數據科學簡介:通過對數據分類進行預測(二)
你可以從原始數據提取出的一種關鍵價值是,能夠構建一個可用于預測或分類的模型。應用此模型,您可以將觀察值轉換為具有明顯價值的預測或分類。本教程延續了第 1 部分:“數據、結構和數據科學管道”中引入的原則,探討兩種使用監督學習和無監督學習的分類方法(一種預測形式)。
分類是機器學習算法的一種常見應用。您可以使用監督學習來實現預測和分類,使用以前的觀察值構建一個模型,以便根據未見過的觀察值來預測結果。也可以使用無監督學習來實現這一過程,將觀察值聚類到集合中,以便根據與新觀察值最接近的集群來預測它們的行為。
機器學習已成功應用于許多預測和分類問題,包括航班晚點、信用評分和股票價格。在這里,我將探討兩種重要算法:概率神經網絡和基于密度的聚類 (DBSCAN)。
概率神經網絡
概率神經網絡 (PNN) 是 1966 年創建的,類似于我在“神經網絡深入剖析”中討論的反向傳播(back-propagation)神經網絡。二者都是多層的前饋神經網絡,但 PNN 不依靠誤差反向傳播,它采用了一種不同的訓練方法。您可以使用 PNN 執行模式識別、聚類、分類,以及預測。
PNN 架構
PNN 是一種監督學習方法,依賴于一個包含標簽(用于標識每個觀察值的類)的訓練集。PNN 由 4 層組成,如下所示。
圖 1. PNN 架構
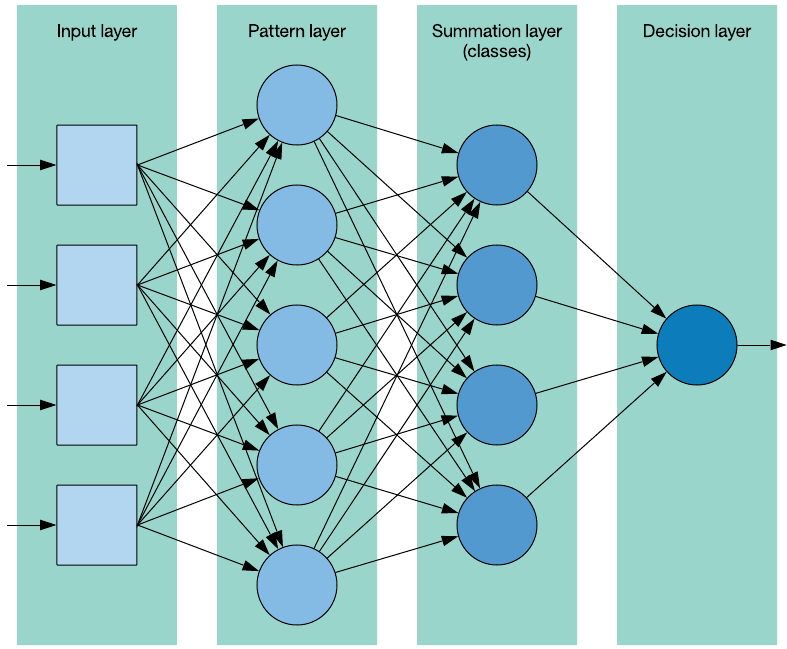
輸入層 (input layer) 代表輸入矢量,具有一個包含問題的特征數量的維度。模式層 (pattern layer) 也稱為隱藏層,由訓練數據集中每個觀察值對應的神經元組成。模式神經元計算離訓練樣本(由神經元表示)的歐氏距離,并將該距離表示為該類的特征矢量圖心的輸入特征矢量。匯總層 (summation layer) 包含該數據集表示的每個類所對應的神經元。顧名思義,匯總層中的神經元會計算出它們所代表的特定類的模式層神經元的輸出之和(其中包括一個基于該類的觀察值數量的平均值)。***,輸出層,也稱為決策層 (decision layer),實現了一種贏家通吃的方法:它識別匯總層中具有***值的類神經元。然后,這個類表示了所預測的輸入矢量的類。
PNN 算法
您很快就會在一段代碼中看到,訓練和使用 PNN 的算法很簡單。不需要訓練,因為計算一個預測值只需迭代整個數據集來計算匯總層中的神經元。與之相反,在傳統的反向傳播中,會在訓練每個觀察值之后調整權重值。因此,反向傳播網絡使用起來可能更快,但花費的訓練時間可能更長(根據一個關于數據集大小的函數)。
該流程從一個示例特征矢量(表示您希望預測其類的觀察值)和包含帶標簽觀察值的數據集開始。對于匯總層中的每個神經元(表示一個類),可以迭代該數據集,并計算該類的示例特征矢量和每個數據集觀察值的平方和,然后應用一個平滑系數。當利用數據集中表示的(該類的)觀察值計算了所有匯總神經元后,會通過贏者通吃的方法選擇***的值。這個類表示了該示例的預測類。
