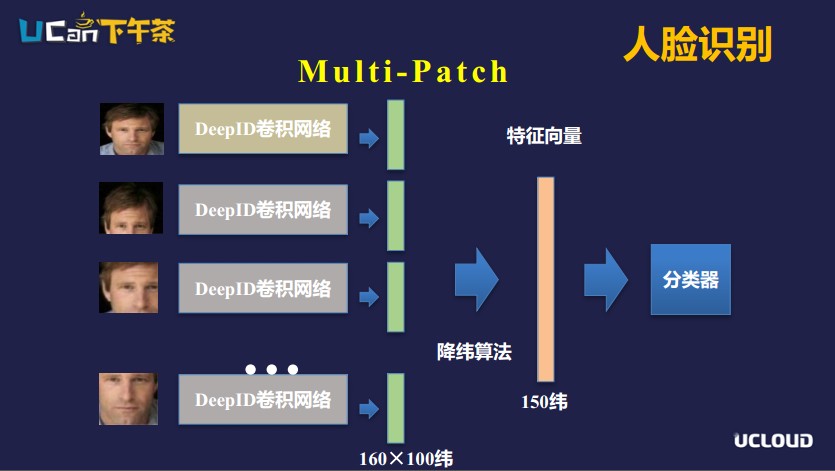
DeepID除了在網(wǎng)絡模型上做的工作,還會對圖片做預處理。像Patch的處理,按照圖片以人臉的某一個部位為中心生成固定大小的圖片,然后對每一個特定的Patch訓練卷積神經(jīng)網(wǎng)絡。一張圖片輸入后,切分成多個patch,分別輸入到對應的卷積神經(jīng)網(wǎng)絡。每一個卷積神經(jīng)網(wǎng)絡輸出一個向量,通過降維的算法,把所有patch對應的輸出向量進行處理,去除冗余信息,得到人臉的向量表示。
最后在比較兩張人臉時,就是分別將兩張人臉的這個向量輸入分類器得到相似度結(jié)果的。這里多patch切分有一個優(yōu)勢,比如在現(xiàn)實應用中有一些人的臉部是被遮擋的,由于它是分為不同的patch,這樣的場景下魯棒性會比較好。
DeepFace算法
再來看DeepFace算法。這是人臉對齊的流程,這張圖是史泰龍的側(cè)臉圖片,第一步是把人臉截取出來,對人臉上面68個基本點,描述出基本點以后,用三角剖分的算法把68個基本點連起來,然后將標準的人臉模型運用到三角剖分上,這樣標準的人臉模型就具備了這樣的深度。
經(jīng)過仿射變形后,將側(cè)臉模型轉(zhuǎn)成正臉模型,最后把這個模型應用到具體的圖片上,就得到了人的正臉圖片。這個算法的主要作用是通過一些模型將人物的側(cè)臉轉(zhuǎn)成正臉,以便做進一步的人臉識別/人臉分類 。
DeepFace神經(jīng)網(wǎng)絡如圖所示,前面三個卷積層比較普通,是用來提取臉部的一些基本特征;后面三個卷積層有一些改進,用的是參數(shù)不共享的卷積核,我們提到卷積核的基本特征有一個是參數(shù)是共享的,因為研究認為圖片中不同的部位一些基本特征是相似的。
但在這個算法中,經(jīng)過人臉對齊之后,它的不同的區(qū)域會有不同的基本特征,所以這里運用了參數(shù)不共享的卷積核。參數(shù)不共享,就不會發(fā)揮出卷積核參數(shù)少的優(yōu)勢,這樣可能增加訓練的復雜度。
FaceNet算法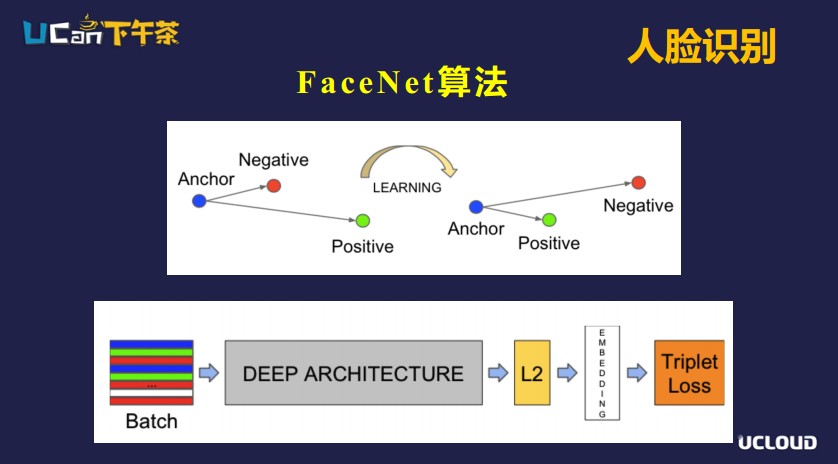
