用隨機森林分類算法進行Iris 數據分類訓練,是怎樣的體驗?
MLlib是Spark的機器學習(ML)庫,旨在簡化機器學習的工程實踐工作,并方便擴展到更大規模。
MLlib由一些通用的學習算法和工具組成,包括分類、回歸、聚類、協同過濾、降維等,同時還包括底層的優化原語和高層的管道API。
MLllib目前分為兩個代碼包:spark.mllib 包含基于RDD的原始算法API。
spark.ml ,提供了基于DataFrames高層次的API,可以用來構建機器學習管道,FEA-spk技術的機器學習就是基于spark.ml 包。
spark.ml 包,是基于DataFrame的,未來將成為Spark機器學習的主要API。它可以在分布式集群上進行大規模的機器學習模型訓練,并且可以對數據進行可視化。
一、隨機森林分類算法的介紹
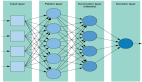
隨機森林顧名思義,是用隨機的方式建立一個森林,森林里面有很多的決策樹組成,隨機森林的每一棵決策樹之間是沒有關聯的。在得到森林之后,當有一個新的輸入樣本進入時,就讓森林中的每一棵決策樹分別進行一下判斷,看看這個樣本應該屬于哪一類(對應分類算法),然后看看哪一類被選擇最多,就預測這個樣本為那一類。
使用Spark MLlib隨機森林算法存在不足,需要改進!
具體來講,使用Spark MLlib進行模型的訓練,需要進行大量的數據轉化,列聚合為向量等。非常麻煩,并且不能做數據的可視化。
而FEA-spk技術可以很好的解決這些問題。對模型進行訓練只需要一句命令就行了,并且可以對結果數據進行可視化展示。
二、Iris 數據分類訓練案例
下面列舉一個用隨機森林分類算法進行Iris 數據分類的例子。
1. 數據準備
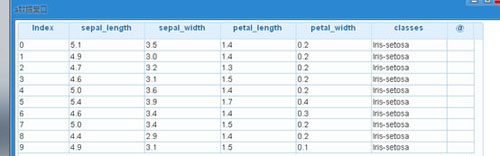
原始的數據以及相應的說明可以到https://pan.baidu.com/s/1c2d0hpA下載。 我在這基礎之上,增加了header信息。
這里將下載好的數據放到hdfs上面進行讀取。
2. Iris 數據進行訓練的具體步驟
(1)要使用FEA-spk技術,首先要創建一個spk的連接,所有的操作都是以它為上下文進行的。在fea界面運行以下命令

(2)加載數據,數據在hdfs上面,數據的格式為csv文件格式,目錄為/data/iris_data.txt

(3)使用ML_si方法將字符型的label變成index

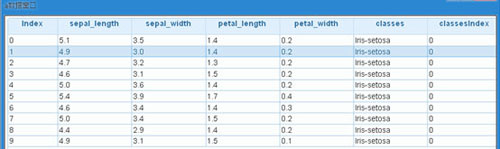
(4)將特征列的類型轉化為double類型,因為spark.ml只支持double類型,使用 ML_double方法

(5)使用隨機森林模型進行訓練
在訓練RandomForest模型的時候,我們需要設置好幾個參數:
- maxBins
***裝箱數,為了近似統計變量,比如變量有100個值,我只分成10段去做統計,默認值是32;
- numTrees
森林里有幾棵樹,默認值是20;
- minInstancesPerNode
每個節點最少實例,默認值是1;
- minInfoGain
最小信息增益,默認值是0.0;
- maxDepth
***樹深度,默認值是5;
- maxMemoryInMB
***內存MB單位,這個值越大,一次處理的節點劃分就越多,默認值是256;
- cacheNodeIds
是否緩存節點id,緩存可以加速深層樹的訓練,默認值是False;
- checkpointInterval
檢查點間隔,就是多少次迭代固化一次,默認值是10;
- impurity
隨機森林有三種方式,entropy,gini,variance,回歸肯定就是variance,默認值是gini;
- seed
采樣種子,種子不變,采樣結果不變,默認值None;
- featureSubsetStrategy
auto: 默認參數。讓算法自己決定,每顆樹使用幾條數據。
使用的參數如下圖所示
![]()
(6)對訓練好的模型進行打分
![]()

可以看到準確率達到了97%
(7)將訓練好的模型保存到hdfs上面,以供下次使用
![]()

這個非常實用,對于模型比較大的情況下,利用HDFS的分布式結構就可以提高加載性能。
(8)將hdfs上面保存的模型加載進來
![]()
(9)對加載后的模型做預測

其中prediction列就是預測的結果
以上就是使用FEA-spk技術進行機器學習的步驟,它非常適合數據分析處理大規模的數據,簡單、強大、可視化,不懂Java\Python同樣可以玩轉Spark!