數字化企業的數據自服務
一、什么是數據自服務
數據在企業中的處理過程,能清晰地映射出康威定律對IT系統的影響。在各個部門分別建設IT系統、組織內部大量存在信息筒倉(silo)的年代,數據的操作由OLTP應用系統的開發團隊同步開發,那時幾乎每個政府信息化、企業信息化系統都會有一塊“報表需求”。隨后眾多組織認識到筒倉系統導致信息在組織內不能拉通,不能產生對整體業務流程的洞察,于是開始建設以數據倉庫為代表的OLAP系統。
這些系統在支撐更高級、更復雜的數據分析的同時,也對應地在組織中造就了一支專業的“數據團隊”。這些人使用非常專業的技術和工具對數據進行提取、轉換、裝載、建立數據立方、多維鉆取、生成報表。這些專業的技術和工具,普通的軟件開發人員并沒有掌握,因此對數據處理、分析和呈現的變更都必須歸集到這個數據團隊來完成。結果是,數據團隊的backlog里累積了來自各個部門的需求,需求的響應能力下降,IT系統從上線到獲得市場洞察的周期變長。
微服務架構鼓勵小型的、全功能的團隊擁有一個完整的服務(及其對應的業務)。這樣的全功能團隊不光要開發和運維IT系統,還要能從數據中獲得洞察——而且要快,不然就會跟不上市場變化,甚至使一些重要的業務場景無法得到支撐。因此他們不能坐等一支集中式的、緩慢的數據團隊來響應他們的需求,他們需要數據自服務能力。 要賦能數據自服務,企業的數字化平臺要考慮“兩個披薩團隊”的下列訴求:
- 需要定義數據流水線,使數據能夠順暢地流過收集、轉換、存儲、探索/預測、可視化等階段,產生業務價值。
- 需要用實時的架構和API在短時間內處理大量、非結構化的數據,從中獲得洞見,并實時影響決策。
- 為了提高應變能力,系統中的數據不做ETL預處理,而是以“生數據”的形式首先存入數據湖,等有了具體的問題要回答時,再去組織和篩選數據,從中找出答案。
- 更進一步把數據包裝成能供外人使用的數據產品,讓第三方從數據中獲得新的洞見與價值。
- 為了支持數據產品的運營,需要實現細粒度授權,針對不同的用戶身份,授權訪問不同范圍的數據。
二、數據自服務解讀
下面是ThoughtWorks的數字平臺戰略第三個支柱“數據自服務”中所蘊涵的具體內容。

1. 數據流水線設計
所謂流水線,是指用大數據創造價值的整個數據流。流水線從數據采集開始,隨后是數據的清洗或過濾,再然后是將數據結構化到存儲倉庫中以便訪問和查詢,這之后就可以通過探索或預測的方式從數據中找到業務問題的答案,并可視化呈現出來。

一條運轉良好的數據流水線,能有效處理移動/物聯網等新技術制造出的極其大量的數據,縮短數據從獲取到產生洞見的反饋周期,并以開發者友好的方式完成數據各個環節的處理,賦能一體化團隊。
數據流水線的實現有兩種可能的方式。一種方式是在各個環節采用各種特定的工具,例如前面介紹的數據流水線,各個環節都可以用開源的工具來實現。當然,選擇這種方式也并非沒有挑戰:組織必須自己編寫和維護“膠水代碼”,把各種專用工具組合成一個內聚的整體。對組織的技術能力有較高的要求。
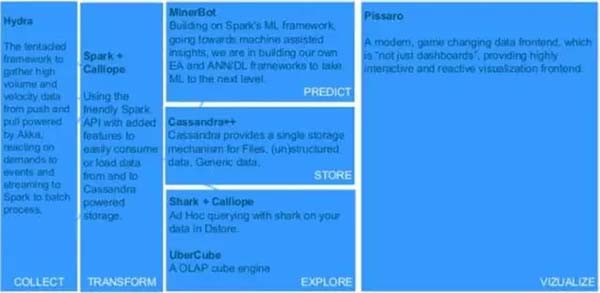
除了基于開源軟件實現自己的數據流水線,也可以考慮采用云上的數據流水線PaaS服務,例如Databricks、AWS Data Pipeline、Azure Data Factory等。這個方式的優點是對技術能力要求較低,缺點則是造成對特定云平臺/PaaS提供商的依賴。
2. 實時架構和API
實時的數據架構和API支持短時間內處理大量、非結構化的數據,從中獲得洞見,并“實時”影響決策。正如Mike Barlow所說:“這是關于在正確時間做出更好決定并采取行動的能力,例如在顧客刷卡的時候識別信用卡欺詐,或者當顧客在排隊結賬的時候給個優惠,或者當用戶在閱讀某篇文章的時候推送某個廣告。”
在Cloudera的一篇文章中介紹了實時數據處理的4個架構模式,整個流水線架構在Flume/Kafka基礎上:
- 數據流吸收:低延遲將事件持久化到HDFS、HBase、Solr等存儲機制
- 近實時(100毫秒以下)的事件處理:數據到達時立即采取警告、標記、轉換、過濾等初步行動
- 近實時的事件分片處理:與前一個模式類似,但是先對數據分片
- 復雜而靈活的聚合或機器學習拓撲,使用Spark
3. 數據湖設計
數據湖概念最初提出是在2014年Forbes的一篇文章中。它的概念是:不對數據做提前的“優化”處理,而是直接把生數據存儲在容易獲得的、便宜的存儲環境中;等有了具體的問題要回答時,再去組織和篩選數據,從中找出答案。按照ThoughtWorks技術雷達的定義,數據湖中的數據應該是不可修改(immutable)的。