FaceNet算法是谷歌人臉識別的一種算法,F(xiàn)aceNet算法提出三元組的概念:三張圖片放在一起,兩張圖片是同一個人的,一張圖片不是同一個人的。如果一個三元組中,同一個人的圖片的距離要大于不同人之間的距離,那么經(jīng)過學習以后,這個三元組中同一個人的圖片之間的距離,會小于不同人的圖片之間的距離。它不用做分類,直接計算出兩張圖片之間的距離。
其他算法
其他算法如FR+FCN,通過神經(jīng)網(wǎng)絡去訓練,當你得到一個人側(cè)臉照的時候,可以通過神經(jīng)網(wǎng)絡生成正面照;Face+baidu是傳統(tǒng)的卷積網(wǎng)絡,建立在大數(shù)據(jù)的基礎上,訓練了數(shù)百萬張人臉。
Pose+Shape+expression augmentation,這篇論文是通過三個變量擴充數(shù)據(jù)集,讓數(shù)據(jù)搜集工作變得容易;CNN-3DMM,它在標準的3D人臉模型基礎上,訓練一個神經(jīng)網(wǎng)絡,來給標準3D模型生成不同的參數(shù),這個神經(jīng)網(wǎng)絡會根據(jù)不同的圖片生成不同的參數(shù),給個體建立不一樣的3D模型。
基于DeepID算法的人臉搜索項目
最后介紹一下我們曾做過的一個人臉識別模型的項目。活動攝影承接商需要把一些會場活動、體育賽事等活動照片拍攝下來以后上傳到他們的網(wǎng)站上,因為圖片有幾百上千張,活動參與者很難找到自己的圖片。如果用人臉識別的模型,就可以把自己的臉部拍下來上傳,在圖片集中快速找到自己的照片。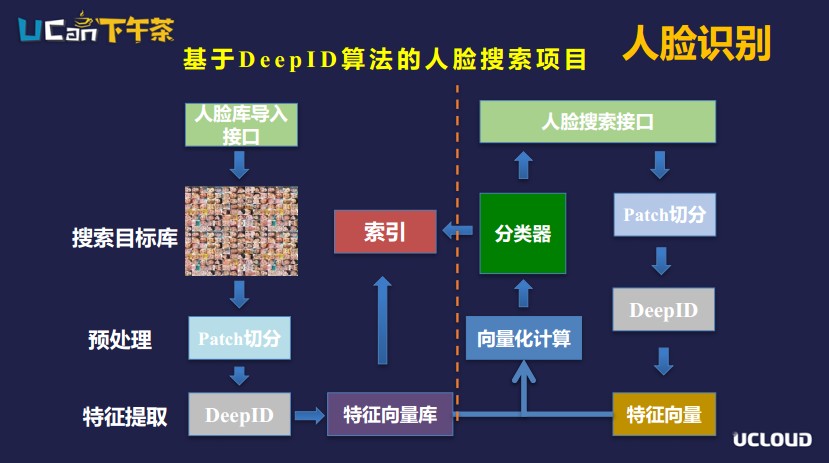
我們看一下它整體的架構(gòu)。右邊是人臉庫的導入,活動攝影承接商獎會場拍攝的一千張照片導入搜索目標庫。導入以后做多patch預處理,運用DeepID的算法,計算每張圖片各patch的特征向量,放到特征向量庫里,建立一個從特征向量到原始圖片的索引。
左邊的部分是用戶搜索,拍攝了自己的頭像后,把它上傳上來進行搜索,后臺同樣先對用戶頭像做多patch切分,通過DeepID模型計算出用戶頭像的特征向量,然后在特征向量庫中逐步比對目標特征向量,將相似度最高的N個特征向量檢索出來,最后通過索引查到原始圖片,返回給用戶。
以上是深度學習背后的技術(shù)原理以及它在計算機視覺領域常見的應用,希望通過對這些原理的解析及應用的分享,讓大家更加直觀快速地了解人工智能技術(shù)層面的基礎概念,并且對人工智能技術(shù)的學習和運用有所啟發(fā)。