













如何用深度學習訓練一個像你一樣會聊天的機器人?
聊天機器人到底是什么呢?說白了,就是計算機程序通過聽覺或文本方法進行對話。當今最流行的四個對話機器人是:蘋果的Siri、微軟Cortana、谷歌助理、亞馬遜的Alexa。他們能夠幫你查比分、打電話,當然,偶爾他們也會出錯。
本文主要會詳細介紹聊天機器人在文本方面的運作,我們將看到如何使用深度學習模型訓練聊天機器人用我們所希望的方式在社交媒體上進行對話。
意圖&深度學習
如何訓練一個高水平的聊天機器人呢?
高水平的工作聊天機器人是應當對任何給定的消息給予最佳反饋。這種“最好”的反應應該滿足以下要求:
- 回答對方問題
- 反饋相關信息
- 問后續問題或用現實方法繼續對話
這三個方面是機器人表現出來的內容,而隱含其中沒有表現出來的則是一系列流程:理解發送者的意圖,確定反饋信息的類型(問一個后續問題,或者直接反應等),并遵循正確的語法和詞法規則。
請注意,“意圖”二字至關重要。只有明確意圖,才能保證在后續流程的順利進行。對于“意圖”,讀者通過本篇文章,將會看到,深度學習是最有效的解決“意圖”問題的方法之一。
深度學習的方法
聊天機器人使用的深度學習模型幾乎都是 Seq2Seq。2014年,Ilya Sutskever, Oriol Vinyals, and Quoc Le 發表了《Sequence to Sequence Learning with Neural Networks》一文。摘要顯示,盡管機器翻譯已經做的很好,但Seq2Seq卻模型能更好的完成各種各樣的NLP的任務。

Seq2Seq模型由兩個主要部件組成,一個是編碼器RNN,另一個是解碼器RNN。從高層次上來說,編碼器的工作是將輸入文本信息生成固定的表示。解碼器則是接收這個表示,并生成一個可變長度的文本,以響應它。
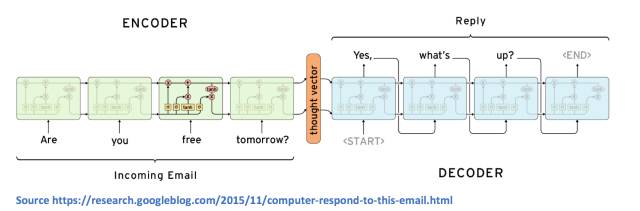
讓我們來看看它是如何在更詳細的層次上工作的。正如我們所熟知的,編碼器RNN包含了許多隱藏的狀態向量,它們每個都表示從上一次時間步驟中獲取的信息。例如,在第3步序中的隱藏狀態向量是前三個單詞的函數。通過這個邏輯,編碼器RNN的最終隱藏狀態向量可以被認為是對整個輸入文本的一種相當精確的表示。
而解碼器RNN負責接收編碼器的最后隱藏狀態向量,并使用它來預測輸出應答的單詞。讓我們看看第一個單元。該單元的工作是使用向量表示v,并決定其詞匯表中哪個單詞是最適合輸出響應的。從數學上講,這就意味著我們計算詞匯中的每一個單詞的概率,并選擇值的極大似然。
第二單元是向量表示v的函數,也是先前單元的輸出。LSTM的目標是估計以下條件概率。
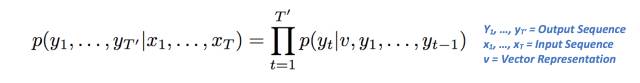
讓我們來解構這個方程式意味著什么。
左側指的是輸出序列的概率,這取決于給定輸入序列。右側包含p(yt | v,y1,…,yt),它是所有單詞的概率向量,條件是在前一步的向量表示和輸出的情況下。其中pi等價于西格瑪(或累計求和)的乘法。則右側可降為p(Y1 | V)*p(y2 | v,y1)*p(Y3 | v,y1,y2)。
在繼續之前,讓我們先做一個簡單的例子。讓我們在第一張圖片中輸入文本:“你明天有空嗎?”大多數人都會怎么回答呢?一般都會用“yes”、“yeah”、“no”開始。
在我們完成了網絡訓練之后,概率p(Y1 | V)將是一個類似于下面的分布。

再來看我們需要計算的第二個概率,p(y2 | v,y1)表是一個函數,詞的分布y1以及向量的表示結果v,而pi將產生最終結果并作為我們的最終反應。
Seq2Seq模型的最重要特性之一是它提供的多功能性。當你想到傳統的ML方法(線性回歸,支持向量機)和深等深學習方法時,這些模型需要一個固定的大小輸入,并產生固定大小的輸出。但是輸入的長度必須事先知道。這是對諸如機器翻譯、語音識別和問答等任務的一個很大的限制。這些任務我們都不知道輸入短語的大小,我們也希望能夠生成可變長度響應,而不僅僅局限于一個特定的輸出表示。而Seq2Seq模型允許這樣的靈活性!