數據湖試圖解決數據倉庫幾方面的問題:
- 預先的ETL處理終歸會損失信息,如果事后才發現需要生數據中的某些信息、但是這些信息又沒有通過ETL進入數據倉庫,那么信息就無法尋回了。
- ETL的編寫相當麻煩。數據倉庫的schema發生改變,ETL也要跟著改變;應用程序的schema發生改變,ETL也要跟著改變。因此數據倉庫通常由一個單獨的團隊負責,于是形成一個功能團隊,響應速度慢。
- 數據倉庫的分析需要專門的技能,大部分應用程序開發者不掌握,再度強化了數據倉庫專門團隊;而數據倉庫團隊其實離業務很遠,并不能快速準確地響應業務對數據分析的需求。
在數據湖概念背后是康威法則的體現:數據能力與業務需求對齊。它要解決的核心問題是專門的數據倉庫團隊成為響應力瓶頸。當IT能力與業務需求組合形成一體化團隊以后,數據的產生方不再假設未來要解決什么問題,因此也不對數據做預處理,只是直接存儲生數據;數據的使用方以通用編程語言(例如Java或Python)來操作數據,從而無需依賴專門的、集中式的數據團隊。
數據湖實施的***步是把生數據存儲在廉價的存儲介質(可能是HDFS,也可能是S3,或者FTP等)。對于每份生數據,應該有一份元數據描述其來源、用途、和哪些數據相關等等。元數據允許整個組織查看和搜索,讓每個一體化團隊能夠自助式尋找自己需要的數據。任何團隊都可以在生數據的基礎上開發自己的微服務,微服務處理之后的數據可以作為另一份生數據回到數據湖。維護數據湖的團隊只做很少的基礎設施工作,生數據的輸入和使用都由與業務強關聯的開發團隊來進行。傳統數據倉庫的多維分析、報表等功能同樣可以作為一個服務接入數據湖。
在實施數據湖的時候,有一種常見的反模式:企業有了一個名義上的數據湖(例如一個非常大的HDFS),但是數據只進不出,成了“數據泥沼”(或數據墓地)。在這種情況下,盡管數據湖的存儲做得很棒,但是組織并沒有很好地消化這些數據(可能是因為數據科學家不具備分析生數據的技術能力,而是更習慣于傳統的、基于數據倉庫的分析方式),從而不能很好地兌現數據湖的價值。
4. 數據即產品
數據產品是指將企業已經擁有或能夠采集的數據資產,轉變成能幫助用戶解決具體問題的產品。Forbes列舉了幾類值得關注的數據產品:
- 用于benchmark的數據
- 用于推薦系統的數據
- 用于預測的數據
數據產品是數據資產變現的快速途徑。因為數據產品有幾個優勢:開發快,不需要開發出完整的模型,只要做好數據整理就可以對外提供;顧客面寬,一份數據可以產生多種用途;數據可以再度加工。數據產品給企業創造的收益既可以是直接的(用戶想要訪問數據或分析時收費)也可以是間接的(提升顧客忠誠度、節省成本、或增加渠道轉化率)。
在實現數據產品的時候,不僅要把數據打包,更重要的是提供數據之間的關聯。數據產品的供應者需要提出洞見、指導用戶做決策,而不僅僅是提供數據點。數據產品需要考慮用戶的場景和體驗,并在使用過程中不斷演進。
5. 細粒度授權
當數據以產品或服務的形式對外提供,企業可能需要針對不同的用戶身份,授權訪問不同范圍的數據,對應不同的服務水平和不同的安全級別。
一些典型的細粒度授權的場景可能包括:
- 企業內部和外部用戶能夠訪問的數據范圍不同;
- 供應鏈上不同環節的合作伙伴能夠訪問的數據范圍不同;
- 付費與免費的用戶能夠訪問的數據范圍不同;
- 不同會員級別能夠訪問的數據范圍不同等等。
允許訪問的數據范圍屬于數據產品/服務自身的業務規則。《微服務設計》的第9章建議,“[服務]網關可以提供相當有效的粗粒度的身份驗證……不過,比允許(或禁止)的特定資源或端點更細粒度的訪問控制,可以留給微服務本身來處理”。
三、小結
為了加速“構建-度量-學習”的精益創業循環,業務與IT共同組成的一體化團隊不能依賴于集中式的數據團隊來獲得對業務的洞察。他們需要規劃適宜自己的數據流水線,在必要時引入實時數據架構和API,用數據湖來支撐自服務的數據操作,從而更快、更準確地從數據中獲得洞察,影響業務決策。更進一步,數據本身也可以作為產品對內部用戶乃至外部用戶提供服務,并通過細粒度授權體現服務的差異化和安全性需求。通過建設“數據自服務”這個支柱,企業將真正能夠盤活數據資產,使其在創新的數字化業務中發揮更大的價值,這是企業數字化旅程的第三步。
【本文是51CTO專欄作者“ThoughtWorks”的原創稿件,微信公眾號:思特沃克,轉載請聯系原作者】