













簡要分析Kafka Stream有意思的點
kafka歷史背景
Kafka是2010年Kafka是Linkedin于2010年12月份開源的消息系統,我接觸的不算早,大概14年的時候,可以看看我們14年寫的文章《高速總線kafka介紹》。
消息總線一直是作IT系統集成的核心概念,IBM/oracle等傳統廠商都有相關中間件產品。傳統消息中間件解決是消息的傳輸,一般支持AMQP協議來實現,如RabbitMQ。AMQP的主要特征是面向消息、隊列、路由(包括點對點和發布/訂閱)、可靠性、安全。AMQP協議更多用在企業系統內,對數據一致性、穩定性和可靠性要求很高的場景,對性能和吞吐量的要求還在其次。
Kafka上來劍走偏鋒,追求高吞吐量,所以特別適合,大數據的數據收集和分發等功能。高吞吐的原因核心是kafka的一些獨特的涉及,包括直接使用linux cache/zero-copy/數據存放方法等,這方面的分析很多,我前面的文章《高速總線kafka介紹》第4節也簡單寫了下。Kafka一直缺乏一個商業公司來推動,所以發展并不是很快。幾年過去了,自己看了看,還是0.10版本,特性也發展比較慢。
Kafka一直缺乏一個商業公司來推動,這個問題現在要稍稍改變一些了,原LinkedIn Kafka作者離職后創業Confluent Inc來推動kafka商業化,并推出Kafka Stream。

詳細的設計理念,概念,大家看看slidershare上的PPT,講的比較清楚,不詳細展開了:https://www.slideshare.net/GuozhangWang/introduction-to-kafka-streams。
kafka stream
今天只講kafka stream幾個有意思的點:
1. 首先是定位:
比較成熟度的框架有:Apache Spark, Storm(我們公司開源Jstorm), Flink, Samza 等。第三方有:Google’s DataFlow,AWS Lambda。
1)現有框架的好處是什么?
強大計算能力,例如Spark Streaming上已經包含Graph Compute,MLLib等適合迭代計算庫,在特定場景中非常好用。
2)問題是什么?
A、使用起來比較復雜,例如將業務邏輯遷移到完備的框架中,Spark RDD,Spout等。有一些工作試圖提供SQL等更易使用模式降低了開發門檻,但對于個性化ETL工作(大部分ETL其實是不需要重量級的流計算框架的)需要在SQL中寫UDF,流計算框架就退化為一個純粹的容器或沙箱。
B、作者認為部署Storm,Spark等需要預留集群資源,對開發者也是一種負擔。

Kafka Stream定位是輕量級的流計算類庫,簡單體現在什么方面?
C、所有功能放在Lib中實現,實現的程序不依賴單獨執行環境
D、可以用Mesos,K8S,Yarn和Ladmda等獨立調度執行Binary,試想可以通過Lamdba+Kafka實現一個按需付費、并能彈性擴展的流計算系統,是不是很cool?
E、可以在單、單線程、多線程進行支持
F、在一個編程模型中支持Stateless,Stateful兩種類型計算
編程模型比較簡潔,基于Kafka Consumer Lib,及Key-Affinity特性開發,代碼只要處理執行邏輯就可以,Failover和規模等問題由Kafka本身特性幫助解決。
2. 設計理念和概念抽象
強調簡單化,Partition中的數據到放入消費隊列之前進行一定的邏輯處理(Processor Topology)提供一定的數據處理能力(api),沒有Partition之間的數據交換,實現代碼9K行。
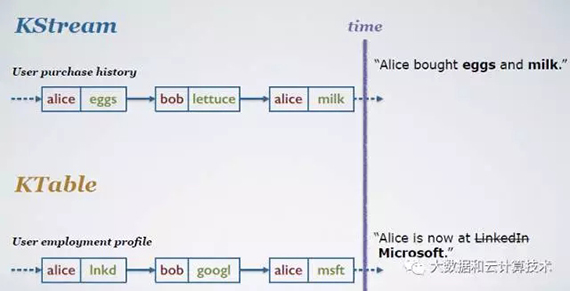
數據抽象分兩種:
1)KStream:data as record stream, KStream為一個insert隊列,新數據不斷增加進來
2)KTable: data as change log stream, KTable為一個update隊列,新數據和已有數據有相同的key,則用新數據覆蓋原來的數據
后面的并發,可靠性,處理能力都是圍繞這個數據抽象來搞。
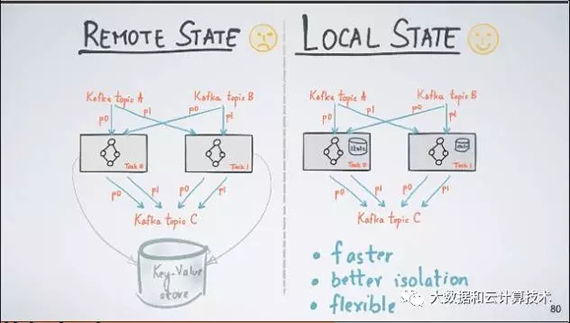
3. 支持兩種處理能力

1)Stateless(無狀態):例如Filter,Map,Joins,這些只要數據流過一遍即可,不依賴于前后的狀態。
2)Stateful(有狀態):主要是基于時間Aggregation,例如某段時間的TopK,UV等,當數據達到計算節點時需要根據內存中狀態計算出數值。
Kafka Streams把這種基于流計算出來的表存儲在一個本地數據庫中(默認是RocksDB,但是你可以plugin其它數據庫)
4. 未來支持exactly once
未來0.11版本會支持exactly once ,這是比較牛逼的能力。(提前預告)
https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
1)at most once: 消費者fetch消息,保存offset,處理消息
消費者處理消息過程中出現意外,消費者恢復之后,將不能恢復處理出錯的消息
2)at least once: 消費者fetch消息,處理消息,保存offset
消費者處理消息過程中出現意外,可以恢復之后再重新讀取offsert處的原來的消息
3)exactly once: 確保消息唯一消費一次,這個是分布式流處理最難的部分。
“processing.guarantee=exactly_once”
這個是怎么實現的,去看看《分布式系統的一致性探討》http://blog.jobbole.com/95618/
和《關于分布式事務、兩階段提交協議、三階提交協議》
http://blog.jobbole.com/95632/。
5. 主要應用場景
kafka的核心應用場景還是輕量級ETL,和flink/storm更多是一個補充作用。
Building a Real-Time Streaming ETL Pipeline in 20 Minutes
https://www.confluent.io/blog/building-real-time-streaming-etl-pipeline-20-minutes/
最后希望kafka在商業公司的推動下有個更大的發展。
【本文為51CTO專欄作者“大數據和云計算”的原創稿件,轉載請通過微信公眾號獲取聯系和授權】



