PNN 實現
可以在 GitHub 上找到這個 PNN 的完整實現。清單 1 提供了分類器函數,該函數接受一個示例觀察值并返回它應該屬于的類(預測結果)。正如前面所討論的,此代碼從匯總層開始,使用示例觀察值來計算該類中包含的數據集觀察值的匯總神經元。然后將匯總神經元傳遞給一個名為 winner_takes_all 的函數,該函數只確定哪個神經元具有***值(贏者)。
清單 1. PNN 分類器的 C 代碼

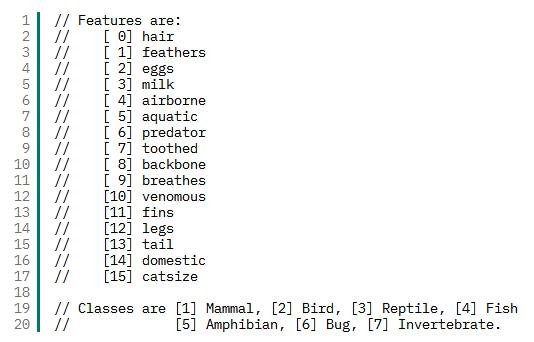
在我為 PNN 提供一些數據用于預測時,您就可以看到它的實際效果。在本例中,我返回到我的動物園數據集,其中包含一組基于動物特征(毛發、羽毛、產卵情況、空氣傳播等)的動物。我將構造一些樣本觀察值,以查看該算法對類(哺乳動物、昆蟲、兩棲動物等)的預測結果。清單 2 提供了該數據集的元數據(特征矢量描述和類描述)。
清單 2. 動物園數據集元數據
清單 3 給出了示例特征矢量的樣本代碼,以及用于演示使用 PNN 分類器的類預測結果的輸出。此輸出表明,一種有牙齒的跳蚤仍是昆蟲;一種有毛發的掠食動物是哺乳動物;一種水生的、產卵的、有 6 條腿的動物是無脊椎動物。
清單 3. 特征矢量和預測示例

基于數據的聚類
DBSCAN 創建于 1996 年,是一種可自動確定自然集群數量的簡單聚類方法。該方法能夠以可靠方式處理異常樣本(DBSCAN 稱之為噪聲)。可以在“用于數據分類的無監督學習”中進一步了解聚類算法。DBSCAN 最初被定義為用在數據庫中,因識別(大小和形狀)不規則的集群而聞名,而且適用于 k-均值無法順利實現聚類的數據。
DBSCAN 是無監督的,它嘗試使用數據的隱藏特征來提供數據結構。它使用了兩個參數:最少的點數和 epsilon 距離。
DBSCAN 算法
DBSCAN 處理一個多維空間中的點。每個點由一個特征矢量表示,而且給定了兩個矢量,您可以使用一個指標來計算它們之間的距離(比如歐氏距離)。
該算法從一個點開始,您可以識別離原始點給定距離(稱為 epsilon 距離)內的鄰近點數量。如果鄰近點數量滿足或超出了閾值(稱為最少點數或 MINPTS),則將這個點稱為核心點,并將它與一個新集群相關聯。否則,會將這個點標為噪聲。對于每個鄰近點(稱為密度可達點),只要它繼續滿足條件(離此點 epsilon 距離內的 MINPTS 點),就繼續執行此操作并對它執行聚類。如果您到達一個沒有密度可達點的點,那么可以將該點包含在集群中,但不使用超過此點的點來合并新點。
任何不滿足條件(epsilon 距離內的 MINPTS)的點都被定義為噪聲,但是,如果發現它們是一個集群中另一個點的密度可達點,那么最終可以將它們移動到該集群中。
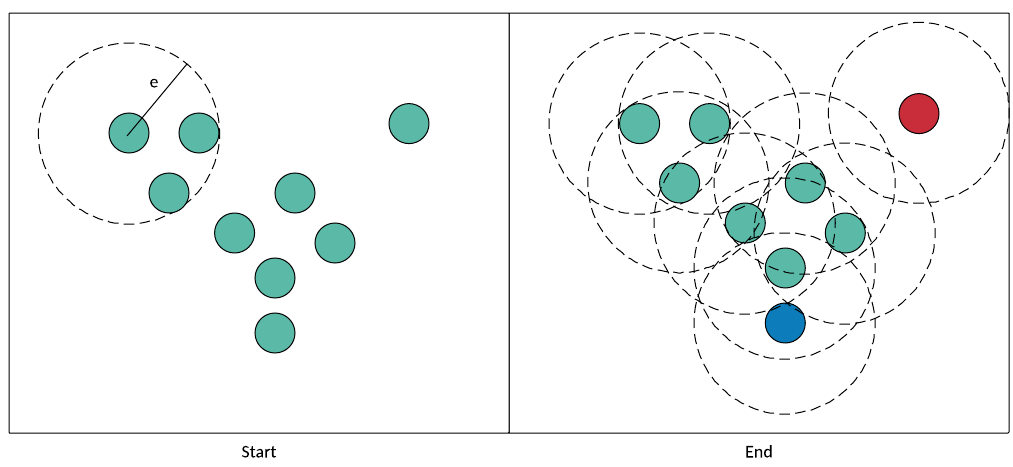
