來看一看PB級分布式存儲Ceph
最近有朋友問關于區塊鏈用于存儲應用的話題,其實一定要清楚存儲和存證的關系,簡而言之區塊鏈適合做存儲的存證,并不適合做分布式的存儲用,為了搞清楚這個問題,今天我們來看看一個分布式存儲的代表Ceph是什么樣子的,也就說明了區塊鏈技術是否適合于作為存儲出現。
Ceph是加州大學Santa Cruz分校的Sage Weil(DreamHost的聯合創始人)專為博士論文設計的新一代自由軟件分布式文件系統。自2007年畢業之后,Sage開始全職投入到Ceph開 發之中,使其能適用于生產環境。Ceph的主要目標是設計成基于POSIX的沒有單點故障的分布式文件系統,使數據能容錯和無縫的復制。
Ceph設計目標
開發一個分布式文件系統需要多方努力,但是如果能準確地解決問題,它就是無價的。Ceph 的目標簡單地定義為:
- 可輕松擴展到數 PB 容量
- 對多種工作負載的高性能(每秒輸入/輸出操作[IOPS]和帶寬)
- 高可靠性
不幸的是,這些目標之間會互相競爭(例如,可擴展性會降低或者抑制性能或者影響可靠性)。Ceph 開發了一些非常有趣的概念(例如,動態元數據分區,數據分布和復制),這些概念在本文中只進行簡短地探討。Ceph 的設計還包括保護單一點故障的容錯功能,它假設大規模(PB 級存儲)存儲故障是常見現象而不是例外情況。最后,它的設計并沒有假設某種特殊工作負載,但是包括適應變化的工作負載,提供最佳性能的能力。它利用 POSIX 的兼容性完成所有這些任務,允許它對當前依賴 POSIX 語義(通過以 Ceph 為目標的改進)的應用進行透明的部署。最后,Ceph 是開源分布式存儲,也是主線 Linux 內核(2.6.34)的一部分。
Ceph 架構
現在,讓我們探討一下 Ceph 的架構以及高端的核心要素。然后我會拓展到另一層次,說明 Ceph 中一些關鍵的方面,提供更詳細的探討。
Ceph 生態系統可以大致劃分為四部分(見圖 1):客戶端(數據用戶),元數據服務器(緩存和同步分布式元數據),一個對象存儲集群(將數據和元數據作為對象存儲,執行其他關鍵職能),以及最后的集群監視器(執行監視功能)。
圖 1. Ceph 生態系統的概念架構
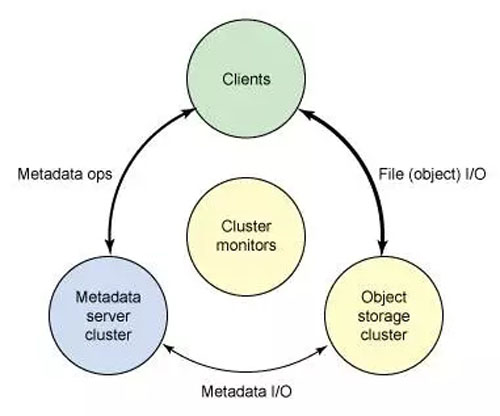
如圖 1 所示,客戶使用元數據服務器,執行元數據操作(來確定數據位置)。元數據服務器管理數據位置,以及在何處存儲新數據。值得注意的是,元數據存儲在一個存儲集群(標為 “元數據 I/O”)。實際的文件 I/O 發生在客戶和對象存儲集群之間。這樣一來,更高層次的 POSIX 功能(例如,打開、關閉、重命名)就由元數據服務器管理,不過 POSIX 功能(例如讀和寫)則直接由對象存儲集群管理。
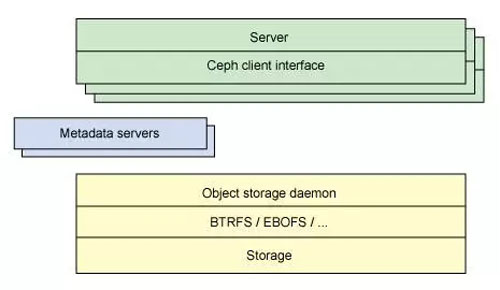
另一個架構視圖由圖 2 提供。一系列服務器通過一個客戶界面訪問 Ceph 生態系統,這就明白了元數據服務器和對象級存儲器之間的關系。分布式存儲系統可以在一些層中查看,包括一個存儲設備的格式(Extent and B-tree-based Object File System [EBOFS] 或者一個備選),還有一個設計用于管理數據復制,故障檢測,恢復,以及隨后的數據遷移的覆蓋管理層,叫做 Reliable Autonomic Distributed Object Storage(RADOS)。最后,監視器用于識別組件故障,包括隨后的通知。
