













為模型減減肥:談談移動/嵌入式端的深度學習
1. 為什么要為深度學習模型減肥
隨著深度學習的發展,神經網絡模型也越來越復雜,常用的模型中 VGG 系列網絡的計算量可以達到 30-40 GOP(1GOP=109 運算)。這些神經網絡通常運行在 GPU 上,但是如果我們要在移動/嵌入式端也實現深度學習,那么這樣巨大的模型是絕對跑不動的。移動/嵌入式端的計算能力往往只有桌面級 GPU 的 1/100 到 1/1000,換句話說在 GPU 上一秒 40 幀的深度學習 CV 算法在移動/嵌入式端一秒只有 0.04-0.4 幀,這樣的性能會極大影響用戶體驗。

常用深度學習網絡運算量
在移動/嵌入式端跑深度學習模型,除了運行速度之外,能效比(energy efficiency)也是關鍵指標。能效比指的是一次運算所需消耗的能量,它決定了移動/嵌入式端運行深度學習算法時電池能用多久。能效比與深度學習模型息息相關,我們下面將會看到深度學習模型的大小會決定運行算法時的片外內存訪問頻率,從而決定了能效比。
2. 怎樣的模型才能算「身材苗條」?
正如我們減肥不僅要看體重還要看體脂率一樣,為深度學習模型「減肥」時不僅要看模型計算量還要看模型大小。
模型計算量是衡量深度學習是否適合在移動或嵌入式端計算的最重要指標,通常用 GOP 單位來表示。例如,流行的 ResNet-18 的計算量大約是 4 GOP,而 VGG-16 則為大約 31 GOP。移動和嵌入式端的硬件計算能力有限,因此模型所需的計算量越大,則模型在移動端運行所需要的時間就越長。為了能讓使用深度學習的應用順暢運行,模型運算量當然是越小越好。除此之外,深度學習每次運算都是需要花費能量的,模型運算量越大則完成一次 inference 需要的能量也就越大,換句話說就是越費電。在電池量有限的移動和嵌入式端,模型一次 inference 所花費的能量必須精打細算,因此深度學習模型計算量不能太大。
如果說計算量對模型來說是最簡單直接的「體重」的話,那么模型大小就是略微有些復雜和微妙的「體脂率」。深度學習模型大小主要決定的是該模型做一次 inference 所需要的能量。那么模型大小與 inference 所消耗的能量有什么關系呢?首先,我們知道,深度學習模型必須儲存在內存里面,而內存其實還分為片上內存和片外內存兩種。片上內存就是 SRAM cache,是處理器集成在芯片上用來快速存取重要數據的內存模塊。片上內存會占據寶貴的芯片面積,因此處理器中集成的片上內存大小通常在 1-10 MB 這個數量級。片外內存則是主板上的 DDR 內存,這種內存可以做到容量很大(>1 GB),但是其訪問速度較慢。

片上內存,離處理器核心電路很近,因此訪問消費的能量很小

片外內存,離處理器很遠,一次訪問需要消耗很大能量
更關鍵的是,訪問片外內存所需要的能量是巨大的。根據 Song Han 在論文中的估計,一次片外內存訪問消耗的能量是一次乘-加法運算的 200 倍,同時也是一次訪問片上內存所需能量的 128 倍。換句話說,一次片外內存訪問相當于做 200 次乘法運算!
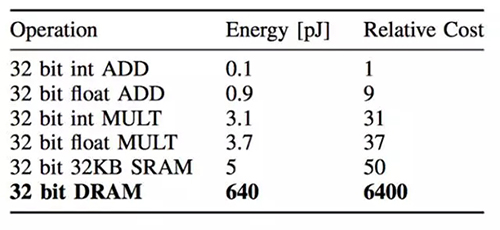
當然,具體程序中運算和內存訪問消耗的能量取決于多少次運算需要一次內存存取。嚴格的分析方法是 roof-line model,不過我們也可以從 Google 公布的數據中去估算深度學習模型中運算次數和內存訪問次數的比例。Google 在 TPU 的論文中公布了這個數據,從中可見 LSTM 模型內存訪問頻率***,平均 64 或 96 次計算就需要訪問一次內存去取權重(weight)數據;而 CNN 模型的內存訪問頻率相對***,平均 2888 或 1750 次運算才訪問一次內存取權重。這也很好理解,因為 CNN 充分利用了局部特征(local feature),其權重數據存在大量復用。再根據之前的計算和內存訪問能量數據,如果所有的權重數據都存儲在片外內存,那么兩個 CNN 模型計算時運算和內存訪問消耗的能量比是 2:1 和 2.5:1,而在 LSTM0 和 LSTM1 模型計算時運算和內存訪問消耗的能量比是 1:10 和 1:7!也就是說在 LSTM 模型做 inference 的時候,內存訪問消耗的能量占了絕大部份!
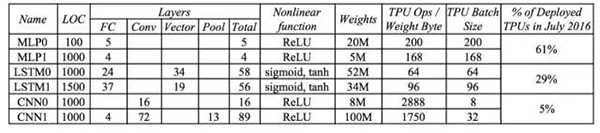
因此,我們為了減小能量消耗,必須減少片外內存訪問,或者說我們需要盡可能把模型的權重數據和每層的中間運算結果存儲在片上內存而非片外內存。這也是為什么 Google TPU 使用了高達 28MB 片上內存的原因。然而,移動端和嵌入式系統使用的芯片不能成本太高,因此片上內存容量很有限。這樣的話我們就必須從深度學習模型大小方面想辦法,盡量減小模型尺寸,讓模型盡可能地能存儲在片上內存,或者至少一層網絡的權重數據可以存在片上內存。
3. 為模型減肥的幾種方法
2016 年可謂是深度學習模型減肥元年,那一年大家在被深度學習的潛力深深折服的同時開始認真考慮如何在移動硬件上跑深度學習,于是 MIT 的 Viviene Sze 發表了***款深度學習加速芯片 Eyeriss,Bengio 發表了 Binarized Network,Rastegari 提出了 XOR-Net,Song Han 也發表了 Deep Compression,可謂是百花齊放。為模型減肥的方法可以分為兩大類:***類是大幅調整模型結構(包括網絡拓撲連接,運算等等),直接訓練出一個結構比較苗條的模型;第二類是在已有模型的基礎上小幅修改,通常不涉及重新訓練(模型壓縮)。
Bengio 的 Binarized Neural Network 可謂是***類模型的先驅者,將神經元 activation 限制為-1 或 1,從而極大地降低了運算量。Google 也于一個多月前發表的 MobileNet,使用了 depth-wise convolution 來降低運算量以及模型大小。Depthwise convolution 能大幅降低運算量,但是同時不同特征之間的權重參數變成線性相關。理論上減小了自由度,但是由于深度學習網絡本身就存在冗余,因此實際測試中性能并沒有降低很多。MobileNet 的計算量僅為 1GOP 上下,而模型大小只有 4MB 多一些,但能在 ImageNet 上實現 90% 左右的 top-5 準確率。在這條路上努力的人也很多,前不久 Face++也發表了 ShuffleNet,作為 MobileNet 的進一步進化形式也取得了更小尺寸的模型。未來我們預期會有更多此類網絡誕生。