自2014以來,Seq2Seq模型已經有了很多改進,你可以在這篇文章結尾“相關論文”部分中閱讀更多關于Seq2Seq的文章。
數據集的選擇
在考慮將機器學習應用于任何類型的任務時,我們需要做的第一件事都是選擇數據集,并對我們需要的模型進行訓練。對于序列模型,我們需要大量的會話日志。從高層次上講,這個編碼器-解碼器網絡需要能夠正確理解每個查詢(編碼器輸入)所期望的響應類型(解碼器輸出)。一些常見的數據集包括:康奈爾電影對話語料庫、ubuntu語料庫和微軟的社交媒體對話語料庫。
雖然大多數人都在訓練聊天機器人來回答具體信息或提供某種服務,但我更感興趣的是更多的有趣的應用程序。有了這篇文章,我想看看我是否可以用我自己的生活中的對話日志來訓練一個Seq2Seq的模型來學習對信息的反應。
獲取數據

我們需要創建一個大量的對話數據,在我的社交媒體上,我使用了Facebook、Google Hangouts、SMS、Linkedin、Twitter、Tinder和Slack 等著與人們保持聯系。
- Facebook:這是大部分培訓數據的來源。facebook有一個很酷的功能,讓你可以下載你所有的Facebook數據。包含所有的信息、照片、歷史信息。
- Hangouts:您可以根據這個文章的指示來提取聊天數據。
- SMS:可以快速獲得所有之前的聊天記錄(sms備份+是一個不錯的應用程序),但我很少使用短信。
- Linkedin:Linkedin確實提供了一種工具,可以在這里獲取數據的歸檔。
- Twitter:這其中沒有足夠的私人信息。
- Tinder:這其中的對話不是數據集。
- Slack:我的Slack剛剛開始使用,只有幾個私有消息,計劃手動復制。
創建數據集
數據集的創建是機器學習的一個重要組成部分,它涉及到數據集預處理。這些源數據存檔格式不同,并且包含我們不需要的部分(例如,fb數據的圖片部分)。
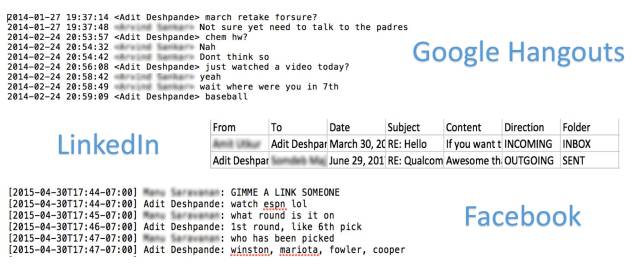
正如您所看到的,Hangouts數據的格式與facebook數據有一點不同,而linkedin的消息以csv格式進行。我們的目標是使用所有這些數據集來創建一個統一的文件,命名為(FRIENDS_MESSAGE,YOUR_RESPONSE)。
為了做到這一點,我編寫了一個python腳本,可以在這里查看。此腳本將創建兩個不同的文件。其中一個是Numpy對象(conversationDictionary.npy)包含所有輸入輸出對。另一個是一個大的txt文件(conversationData.txt)包含這些輸入輸出對的句子形式,一個對應一個。通常,我喜歡共享數據集,但是對于這個特定的數據集,我會保持私有,因為它有大量的私人對話。這是最后一個數據集的快照。

詞向量
