













我用一下午時間標注了十萬張沒有標簽的圖片,為老板節約了3W美金
原創【51CTO.com原創稿件】想象一下你的老板給了你 10 萬張無標簽的圖片,并要求你將它們分類為涼鞋、褲子、靴子等等。
現在你有一大堆沒有標簽的數據,你需要為這些數據打上標簽。你該怎么辦呢?
這個問題是司空見慣的。許多公司都在數據的大海里遨游,不論是交易數據、物聯網傳感器產生的海量數據、安全日志,還是圖像、語音數據等等,這些都是未標注的數據。
用這么少的標注數據,對于所有企業中的數據科學家來說,建立機器學習模型都是一個單調乏味的過程。
以 Google 的街景數據為例,Gebru 不得不弄清楚如何用很少的帶有標簽的數據為五千萬張圖片貼上汽車標簽。
在 Facebook,工程師們使用算法來標注 50 萬個視頻,這個任務使用其他的方法需要花費 16 年的時間。
這篇文章將向您展示如何用一個下午的時間標注數十萬張圖片。無論是標注圖像還是標注傳統表格數據(例如,識別網絡安全攻擊或可能的部件故障),都可以使用同樣的方法。
手工標注的方法
對大多數數據科學家來說,如果他們被要求去做某件事,他們首先會想一想有沒有其他可以替代的人去做這件事。
但是 10 萬張圖片可能會讓您在 Mechanical Turk 或類似的其他競爭平臺上花費至少 30,000 美元。
你的老板期望以較低的代價來做這件事,因為畢竟,他們聘請了你。現在,除了你的工資以外,她沒有其他任何的預算(如果你不相信我,請去 pydata)。
你深吸了一口氣,想了一下你可以在一個小時內標完 200 張圖片。所以這意味著在三個星期內不停地工作,你就可以標完所有的數據!哎呀!
建立一個簡單的模型
第一個想法是標記一部分圖片,用它們訓練一個機器學習模型,然后用來預測剩下的圖片的標簽。
對于這個練習,我使用的是 Fashion-MNIST 數據集(你也可以用 quickdraw 來制作自己的數據集)。
有十個類別的圖像要我們去做識別,下面是它們的樣子:

看到這個數據集我很高興,因為每幅圖片都是由 28×28 像素組成的,這意味著它包含 784 個獨特的特征/變量。
對于我要寫一篇博客文章來說,這些特征很好,但是在現實世界中你是絕對看不到這樣的數據集的,它們往往要么窄得多(傳統的表格業務問題數據集),要么寬得多(真實圖像要大得多,而且由不同的顏色組成)。
我使用最常見的數據科學算法來建立模型,包括:邏輯回歸,支持向量機(SVM),隨機森林和 Gradient Boosted Machines(GBM) 。
我根據它們在 100、200、500、1000 和 2000 張圖片上的標注效果來評測它們的性能。
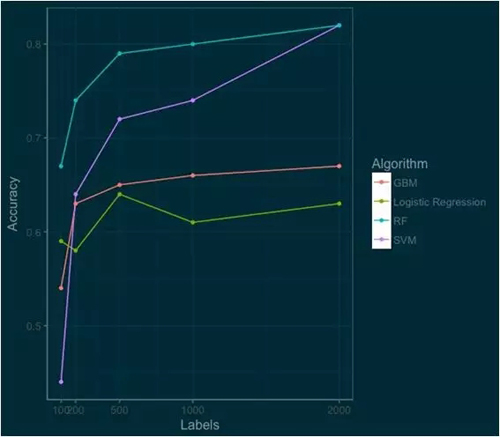
如果你看到這個地方了,那么你應該放慢速度,仔細研究一下這張圖。這張圖里有很多好東西。
哪個算法最好呢?(如果你是一個數據科學家,你不應該為這個問題而困惑。)問題的答案其實取決于需求環境。
如果你想要快速可靠地開箱即用,你可以選擇邏輯回歸算法。隨機森林算法從開始時就一直遙遙領先,SVM 雖然起點較低,但以極快的速度追趕上來。隨著我們的標注數據越來越多,SVM 的性能將超過隨機森林。
GBM 工作的很好,但要達到最好的性能還需要做一些額外的工作。這里每種算法的分數都是使用了 R 中已經實現好的庫評測出的(e1071,randomForest,gbm,nnet)。
如果我們的 benchmark 是對十個類別的圖像分類任務達到 80% 的準確率,那么我們可以通過建立一個包含 1000 個圖像的隨機森林模型來達到目標。
但是 1000 張圖像的標注工作量依舊是很大的,我估計需要 5 個小時。所以讓我們想想還有什么可以改進的方法。
Let’s Think About Data
經過短暫思考后,你想起來你經常告訴別人的一句話:數據不是隨機的,而是有模式的(The data isn’t random,but has patterns)。利用好這些模式,我們可以更深入地理解我們的數據。
讓我們從一個自動編碼器(autoencoder,AE)開始。自動編碼器是用來壓縮你的數據的,就像把湯變成 一個肉湯塊一樣。自動編碼器使用了很時髦的主成分分析(PCA),它們支持非線性變換。
實際上,這意味著我們正在將我們的寬廣的數據(784 個特征/變量)減少到 128 個特征。然后我們利用新的壓縮后的數據來訓練我們的機器學習算法(此例中我們使用 SVM)。
下面的圖表顯示了用自動編碼器(AE_SVM)壓縮的數據訓練的 SVM 與使用原始數據訓練的 SVM 之間的性能差異。
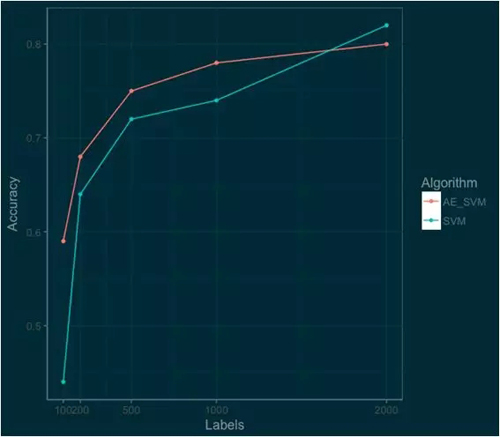
通過將信息壓縮到 128 個特征,我們實際上能夠改善底端 SVM 算法的性能。
在 100 個標簽上,準確率從 44% 上升到 59%;在 1000 個標簽上,自動編碼器仍然可以起作用,我們看到準確率從 74% 提高到 78%。
所以我們離目標更近了一步,我們只需要更進一步地思考可以利用的數據的分布和模式。
Thinking Deeper About Your Data
我們的數據是圖像,而我們知道,自 2012 年以來,圖像處理的利器是卷積神經網絡(CNN)。
使用 CNN 有好幾種方法,可以從一個預訓練的網絡或簡單的模型來預處理圖像。
這篇文章中,我參照 Kingma 等人的一篇論文,使用卷積變分自動編碼器(Convolutional Variational Autoencoder)來實現目標。
因此,我們來建立一個卷積變分自動編碼器(CVAE)。這里的技術相比之前有兩層“飛躍”。
首先,“變分”(variational)是指自動編碼器將信息壓縮成概率分布。其次是增加了卷積神經網絡作為編碼器。
這里使用了一點深度學習的技術,但我要強調的是我們的重點不是為了賣弄最新的最潮的技術,而是如何恰當地去解決問題。
為了編碼我的 CVAE,我使用了 examples over at RStudio’s Keras Page 這個列表中的示例 CVAE。
像之前的自動編碼器一樣,我們設計了潛在的空間來將數據減少到 128 個特征。然后,我們使用這些新的數據來訓練 SVM 模型。
以下是 CVAE_SVM 與在原始數據上訓練的 SVM 和 Random Forest 的性能比較圖。
哇!新模型更加準確。只用 500 個標簽,我們就可以達到 80% 以上的準確率。
通過使用這些技術,我們獲得了更好的性能,并且只需要更少的標注圖像。在高端,這種方法也可以比 Random Forest 或 SVM 模型做得更好。
Next Steps
通過對自動編碼器使用一些非常簡單的半監督技術,就可以快速準確地標注數據。但是重點并不是使用深度學習編碼器!
相反,我希望你理解了這里的方法后,從很簡單的方法開始嘗試,然后逐漸嘗試更復雜的解決方案。
不要沉迷于使用那些最新的技術—實際的數據科學并不是使用 arXiv 中的最新方法。
這種半監督學習的方法一定可以給你帶來啟發。這篇文章相當于半監督學習中的邏輯回歸算法。
如果你想進一步深入半監督學習和領域適應性(Domain Adaptation)相關的內容,請參考 BrianKeng 的 great walkthrough of using variational autoencoders。
他的工作超出了我們在這里所說的,或者 Curious AI 的工作 ,他們的工作使用深度學習來改進半監督學習,并且開放了代碼。
最后,我希望你至少要明白的一點是,不要認為你所有的數據都要貼上標簽。

【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】


















