1分鐘了解“挖礦”的本質(zhì)
上一篇《??1分鐘了解區(qū)塊鏈的本質(zhì)??》,介紹了什么是區(qū)塊鏈,區(qū)塊鏈?zhǔn)且粋€沒有管理員,每個節(jié)點都擁有全部數(shù)據(jù),高可用的分布式存儲系統(tǒng)。
文章的留言里,不少朋友會用比特幣來解釋區(qū)塊鏈。
那區(qū)塊鏈與比特幣是什么關(guān)系?
答:區(qū)塊鏈?zhǔn)欠植际酱鎯Γ忍貛攀腔谠摯鎯Φ膽?yīng)用,其他諸如萊特幣,以太幣都是基于區(qū)塊鏈的電子貨幣應(yīng)用。理論上,使用上層應(yīng)用來解釋底層存儲是不合適的。
? ?
?
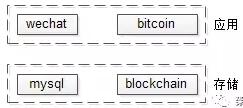
如上圖,mysql是底層存儲,wechat是上層應(yīng)用,用wechat來解釋mysql是不合適的。
今天,從技術(shù)的角度出發(fā),聊聊什么是區(qū)塊鏈里的“挖礦”。
先說結(jié)論,區(qū)塊鏈挖礦的本質(zhì)是啥?
答:生成一個區(qū)塊,鏈入?yún)^(qū)塊鏈的過程,就是挖礦。挖礦的人,就是礦工。
什么是區(qū)塊(block)?
答:如《??1分鐘了解區(qū)塊鏈的本質(zhì)??》里所述,區(qū)塊是一塊存儲空間,可以存儲數(shù)據(jù)。
? ?
?
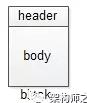
如上圖,區(qū)塊分為區(qū)塊頭(header)和區(qū)塊體(body)。
區(qū)塊體(body)存了些什么?
答:想存什么存什么,和上層應(yīng)用有關(guān),就像mysql里存什么依賴于上層應(yīng)用。例如比特幣使用的區(qū)塊鏈,區(qū)塊體里存儲的是比特幣交易記錄。
區(qū)塊頭(header)存了些什么?
答:區(qū)塊頭里存儲了和這個區(qū)塊,以及區(qū)塊鏈相關(guān)的一些元數(shù)據(jù)。
? ?
?
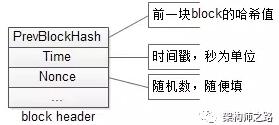
如上圖,區(qū)塊頭里的三個常見屬性:
- 前一個區(qū)塊的哈希值
- 區(qū)塊生成的時間戳
- 隨機數(shù)
什么是區(qū)塊鏈(blockchain)?
區(qū)塊是怎么鏈起來的?
答:
struct node{
node* prev; // 前一個節(jié)點
int time; // 時間戳
int nonce; // 隨機數(shù)
void* node_body; // 存儲數(shù)據(jù)
}node;?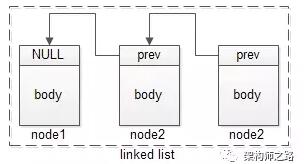 ?
?
鏈表,節(jié)點指針可以作為這個節(jié)點的唯一標(biāo)識,下一個節(jié)點通過存儲上一個節(jié)點的指針,將鏈表鏈起來。
? ?
?
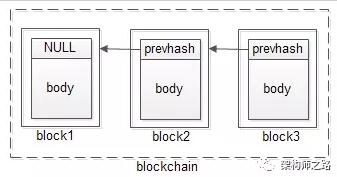
與之類似,區(qū)塊的哈希可以作為區(qū)塊的唯一標(biāo)識,下一個區(qū)塊通過存儲上一個區(qū)塊的哈希,將區(qū)塊鏈起來,這就是區(qū)塊鏈。
講完區(qū)塊與區(qū)塊鏈的概念,接下來講挖礦,也就是區(qū)塊的生成。
在此之前,先說說區(qū)塊鏈的三個特性:
- 歷史生成的區(qū)塊是無法改變的,即“區(qū)塊鏈只能像寫日志一樣追加寫,不能像mysql一樣隨機寫”
- 只能在***的區(qū)塊后面生成新區(qū)塊,即“必須先完成同步全網(wǎng)***的區(qū)塊鏈數(shù)據(jù)這項工作,才能啟動新區(qū)塊生成這項工作”
- 新區(qū)塊的生成很難,必須滿足一定條件的新區(qū)塊才有效
假如已經(jīng)同步了***的區(qū)塊鏈數(shù)據(jù),要滿足什么條件,才算生成一個新的區(qū)塊,才算“挖礦”成功呢?