LOL,WTF,這些都是在我們的會話數據文件中經常出現的所有單詞。雖然它們在社交媒體領域很常見,但它們并不是在很多傳統的數據集中。通常情況下,我在接近NLP任務時的第一個直覺是簡單地使用預先訓練的向量,因為它們能在大型主體上進行大量迭代的訓練。然而,由于我們有這么多的單詞和縮寫,而不是在典型的預先訓練的單詞向量列表中,因此,生成我們自己的單詞向量對于確保單詞正確表達是至關重要的。
為了生成單詞向量,我們使用了word2vec模型的經典方法。其基本思想是,通過觀察句子中單詞出現的上下文,該模型會創建單詞向量。在向量空間中,具有相似上下文的單詞將被置于緊密的位置。關于如何創建和訓練word2vec模型的更詳細的概述,請查看我的一個好友Varma羅漢的博客。
我后來了解到TensorFlow Seq2Seq函數從零開始對單詞embeddings進行訓練,因此我不會使用這些單詞向量,盡管它們仍然是很好的實踐。
用TensorFlow創建Seq2Seq模型
現在我們創建了數據集并生成了我們的單詞向量,我們就可以繼續編碼Seq2Seq模型了。我在python腳本中創建和訓練了模型,我試著對代碼進行評論,希望你能跟著一起。該模型的關鍵在于TensorFlow的嵌入_RNN_seq2seq()函數。你可以在這里找到文檔。
跟蹤培訓進展
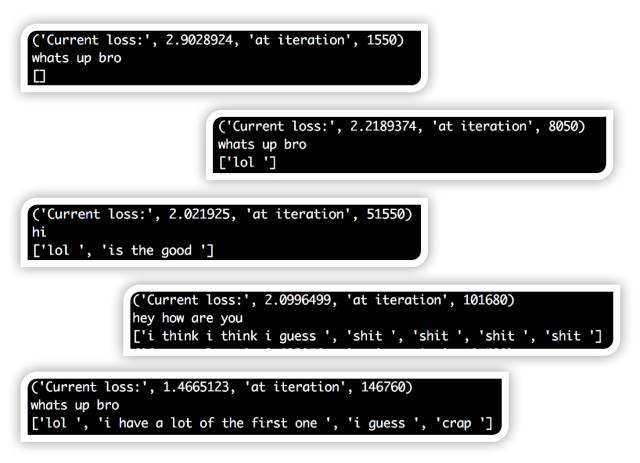
這個項目的一個有趣的地方是,能看到網絡訓練時,響應是如何發生變化的。訓練回路中,我在輸入字符串上測試了網絡,并輸出了所有非pad和非eos口令。
首先,您可以看到,響應主要是空白,因為網絡重復輸出填充和eos口令。這是正常的,因為填充口令是整個數據集中最常見的口令。然后,您可以看到,網絡開始輸出“哈哈”的每一個輸入字符串。這在直覺上是有道理的,因為“哈哈”經常被使用,它是對任何事情都可以接受的反應。慢慢地,你開始看到更完整的思想和語法結構在反應中出現。現在,如果我們有一個經過適當訓練的Seq2Seq模型,那么就可以建立facebook messenger聊天機器人。
如何建立一個簡單的fb messenger聊天機器人
這個過程并不是太難,因為我花了不到30分鐘的時間來完成所有步驟。基本的想法是,我們使用簡單的express應用程序建立了一個服務器,在Heroku上安裝它,然后設置一個facebook頁面連接。但最終,你應該有一個類似這樣的 Facebook 聊天應用程序。
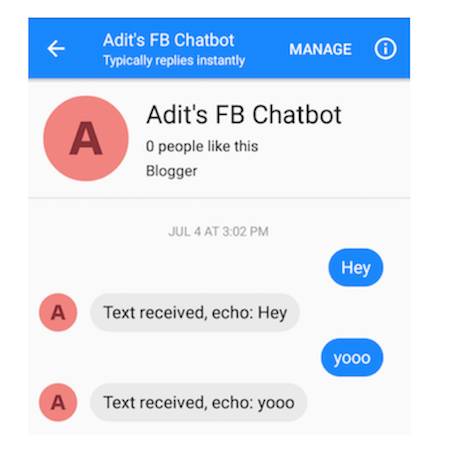
您可以向您的聊天機器人發送消息(這種初始行為只是響應它所發送的所有內容)。
部署訓練有素的TensorFlow模型
現在是時候把一切都放在一起了。由于tensorflow和node之間還沒有找到一個很好的接口(不知道是否有一個官方支持的包裝器),所以我決定使用slack服務器部署我的模型,并讓聊天機器人的表達與它進行交互。您可以在這里查看slack服務器代碼以及聊天機器人的index.js文件。
測試它!
