我們教電腦識別視頻字幕
麻文華,博士畢業于中國科學院自動化研究所模式識別與人工智能專業。主要從事圖像識別、目標檢測跟蹤等理論和應用研究,在領域內重要學術會議、期刊上發表論文4篇,申請相關專利2項。工作期間曾從事OCR、自然場景OCR應用研究,提出基于文字背景區域檢測和自適應分級聚類的文字檢測方法,研究成果申請美國專利2項,日本專利2項,中國專利5項。目前主要從事證件識別、自然場景文本識別等研究工作。
研究背景
隨著便攜式拍攝設備的普及以及自媒體、網絡直播平臺的興起,數字視頻迎來了爆炸式的增長。視頻的有效編目和檢索成為迫在眉睫的需求。然而,視頻來源多種多樣,很多并不具備規范化的描述信息(比如字幕文件)。基于純粹的圖像識別技術理解視頻內容需要跨越 圖像到語義理解的鴻溝,目前的技術尚不完善。另一方面,視頻中的字幕往往攜帶了非常精準關鍵的描述信息,從識別字幕的角度去理解視頻內容成為了相對可行的途徑。
識別字幕文本通常需要兩個步驟:字幕定位、文本識別。
字幕定位,即找出字幕在視頻幀中所處的位置,通常字幕呈水平或豎直排列,定位的結果可以采用最小外接框來表示,如圖1所示。字幕文本識別,即通過提取字幕區域的圖像特征,識別其中的文字,最終輸出文本串。
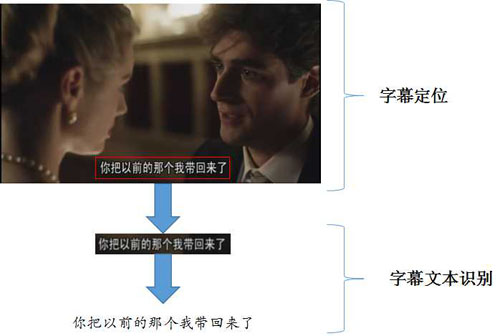
圖1:視頻字幕識別的一般流程
技術路線
字幕定位
字幕定位需要區分字幕區域和背景區域,有效的區分特征包括以下幾點:
- 字幕的顏色、字體較為規整,且與背景有較為明顯的顏色差異;
- 字幕區域的筆畫豐富,角點和邊緣特征比較明顯;
- 字幕中字符間距固定,排版多沿水平或豎直方向;
- 同一視頻中字幕出現的位置較為固定,且同一段字幕一般會停留若干秒的時間。
這其中,前三點是字幕外觀特征,第四點是時間冗余性的特征。利用這些特征,一種可行的字幕定位方案如下:

圖2:基于邊緣密度的字幕定位
首先,對于視頻幀灰度圖像進行邊緣檢測,得到邊緣圖。
然后,在邊緣圖上分別進行水平和豎直方向的投影分析,通過投影直方圖的分布,大致確定字幕的候選區域。如果存在多個候選區域,則根據字幕區域的尺寸和寬高比范圍濾除不合理的檢測結果。最后,通過多幀檢測結果對比融合,進一步去除不穩定的檢測區域。這樣,基本可以得到可信的檢測結果。
在某些復雜場景下,上述方法檢測的區域可能會存在字幕邊界檢測不準的情況,尤其是垂直與字幕方向的兩端邊界。這時,可以進一步借助連通域分析的方法,求出字幕所在行區域的連通域,通過連通域的顏色、排列規整性來微調檢測結果。
字幕文本識別
字幕文本識別通常采用的方法是首先根據行區域內的灰度直方圖投影,切分單字區域,然后針對每個單字區域進行灰度圖像歸一化、提取梯度特征、多模版匹配和MCE(最小分類誤差)分類。然而這種傳統的基于特征工程的分類識別方法難以應對背景紋理復雜,以及視頻本身的噪聲和低分辨率等問題。
一種改進的思路是采用基于深度學習的端到端的串識別方案:CRNN (Convolutional Recurrent Neural Network)。其方法流程如圖3所示:
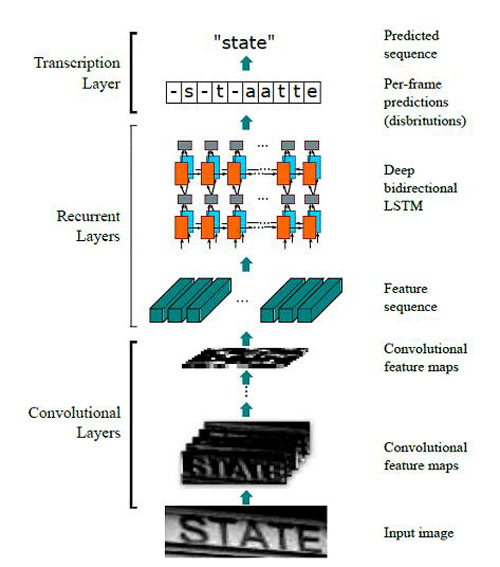
圖3:CRNN實現end-to-end word recognition
首先,輸入高度固定、寬度不限的單詞圖像(無需單字區域信息),在訓練過程中,將圖像統一歸一化到32*100;
然后,通過CNN層提取圖像特征,利用Map-to-Sequence形成特征向量,輸出![]() 為的feature map。這里,
為的feature map。這里,![]() 和
和![]() 與輸入圖像的尺寸成比例相關。論文中,feature map的尺寸為:
與輸入圖像的尺寸成比例相關。論文中,feature map的尺寸為:
![]() 。這相當于對圖像進行了過切分,將其劃分為26個條狀區域,每個區域用512維的特征來表示。其中,26被認為是英文單詞的長度上限。值得一提的是,由于卷積性質,這里的條狀區域是“軟邊界”且存在交疊的,其寬度對應最后一層卷積的感受野。
。這相當于對圖像進行了過切分,將其劃分為26個條狀區域,每個區域用512維的特征來表示。其中,26被認為是英文單詞的長度上限。值得一提的是,由于卷積性質,這里的條狀區域是“軟邊界”且存在交疊的,其寬度對應最后一層卷積的感受野。
接著,通過RNN層提取條狀區域的上下文特征,得到類別概率分布。這里采用的是雙層雙向的LSTM,LSTM的單元個數與![]() 一致。RNN的輸出為
一致。RNN的輸出為![]() 的概率矩陣,其中,
的概率矩陣,其中,![]() 對應于類別個數,考慮26個英文字母+10個數字+1個負類(對應于字母之間的模糊地帶),類別個數取37即可。
對應于類別個數,考慮26個英文字母+10個數字+1個負類(對應于字母之間的模糊地帶),類別個數取37即可。
最后,通過CTC層將概率矩陣轉化為對應某個字符串的概率輸出。CTC層本身沒有參數,它利用一種前向后向算法求解最優的label序列,使得理論上龐大的窮舉計算成為可能。
從上面的分析可以看出,CRNN的亮點主要在于:將切分和識別合并為一個模塊,避免了誤差累積;可以端到端訓練。在我們前期的實踐中,發現其性能比傳統方法的確有明顯提升,主要表現為對于藝術字體、手寫字體等切分困難情況優異的識別性能。但是,針對實際應用場景的分析讓我們最終放棄了這個方案,原因有二:
時效:基于我們在英文單詞上面的實驗對比,CRNN的耗時約為傳統方法的2~3倍,不能滿足視頻處理的實時性要求;
性能:CRNN擅長處理難以切分的字符串,而字幕文本間距和字體均較為規整,很少出現字間粘連的情況,所以并不能體現CRNN的優勢。
綜上考慮,我們最終采用筆畫響應加投影統計方法進行切分,而在單字識別環節采用CNN,提升復雜場景下的識別性能。下面簡單介紹該流程:
切分環節包括三個步驟:
- 求取字幕區域圖像的筆畫響應圖;
- 統計筆畫響應圖水平方向的灰度投影直方圖;
- 根據字幕區域的高度預估單個字符的寬度,并以此為依據,在投影直方圖上尋找一系列最優切點。

圖4:字幕區域的切分
切分環節給出了單個字符區域,針對該區域,采用CNN模型提取特征來進行單字識別。這里需要考慮兩點:
模型選擇:經過實驗,包含3~5層卷積-池化單元的簡單CNN模型即可將傳統識別方法的性能提高10個百分點左右。當然,層次更深的網絡,如resnet,會進一步提升性能。實用場景下,模型選擇需要根據需求在速度和性能之間進行權衡。
數據來源:基于深度學習的方法,性能關鍵在于海量可靠的訓練樣本集。在訓練過程中,我們采用的樣本集在百萬量級,而這些樣本僅靠人工搜集和標注顯然是不現實的。所以,在深度學習的多次應用中,我們均采用了合成樣本訓練,實際樣本驗證的模式,并證明了其可行性。
以合成字幕文本為例:我們通過分析字幕文件的格式,將待生成的文本寫入字幕文件,通過播放視頻時自動載入字幕,將文字疊加到視頻上面。這樣,可以同時完成數據的生成和標注。我們還根據需要定制了不同字體,添加了陰影、模糊等附加效果。這樣,理論上我們就可以得到無限多的合成樣本了。

圖5:字幕文字樣本的合成
雖然識別模塊的性能強悍,但是對于形似字難免仍然存在識別錯誤的情況。這時就要發揮語言模型的威力了。語言模型又稱為n-gram模型,通過統計詞庫中字的同現概率,可以確定哪個字序列出現的可能性更大。N-gram中的n代表統計的詞(字)序列的長度,n越大,模型越復雜。在字幕識別系統中,我們用了最簡單的2-gram模型,將最終的識別正確率又提升了2個百分點。

圖6:基于語言模型的結果校正
小結
我們采用上述系統在實際視頻樣本上進行測試,單字識別準確率達到99%,CPU上單字識別耗時2ms,基本達到實用需求。作為對于深度學習方法應用在實際業務中的一次粗淺嘗試,我們有兩點心得:
關于方法選擇,要從問題出發,具體分析難點在哪里,選擇最簡單有效的方法,避免貪大求新,本末倒置;
關于數據合成,合成數據用于訓練,實際數據用于微調和測試,可謂是訓練深度學習網絡性價比最高的方式。當然,不需要考慮時間人力消耗的土豪隨意。在操作過程中,一定要注意保持合成樣本和實際樣本盡量相似,可以采用多次驗證調整,選擇最佳的合成方法。
原文鏈接:http://t.cn/R0w2Z6L
作者:麻文華
【本文是51CTO專欄作者“騰訊云技術社區”的原創稿件,轉載請通過51CTO聯系原作者獲取授權】