答:對***的區(qū)塊頭進行兩次SHA256計算,得到的256bit哈希結(jié)果,高位48bit必須是0x00000000FFFF,才算挖礦成功。
畫外音:這句話很重要,是這篇文章的核心。
為什么大家都說“挖礦”很難?
由符合條件的哈希值,倒推出區(qū)塊頭,填入相應(yīng)的“前一塊區(qū)塊哈希值”“時間”“隨機數(shù)”不就可以了嗎?
答:額,這,,,哈希(SHA256是一個哈希算法)是不可逆的。例如MD5
md5(string) = md5_result
- 由字符串,算出對應(yīng)的md5值很容易,但由md5值反推出字符串是不可能的大家都知道:
- 可以認為哈希的結(jié)果是完全隨機的,要得出前48bit必須是0x00000000FFFF的哈希結(jié)果,就如同連續(xù)拋48次硬幣,每次都得到我們想要的結(jié)果,其概率為(1/2)^48
可以看到,這就好比在一座山上隨手撿起一塊石頭,正好是一塊金子,我猜測,這也正是把生成新區(qū)塊叫做“挖礦”的原因。
那應(yīng)該怎么找到符合條件的區(qū)塊頭呢,從而成功挖到礦呢?
答:窮舉法。
區(qū)塊頭里有個隨機屬性nonce,將這個屬性從0開始,遍歷到2^32,來計算區(qū)塊頭的哈希值,如果得到的哈希結(jié)果符合條件,則挖礦成功。
看上面的算法,只要程序運行時間足夠久,總能挖到礦呀?
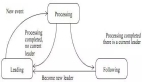
答:錯,如果別人計算能力強,在你挖到礦之前,如果別人先生成了新區(qū)塊,廣播到了區(qū)塊鏈網(wǎng)絡(luò),你本地不是***的區(qū)塊鏈,你挖到的礦就作廢啦,此時你要放棄之前所有的工作,先向網(wǎng)絡(luò)同步***的數(shù)據(jù),再重新開始挖。
有什么方法可以提升挖礦的速度呢?
答:從架構(gòu)的角度出發(fā)
- “緩存”是無效的:每個區(qū)塊的哈希值都不一樣,每個時間戳都不一樣,歷史計算過的值無法通過“查表”來節(jié)省時間
- scale up是有效的:增強單CPU的計算能力,使用GPU代替CPU,使用特殊的芯片計算SHA256D等優(yōu)化都是有效的,但scale up總是有極限的,單機總會遇到瓶頸
- scale out是有效的:單機不行,來并行,一臺機器不行,搞集群,這就是為什么會有這么多的礦場
如上圖,這是西藏高原上的一個比特幣礦場,廉價的電力讓無數(shù)礦工趨之若鶩。
綜上,區(qū)塊鏈里,什么是挖礦?
答:在***區(qū)塊鏈的數(shù)據(jù)上,生成一個符合條件的區(qū)塊,鏈入?yún)^(qū)塊鏈的過程,就是挖礦。
關(guān)于區(qū)塊鏈與挖礦,大家或許還有不少疑問:
- 如何保證數(shù)據(jù)的一致性
- 這TM有病吧,挖這玩意有什么意義,不是純浪費電嗎
- 這和比特幣有什么關(guān)系
- 比特幣怎么保證總量有限
- …
這些疑惑,下一個一分鐘,再和大家解釋。
希望這很短的一分鐘,大家了解了挖礦的本質(zhì)。
【本文為51CTO專欄作者“58沈劍”原創(chuàng)稿件,轉(zhuǎn)載請聯(lián)系原作者】
? ?
?