圖 2. Ceph 生態系統簡化后的分層視圖
Ceph 組件
了解了 Ceph 的概念架構之后,您可以挖掘到另一個層次,了解在 Ceph 中實現的主要組件。Ceph 和傳統的文件系統之間的重要差異之一就是,它將智能都用在了生態環境而不是文件系統本身。
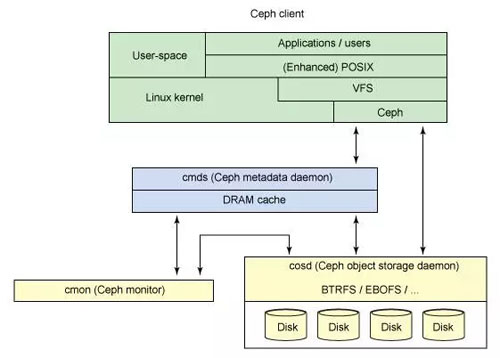
圖 3 顯示了一個簡單的 Ceph 生態系統。Ceph Client 是 Ceph 文件系統的用戶。Ceph Metadata Daemon 提供了元數據服務器,而 Ceph Object Storage Daemon 提供了實際存儲(對數據和元數據兩者)。最后,Ceph Monitor 提供了集群管理。要注意的是,Ceph 客戶,對象存儲端點,元數據服務器(根據文件系統的容量)可以有許多,而且至少有一對冗余的監視器。那么,這個文件系統是如何分布的呢?
圖 3. 簡單的 Ceph 生態系統
Ceph 客戶端
因為 Linux 顯示文件系統的一個公共界面(通過虛擬文件系統交換機 [VFS]),Ceph 的用戶透視圖就是透明的。管理員的透視圖肯定是不同的,考慮到很多服務器會包含存儲系統這一潛在因素(要查看更多創建 Ceph 集群的信息,見 參考資料 部分)。從用戶的角度看,他們訪問大容量的存儲系統,卻不知道下面聚合成一個大容量的存儲池的元數據服務器,監視器,還有獨立的對象存儲設備。用戶只是簡單地看到一個安裝點,在這點上可以執行標準文件 I/O。
Ceph 文件系統 — 或者至少是客戶端接口 — 在 Linux 內核中實現。值得注意的是,在大多數文件系統中,所有的控制和智能在內核的文件系統源本身中執行。但是,在 Ceph 中,文件系統的智能分布在節點上,這簡化了客戶端接口,并為 Ceph 提供了大規模(甚至動態)擴展能力。
Ceph 使用一個有趣的備選,而不是依賴分配列表(將磁盤上的塊映射到指定文件的元數據)。Linux 透視圖中的一個文件會分配到一個來自元數據服務器的 inode number(INO),對于文件這是一個唯一的標識符。然后文件被推入一些對象中(根據文件的大小)。使用 INO 和 object number(ONO),每個對象都分配到一個對象 ID(OID)。在 OID 上使用一個簡單的哈希,每個對象都被分配到一個放置組。放置組(標識為 PGID)是一個對象的概念容器。最后,放置組到對象存儲設備的映射是一個偽隨機映射,使用一個叫做 Controlled Replication Under Scalable Hashing(CRUSH)的算法。這樣一來,放置組(以及副本)到存儲設備的映射就不用依賴任何元數據,而是依賴一個偽隨機的映射函數。這種操作是理想的,因為它把存儲的開銷最小化,簡化了分配和數據查詢。
分配的最后組件是集群映射。集群映射 是設備的有效表示,顯示了存儲集群。有了 PGID 和集群映射,您就可以定位任何對象。
Ceph 元數據服務器