讓我們在圖 2 的上下文中看看此流程。首先在左圖中(名為 Start),我挑選了一個點并檢查它的鄰近點。如果 MINPTS == 2,我的點滿足此條件并被添加到集群中。我們添加了兩個鄰近(密度可達)點用于測試,并繼續執行該流程。只要每個點在 epsilon 距離內至少有兩個鄰近點,它們就會被添加到集群中并稱為核心點)。密度可達但本身不滿足密度標準的點是非核心點(例如藍色的點)。該算法在右側結束(名為 End)。綠色的點(核心點)和藍色的點(非核心點,但密度可達)都包含在集群中。右上角的紅色點是異常值,被視為噪聲。
圖 2. 完整的 DBSCAN 流程
接下來,我將介紹 DBSCAN 實現的核心。
DBSCAN 實現
可以在 GitHub 上找到這個 DBSCAN 實現。現在我們探討一下實現該算法的核心的兩個關鍵函數。剩余函數處理距離計算和鄰近點內存管理。
dbscan 函數(參見清單 4)實現了聚類算法的外部循環。它迭代數據集,確定觀察值是否滿足密度函數(epsilon 距離內的 MINPTS 觀察值)。如果不滿足,則將該觀察值標為噪聲;否則,會創建一個集群并處理它的鄰近點。
清單 4. 主 dbscan 函數
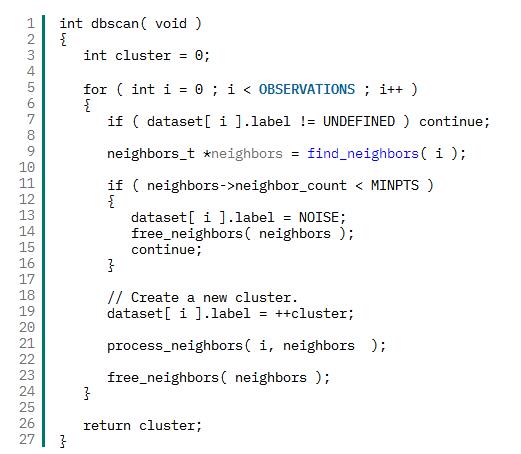
process_neighbor 函數(參見清單 5)圍繞一個滿足密度限制的點構建一個集群。它迭代鄰近點列表(稱為種子集),查看它們是否在當前集群內。以前定義為噪聲的觀察值會被加載到該集群中,已加載到該集群中的觀察值會被忽略。然后檢查當前(未被忽略的)觀察值的鄰近點;此觀察值的所有(滿足此條件的)鄰近點都會加載到種子集中,以針對此集群進行檢查。這個過程會一直持續到沒有新觀察值被加載到種子集中,并且種子集中的所有觀察值都已檢查。返回時,dbscan 函數會挑選下一個觀察值并繼續執行該流程(可能添加新的集群)。
清單 5. 密度可達點之后的 process_neighbor 函數

在不到 50 行的核心 C 代碼中,我創建了一個簡單的聚類解決方案,它與更傳統的方法相比具有明顯優勢。考慮使用前面的動物園數據集的 DBSCAN:必須調整 DBSCAN 來選擇正確的 MINPTS 和 epsilon。在這個示例中,我選擇了 epsilon = 1.7 和 MINPTS = 4。通過這些參數,DBSCAN 創建了 6 個類,14 個觀察值是噪聲,整體準確率為 74%。它***地對鳥和魚的類別進行了聚類,但將哺乳動物集群拆分為一個大型集群和一個小型集群。
使用前面的測試案例,它將“flea with teeth”和“six-legged aquatic egg layer”都劃分到昆蟲類別中,將“predator with hair”劃分為噪聲。調整 epsilon 距離和 MINPTS 參數可以提高此數據集的準確率。
結束語
預測和分類是機器學習的兩個有許多應用的重要方面。從預測消費者的行為(基于他們對類似消費者的分類)到預測保險政策的風險(基于描述政策和申請者的特征),通過分類進行預測是一個真實的機器學習應用示例。