如果你想和這個機器人聊天,那就繼續點擊這個鏈接或者點擊facebook頁面,發送消息。第一次響應可能需要一段時間,因為服務器需要啟動。
也許很難判斷機器人是否真的像我那樣說話(因為沒有很多人在網上和我聊天),但是它做的很好!考慮到社會媒體標準,語法是可以通過的。你可以選擇一些好的結果,但大多數都是相當荒謬的。這能幫助我在晚上睡得更好的,畢竟不能在任何時間用skynet。
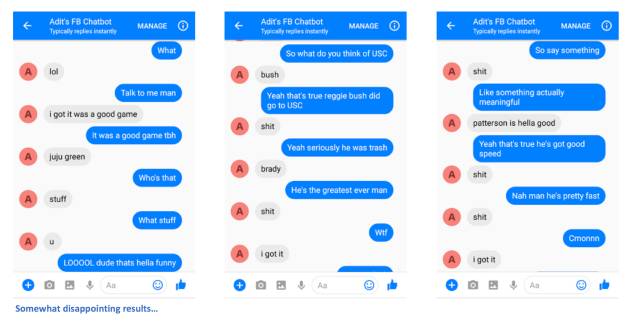
我認為第一個是特別有趣的,因為“juju green”實際上似乎是一種 Juju Smith-Schuster,鋼人隊寬接收器,和 Draymond Green,前鋒金州勇士。有趣的組合。
雖然現在的表現還不太好。讓我們來考慮一下改善它的方法吧!
改進方法
從與chatbot的交互中可以看到的改進方法,有很大的改進空間。經過幾條信息后,很快就會明白,不僅僅是進行持續的對話就行了。chabtot不能夠把思想聯系在一起,而一些反應似乎是隨機的、不連貫的。下面是一些可以提高我們聊天機器人性能的方法。
- 合并其他數據集,以幫助網絡從更大的會話語料庫中學習。這將消除聊天機器人的“個人特性”,因為它現在已經被嚴格訓練了。然而,我相信這將有助于產生更現實的對話。
- 處理編碼器消息與解碼器消息無關的場景。例如,當一個對話結束時,你第二天就開始一個新的對話。談話的話題可能完全無關。這可能會影響模型的訓練。
- 使用雙向LSTMs,注意機制和套接。
- 優化超參數,如LSTM單元的數量、LSTM層的數量、優化器的選擇、訓練迭代次數等。
你如何建立像你一樣的聊天機器人,流程回顧
如果你一直在跟進,你應該對創建一個聊天機器人所需要的東西已經有了一個大致的概念。讓我們再看一遍最后的步驟。在GitHub repo中有詳細的說明。
- 找到所有你與某人交談過的社交媒體網站,并下載你的數據副本。
- 從CreateDataset中提取所有(消息、響應)對py或您自己的腳本。
- (可選)通過Word2Vec.py為每一個在我們的對話中出現的單詞 生成單詞向量。
- 在Seq2Seq.py中創建、訓練和保存序列模型。
- 創建Facebook聊天機器人。
- 創建一個Flask服務器,在其中部署保存的Seq2Seq模型。
- 編輯索引文件,并與Flask服務器通信。



