Google MobileNet 的幾種模型,模型運算量大幅降低的同時 top-5 準確率降低并不多。圖中 1MAC=2OP
第二種方法則是保持原有模型的大體架構,但是通過種種方法進行壓縮而不用重新訓練,即模型壓縮。一種思路就是在數據編碼上想辦法。大家都知道數據在計算機系統中以二進制形式表示,傳統的全精度 32-bit 浮點數可以覆蓋非常大的數字范圍,但是也很占內存,同時運算時硬件資源開銷也大。實際上在深度學習運算中可能用不上這么高的精度,所以最簡單直接的方法就是降低精度,把原來 32-bit 浮點數計算換成 16-bit 浮點數甚至 8-bit 定點數。一方面,把數據的位長減小可以大大減少模型所需的存儲空間(1KB 可以存儲 256 個 32-bit 浮點數,但可以存儲 1024 個 8-bit 定點數),另一方面低精度的運算單元硬件實現更簡單,也能跑得更快。當然,隨著數據精度下降模型準確率也會隨之下降,所以隨之也產生了許多優化策略,比如說優化編碼(原本的定點數是線性編碼數字之間的間距相等,但是可以使用非線性編碼在數字集中的地方使數字間的間距變小增加精度,而在數字較稀疏的地方使數字間距較大。非線性編碼的方法在數字通訊重要已經有數十年的應用,8-bit 非線性編碼在合適的場合可以達到接近 16-bit 線性編碼的精度)等等。業界的大部分人都已經開始使用降低精度的方案,Nvidia 帶頭推廣 16-bit 浮點數以及 8-bit 定點數計算,還推出了 Tensor RT 幫助優化精度。
除了編碼優化之外,另一個方法是網絡修剪(network pruning)。大家知道在深度學習網絡中的神經元往往是有冗余的,不少神經元即使拿掉對精度影響也不大。網絡修建就是這樣的技術,在原有模型的基礎上通過觀察神經元的活躍程度,把不活躍的神經元刪除,從而達到降低模型大小減小運算量的效果。
當然,網絡修剪和編碼優化可以結合起來。Song Han 發表在 2016 年 ICLR 上的 Deep Compression 就同時采用了修剪以及編碼優化的方法,從而實現 35 倍的模型大小壓縮。

Deep Compression 使用的模型壓縮同時使用了網絡修剪和編碼優化
另外,訓練新模型和模型壓縮并不矛盾,完全可以做一個 MobileNet 的壓縮版本,從而進一步改善移動端運行 MobileNet 的速度和能效比。
總結
在移動/嵌入式端運行的深度學習網絡模型必須考慮運行速度以及能效比,因此模型的運算量和模型尺寸大小都是越小越好。我們可以訓練新的網絡拓撲以減小運算量,也可以使用網絡壓縮的辦法改善運行性能,或者同時使用這兩種辦法。針對移動/嵌入式端的深度學習網絡是目前的熱門課題,隨著邊緣計算的逐漸興起預計會有更多精彩的研究出現,讓我們拭目以待。
【本文是51CTO專欄機構“機器之心”的原創文章,微信公眾號“機器之心( id: almosthuman2014)”】


