元數據服務器(cmds)的工作就是管理文件系統的名稱空間。雖然元數據和數據兩者都存儲在對象存儲集群,但兩者分別管理,支持可擴展性。事實上,元數據在一個元數據服務器集群上被進一步拆分,元數據服務器能夠自適應地復制和分配名稱空間,避免出現熱點。如圖 4 所示,元數據服務器管理名稱空間部分,可以(為冗余和性能)進行重疊。元數據服務器到名稱空間的映射在 Ceph 中使用動態子樹邏輯分區執行,它允許 Ceph 對變化的工作負載進行調整(在元數據服務器之間遷移名稱空間)同時保留性能的位置。
圖 4. 元數據服務器的 Ceph 名稱空間的分區
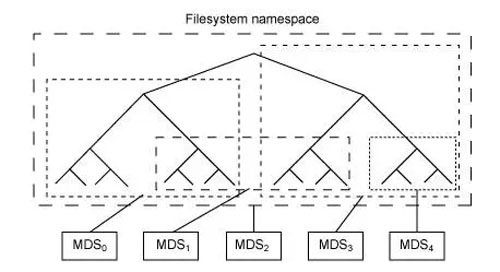
但是因為每個元數據服務器只是簡單地管理客戶端人口的名稱空間,它的主要應用就是一個智能元數據緩存(因為實際的元數據最終存儲在對象存儲集群中)。進行寫操作的元數據被緩存在一個短期的日志中,它最終還是被推入物理存儲器中。這個動作允許元數據服務器將最近的元數據回饋給客戶(這在元數據操作中很常見)。這個日志對故障恢復也很有用:如果元數據服務器發生故障,它的日志就會被重放,保證元數據安全存儲在磁盤上。
元數據服務器管理 inode 空間,將文件名轉變為元數據。元數據服務器將文件名轉變為索引節點,文件大小,和 Ceph 客戶端用于文件 I/O 的分段數據。
Ceph 監視器
Ceph 包含實施集群映射管理的監視器,但是故障管理的一些要素是在對象存儲本身中執行的。當對象存儲設備發生故障或者新設備添加時,監視器就檢測和維護一個有效的集群映射。這個功能按一種分布的方式執行,這種方式中映射升級可以和當前的流量通信。Ceph 使用 Paxos,它是一系列分布式共識算法。
Ceph 對象存儲
和傳統的對象存儲類似,Ceph 存儲節點不僅包括存儲,還包括智能。傳統的驅動是只響應來自啟動者的命令的簡單目標。但是對象存儲設備是智能設備,它能作為目標和啟動者,支持與其他對象存儲設備的通信和合作。
從存儲角度來看,Ceph 對象存儲設備執行從對象到塊的映射(在客戶端的文件系統層中常常執行的任務)。這個動作允許本地實體以最佳方式決定怎樣存儲一個對象。Ceph 的早期版本在一個名為 EBOFS 的本地存儲器上實現一個自定義低級文件系統。這個系統實現一個到底層存儲的非標準接口,這個底層存儲已針對對象語義和其他特性(例如對磁盤提交的異步通知)調優。今天,B-tree 文件系統(BTRFS)可以被用于存儲節點,它已經實現了部分必要功能(例如嵌入式完整性)。
因為 Ceph 客戶實現 CRUSH,而且對磁盤上的文件映射塊一無所知,下面的存儲設備就能安全地管理對象到塊的映射。這允許存儲節點復制數據(當發現一個設備出現故障時)。分配故障恢復也允許存儲系統擴展,因為故障檢測和恢復跨生態系統分配。Ceph 稱其為 RADOS(見 圖 3)。
其他分布式文件系統
Ceph 在分布式文件系統空間中并不是唯一的,但它在管理大容量存儲生態環境的方法上是獨一無二的。分布式文件系統的其他例子包括 Google File System(GFS),General Parallel File System(GPFS),還有 Lustre,這只提到了一部分。Ceph 背后的想法為分布式文件系統提供了一個有趣的未來,因為海量級別存儲導致了海量存儲問題的唯一挑戰。